Ingesting Data from Relational Databases to Cassandra with StreamSets

Todd McGrath

How do you ingest from an existing relational database (RDBMS) to an Apache Cassandra or DataStax Enterprise cluster?
What about a one-time batch loading of historical data vs. streaming changes?
I know what some of you are thinking, write and deploy some code. And maybe the code can utilize a framework like Apache Spark. That's what I would have thought a few years ago. But, it often turns out that's not as easy as expected.
Don't get me wrong, writing and deploying code makes sense for some folks. But for many others, writing and deploying custom code may require significant time and resources.
Are there any alternatives to custom code for Cassandra ingestion from an RDBMS?
For example, are there any third party tools available which focus on data ingestion? And if so, do they support Cassandra or DataStax Enterprise from an RDBMS?
Yes and Yes with StreamSets.
In this tutorial, we'll explore how you can use the open source StreamSets Data Collector for migrating from an existing RDBMS to DataStax Enterprise or Cassandra.
If this your first time with StreamSets, it's both a browser-based and REST API pipeline designer and execution engine as quickly shown in the following:
We're going to cover both batch and streaming based data ingestion from an RDBMS to Cassandra:
- Use Case 1: Initial Bulk Load of historical RDBMS based data into Cassandra (batch)
- Use Case 2: Change Data Capture (aka CDC) trickle feed from RDBMS to Cassandra to keep Cassandra updated in near real-time (streaming)
Why this matters?
- Migrate to Cassandra more quickly than writing a custom code solution
- Build confidence in your Cassandra data models and operations using real-world data
- Switch-over from an RDBMS based environment to Cassandra with minimum downtown (in fact, no downtime is possible. keep reading.)
- Utilize a tool built for data ingest, so you can focus on your business objectives which rely on Cassandra. You're not in the data ingest business, right? So why build something when you don't have to. Prioritize.
Our Approach
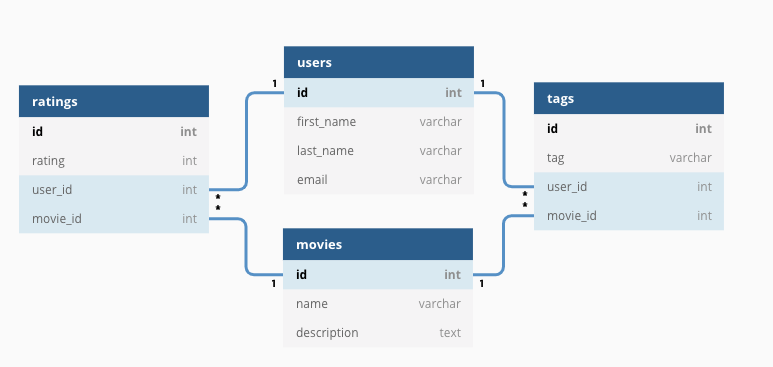
I'm going to riff off the world-famous Killrvideo reference application. (I'm assuming you know KillrVideo! If not, just search for it.) Specifically, we're going to present and solve for a migrating an RDBMS called KillrMovies to Cassandra. KillrMovies is a subset of the KillrVideo schema and will help highlight what we can do if we are migrating to DataStax or Cassandra from an RDBMS and not building something entirely new?
We're leveraging a subset of KillrVideo because it's often used when introducing and teaching data modeling in DataStax and Cassandra. And this especially relevant in this tutorial where we are taking an existing RDBMS based model and migrating to Cassandra.
The KillrMovies RDBMS data model is traditional, 3NF where normalization is paramount.
Conversely, when moving to Cassandra, the data model is based on known queries with denormalized data.

Requirements
- Cassandra or DataStax Enterprise (DSE) (see schema/cassandra_schema.cql file)
- An RDBMS with a JDBC driver such as Oracle, Microsoft SQL Server, PostgreSQL or mySQL (this tutorial uses mySQL)
- StreamSets Data Collector 3.4 or above
Please note: If you are new to StreamSets, you are encouraged to visit http://www.streamsets.com to learn more and complete the Basic Tutorials available at https://streamsets.com/tutorials/ before attempting this tutorial.
