

This article discusses how you can leverage the paging features of Apache Cassandra to support a great user experience in your application, using examples from the KillrVideo reference application.
When building web applications that have more than a trivial amount of data, paging is an important technique to help the scalability and performance of your application. In paging, the loading of a large data set is broken across multiple requests or “pages”, so named because of how they typically correspond to the pages presented to users on a web application. Loading pages of data as they are needed by the application (or slightly before) provides benefits like faster web page load times and evening out the load on your backend application or services.
Traditional paging approaches have been implemented at the application level or at the database level. These approaches are distinguished by where the paging state is understood or maintained.
In this article we’ll look about approaches to paging in web applications using DataStax Enterprise and Apache Cassandra, including a paging approach that incorporates both application and database layer paging. To do this we’ll use some real working examples from the KillrVideo reference application, which is freely available on GitHub.
KillrVideo consists of a web app which sits on top of a service layer, which in turn uses DataStax Enterprise for its data storage, search and analytics features. Implementations of the service layer are provided in multiple languages; I’ve provided references below to both Java and Node.js implementations as these tend to be two of the more popular languages for driver usage.
Background - KillrVideo Application
For this post we’ll be considering the paging needs of the KillrVideo web application. As you can read about in the architecture documentation, KillrVideo uses a microservice-style architecture, with services that support features including:
- Comments Service: Allows users to comment on videos and keeps track of those comments.
- Ratings Service: Allows users to rate videos (on a scale of 1-5) and keeps track of those ratings.
- Search Service: Indexes the available videos for searching by keyword and provides search suggestions (i.e. typeahead) support.
- Statistics Service: Keeps track of statistics for videos like how many times they've been played back.
- Suggested Videos Service: Provides suggestions for videos similar to another video as well as personalized video suggestions for a particular user.
- Uploads Service: Allows users to upload videos to the site and handles converting uploaded video files to a format that's compatible with the site.
- User Management Service: Manages user accounts including signing up and logging in/out.
- Video Catalog Service: Keeps track of all the videos available for playback and the details of those videos (i.e. title, description, etc.)
When you don't need paging (explicitly)
So first of all, let’s consider that there are some cases where paging is not strictly needed, or perhaps it would be better to say “not needed yet”.
The Statistics service (GRPC spec | Java implementation | Node implementation) is an example of where it currently makes very little sense to have paging. The API supports providing multiple video IDs for searching, but the site design doesn’t currently have a page that would involve displaying stats for a large number of movies.
The User Management service (GRPC spec | Java implementation | Node implementation) is focused on actions around specific user accounts, so it does not need paging. However, let’s say we were to add an administrative page to the KillrVideo site that allowed administrators to see all of the user accounts. Implementing this would immediately bring us to a case where we need paging, if there is any significant number of users registered with the site.
Here’s the interesting thing. It turns out that even if you don’t explicitly use paging in your application, it is still occurring under the covers by default. The DataStax drivers default to a page size of 5000 rows. You can override this at the driver level or for individual statements. As your application iterates over the results in a ResultSet, the driver is monitoring your progress and loads additional pages in the background behind the scenes. For simple, small-scale applications, this default behavior is sufficient.
This helps make the point that paging is an approach that often comes into play as you add new features to your application, or as the volume of data scales up. As you build your application, it may make sense to “future proof” in cases where you anticipate growth by controlling paging explicitly from the start, or at a minimum, tuning the page size to maximize tradeoffs such as memory usage and performance.
This is one of those classic cases where a small amount of up front development cost can pay dividends in terms of the long-term supportability of your system, remembering that the majority of a system’s lifetime cost is not in the initial development but in the support phase.
Simple paging in Cassandra
So let’s learn how to handle those cases where we need explicit control over paging. Paging has been available in Apache Cassandra since the 2.0 release and the implementation is simple to use. There are several cases in the KillrVideo application where Cassandra’s paging feature is used that we can use as a starting point.
The Suggested Videos service (GRPC spec | Java implementation | Node implementation) is the simplest example. If you log on to KillrVideo, you’ll notice that when you select a video, the application presents a limited set of related videos. The application bounds the number of related videos so that you aren’t able to scroll through a continuous list of related videos. For this reason, the application only needs to request a limited set of data. The key line in the code modifies the statement (query) as it’s being created to limit the data:
statement.setFetchSize(pageSize);
Because the service is only retrieving a single page of results, this is equivalent to using the LIMIT command in CQL.
That was a trivial example of paging in which we allowed the driver to manage the paging for us, only tuning the page size to limit our result set.
