The most important thing to know in Cassandra data modeling: The primary key

Patrick McFadinVP, Developer Relations & Cassandra Committer

For more recent content on Data Modeling, check out the sample data models in the Data Modeling By Example learning series, as well as Why Data Modeling Is Critical.
The title for this article could really stand alone, but I’m not going to just leave it at that! Yes, this is a fundamental rule for Apache Cassandra, but I’m going to take some time to explain why that statement is correct. With relational data modeling, you can start with the primary key, but effective data models in an RDBMS are much more about the foreign key relationships and relational constraints between tables. Since using a JOIN isn’t possible with Cassandra, we have much less complexity creating data models. The complexity trade-off for Apache Cassandra is in knowing about your queries and data access patterns ahead of time. I won’t be going into how to accomplish that here. There is an excellent course available on DataStax Academy for that topic. This article will focus on how and why to best pick a primary key. The basic primary key Let’s start with the most basic table. These can be called a “Static table” or “Entity table” which are used to store a single record of data. Here is an example from the KillrVideo example application:
CREATE TABLE videos ( videoid uuid, userid uuid, name varchar, description varchar, location text, location_type int, preview_thumbnails map<text,text>, tags set<varchar>, added_date timestamp, PRIMARY KEY (videoid) );
The PRIMARY KEY designation is the simplest form. A single parameter that identifies a single video uploaded to our system. The first element in our PRIMARY KEY is what we call a partition key. The partition key has a special use in Apache Cassandra beyond showing the uniqueness of the record in the database. The other purpose, and one that very critical in distributed systems, is determining data locality. When data is inserted into the cluster, the first step is to apply a hash function to the partition key. The output is used to determine what node (and replicas) will get the data. The algorithm used by Apache Cassandra utilizes Murmur3 which will take an arbitrary input and create a consistent token value. That token value will be inside the range of tokens owned by single node. In simpler terms, a partition key will always belong to one node and that partition’s data will always be found on that node. Why is that important? If there wasn’t an absolute location of a partition’s data, then it would require searching every node in the cluster for your data. In a small cluster, this may complete quickly, but in much larger cluster it would be painfully slow. We want what is shown below.  Complex primary key The other type of table in Apache Cassandra is what we will call a “Dynamic table.” Let’s first look at another example from KillrVideo:
Complex primary key The other type of table in Apache Cassandra is what we will call a “Dynamic table.” Let’s first look at another example from KillrVideo:
CREATE TABLE user_videos ( userid uuid, added_date timestamp, videoid uuid, name text, preview_image_location text, PRIMARY KEY (userid, added_date, videoid) );