Use Case 1 - Bulk Loading Cassandra from RDBMS
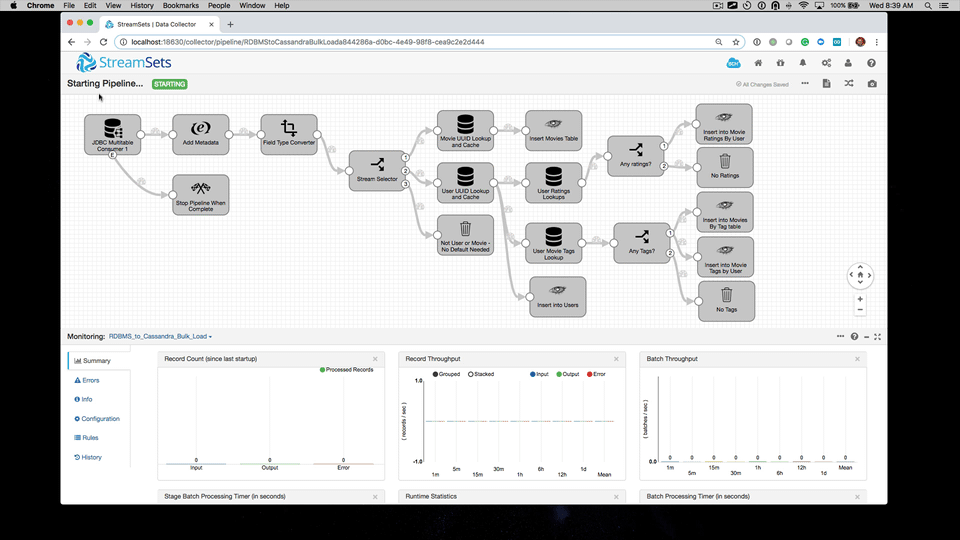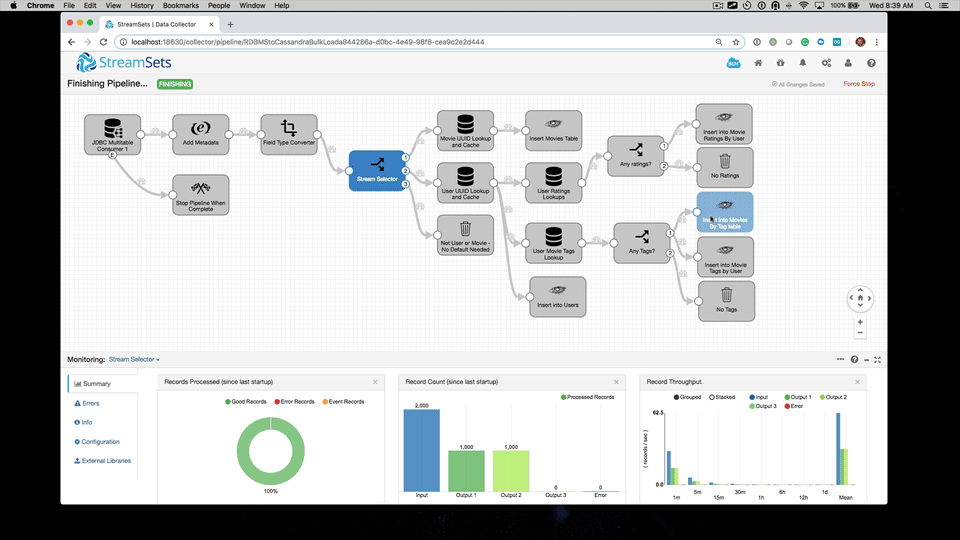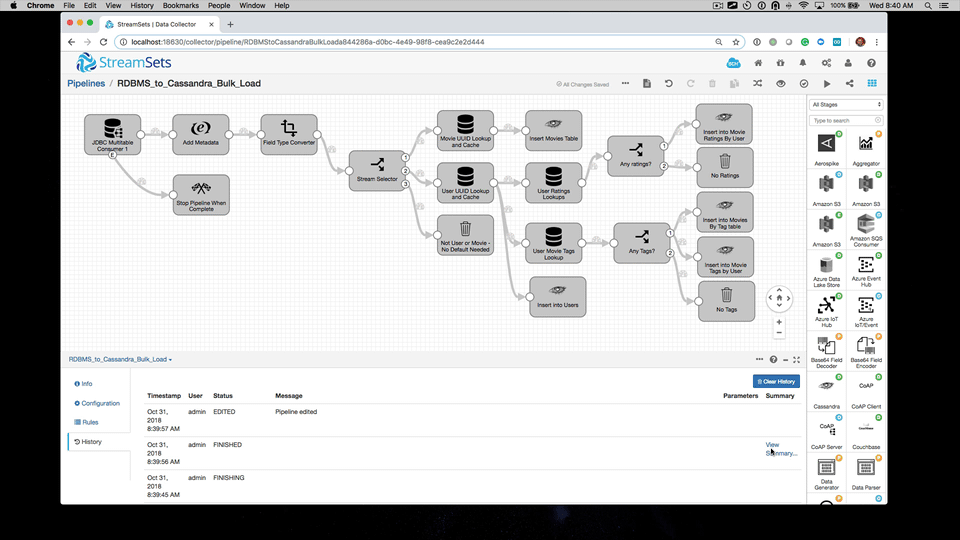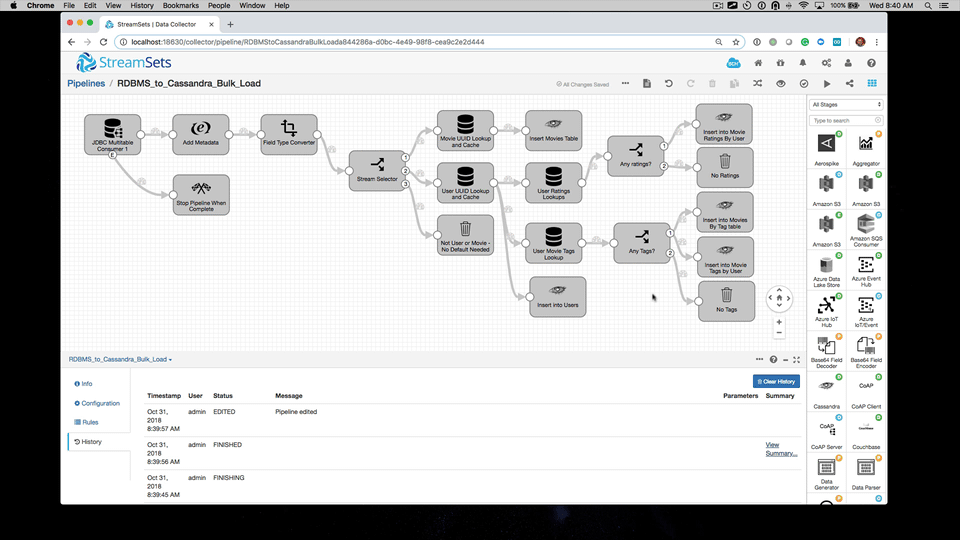
Let's work backward. What does the end result of bulk loading into Cassandra from an RDBMS with StreamSets look like?
In the following screencast, I demonstrate how to run the provided StreamSets bulk load pipeline. Along the way, we'll review the before and after state of the mySQL database and Cassandra.
Key Deliverables
In the demonstration, we saw the ability to move from a data model appropriate for RDBMS to a data model appropriate for Cassandra without writing any code. Instead, we utilized StreamSets configuration as code. That's an important point. StreamSets Data Collector is not a code generator. It is both a design tool and execution engine. As we saw in the pipeline import, pipelines are represented in JSON config.
Bonus Points: did you notice we converted auto-incrementing primary keys in RDBMS to uuid fields in Cassandra? The construct of auto-incrementing primary keys is not typically used with distributed databases due to the potential of gaps in the sequence and performance ramifications if attempting to implement. Auto-incrementing primary keys are not supported in Cassandra.
StreamSets configuration
How should we configure StreamSets for this bulk load use case?
In the following screencast, let’s review the StreamSets configuration for the initial bulk load:
Use Case 2 - Change Data Capture to Cassandra
In databases, change data capture (CDC) is a set of software design patterns used to determine (and track) the data that has changed so that action can be taken using the changed data. [1]
In other words, for this tutorial, a mySQL CDC origin will allow us to identify insert, update or delete mutations in near real-time in order to translate these operations into our Cassandra destination.
StreamSets has many out-of-the-box options for CDC-enabled databases including Oracle, Microsoft SQL Server, Mongo, PostgreSQL and mySQL. [2]
When implementing CDC patterns, you need to make some high-level choices regarding logical vs. physical mutations:
- Do you want to perform logical or physical deletes from origin to destination? This typically depends on the design of the origin database. Is the origin performing physical deletes? Logical deletes are often referred to as "soft deletes", in which a column is updated to indicate if a record has been deleted or not; i.e. a boolean deleted column or an operation_type column indicator.
- Do you want to perform logical or physical updates? When an update happens at the source RDBMS, do you want to update the record in the destination or do you want to write a new record with a logical update? As an example of logical update, you may have a data model with an operation_type column with int value indicators for INSERT, UPDATE or DELETE. An operation_type column is often paired with with a created_at timestamp column. These two columns would allow you to have a running history of updates to a particular entity. (or even deletes if you choose)
You have options. In this tutorial, we’ll implement a logical approach when collecting RDBMS mutations to the Cassandra destination.
In this logical approach, we will retain a history of source mutations. See the FAQ section below for alternatives.
Let's take a look at streaming change data capture to Cassandra in the following screencast:
Key Deliverables
In this second data pipeline example, we showed CDC from mySQL to Cassandra using a streaming pipeline. This is different from the first example which was a one-time batch pipeline. This pipeline is intended to run continuously.
We chose the approach of logical updates and deletes vs. physical.
StreamSets Configuration
Let's review how the streaming change data capture pipeline is configured in the following screencast:
FAQ
Here are a few common questions and their answers:
- What if my RDBMS has too many tables to address in a StreamSets pipeline, or I want to organize into multiple pipelines?
Solution: Break up into multiple pipelines and filter accordingly. You can filter in both the Bulk Ingest pipeline as well as the CDC origin pipeline:
To filter in JDBC Multitable origin, configure the Tables tab. This tutorial has filters for the movies and users tables. You can use wildcards and exclusion patterns if needed.
To filter in mySQL bin log CDC origin, look in the Advanced tab, in the Include Tables and Ignore Tables config options.
- What if I want to perform physical deletes vs. logical?
Update your pipeline or create a new pipeline especially for deletes. Use the JDBC
Executor or JDBC Producer stage configured with a Cassandra JDBC driver to issue the dynamically constructed delete queries.
- What if I want to perform physical updates vs. logical?
In this case, simply update your StreamSets pipeline and Cassandra data model to remove the created_at and operation_type fields. An existing record in Cassandra will be updated (upsert). The cassandra_schema_no_history.cql file has this model already for you. Note: you'll need to address deletes or sdc.operation.type == 2 in your pipeline with this model.
Source
https://github.com/tmcgrath/cassandra-ingest
RDBMS data model created with https://dbdiagram.io
Cassandra/DataStax data model created with https://hackolade.com
References
- [1] What is Change Data Capture?
- Change Data Capture (CDC) with StreamSets documentation[2]
- Configuring mySQL binlog for CDC
Conclusion
In this tutorial, you saw how to batch load and stream changes from an RDBMS to Cassandra using StreamSets. If you have any questions or suggestions for improvement, let me know!
More Technology
View All
Introducing the DataStax AI Terraform Module