- Item one is the partition key
- Item two is the first clustering column. Added_date is a timestamp so the sort order is chronological, ascending.
- Item three is the second clustering column. Since videoid is a UUID, we are including it so simply show that it is a part of a unique record.
After inserting data, you should expect your SELECT to return data in the ascending order of the added_date for a single partition in ascending order. 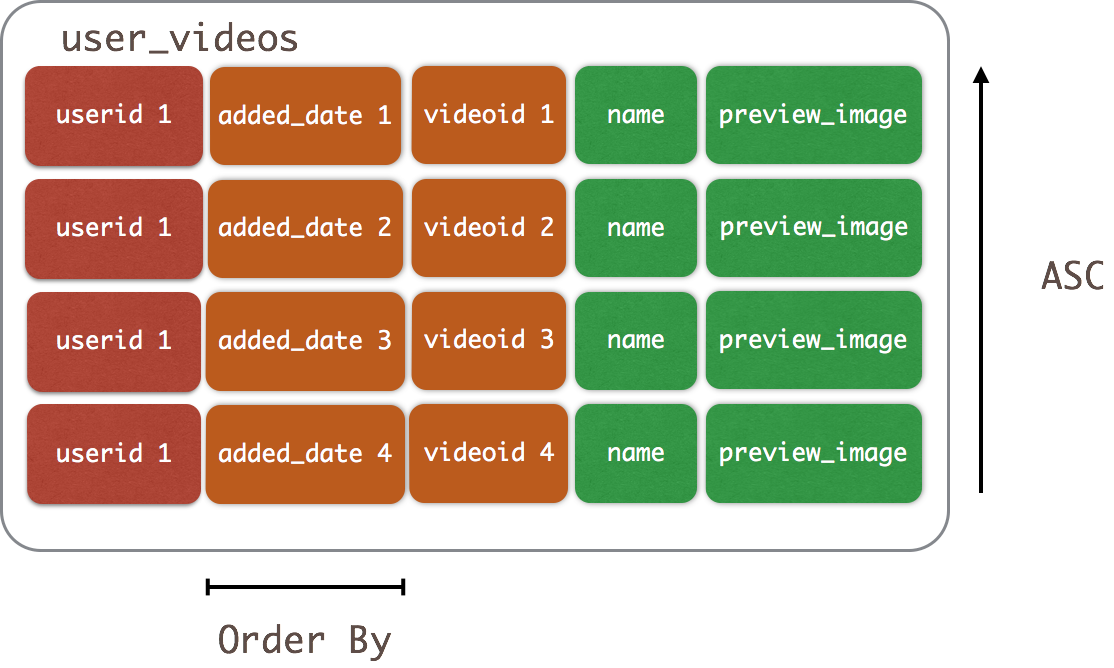 Controlling order of the clustering columns Since the clustering columns specify the order in a single partition, it would be helpful to control the directionality of the sorting. We could accomplish this run time by added an ORDER BY clause to our SELECT like this:
Controlling order of the clustering columns Since the clustering columns specify the order in a single partition, it would be helpful to control the directionality of the sorting. We could accomplish this run time by added an ORDER BY clause to our SELECT like this:
SELECT * FROM user_videos WHERE userid = 522b1fe2-2e36-4cef-a667-cd4237d08b89 ORDER BY added_date DESC; >
What if we want to control the sort order as a default of the data model? We can specify that at table creation time using the CLUSTERING ORDER BY clause:
CREATE TABLE user_videos ( userid uuid, added_date timestamp, videoid uuid, name text, preview_image_location text, PRIMARY KEY (userid, added_date, videoid) ) WITH CLUSTERING ORDER BY (added_date DESC, videoid ASC);
Now when we insert data into user_videos the data will be pre-sorted to added_date in descending order. 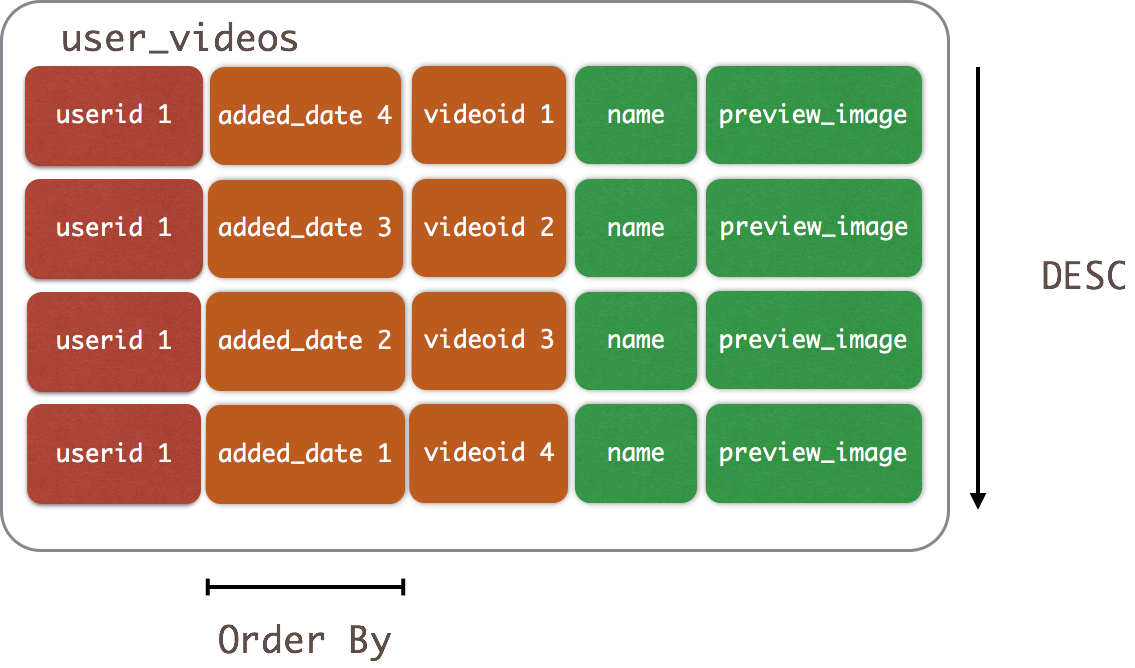 This may seem like a pre-optimization, but the use cases this addition enables are very compelling. WhenCLUSTERING ORDER BY is used in time series data models, we can now quickly access the last N items inserted. As an example:
This may seem like a pre-optimization, but the use cases this addition enables are very compelling. WhenCLUSTERING ORDER BY is used in time series data models, we can now quickly access the last N items inserted. As an example:
SELECT * FROM user_videos WHERE userid = 522b1fe2-2e36-4cef-a667-cd4237d08b89 LIMIT 10;
What this query is asking for is “the last 10 videos the user uploaded” A very fast, useful and efficient query enabled by a simple addition of the CLUSTERING ORDER BY clause. You can see how this might be very useful in cases of user interaction or fraud use cases. Conclusion In this quick overview of the PRIMARY KEY relationships, I hope you see how important this is not only to your queries but also how your store your data. Some basic understanding of the components can help you make some informed choices in your next data model. For example, now that you understand a partition key controls data locality, it’s probably best to not use just one! An extreme example, but one that you could easily make without knowing the reasoning behind it. Now that you know the most important thing to know in Cassandra data modeling, what are you going to do with it? Build something awesome!
This blog post originally appeared on Planet Cassandra.
More Technology
View All
Introducing the DataStax AI Terraform Module