For a more complex example, let’s look at the Comments Service (GRPC spec | Java implementation | Node implementation). Once a video has been selected for viewing, the user interface allows the user to page through the comments associated with that video by scrolling through a list:
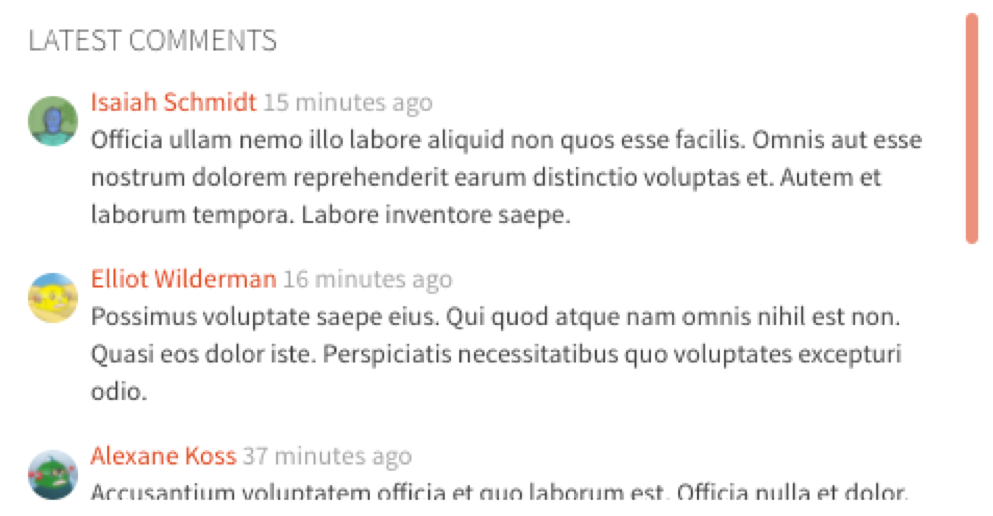
...and then selecting “Show more comments”:
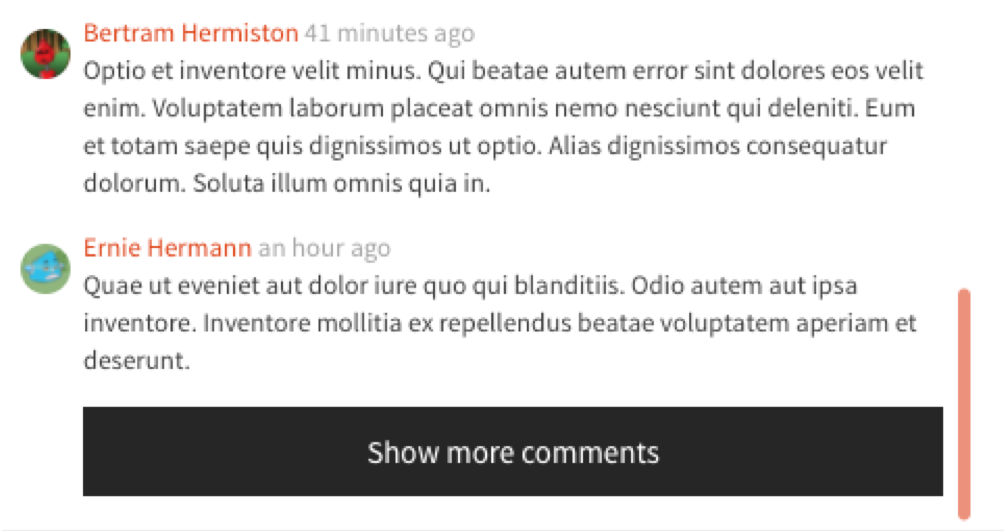
What’s happening here? This is a case in which a paging state managed by the database is passed from the service layer up to the user interface layer. For evidence of this, you can have a look at the interface for the Comments service, which is described via a GRPC prototype file:
// Request for getting a page of comments on a video
message GetVideoCommentsRequest {
killrvideo.common.Uuid video_id = 1;
int32 page_size = 2;
killrvideo.common.TimeUuid starting_comment_id = 3;
string paging_state = 16;
}
// Response when getting a page of comments for a video
message GetVideoCommentsResponse {
killrvideo.common.Uuid video_id = 1;
repeated VideoComment comments = 2;
string paging_state = 3;
}
As you can see, the paging_state is part of both the request and response messages.
Looking at the Java implementation of the Comments service, you’ll see that this state comes directly from the ExecutionInfo in the ResultSet:
commentResult.getExecutionInfo().getPagingState()
This paging state is passed directly back to the service client (the web application) through the interface described above. The webapp can then pass that same paging state back in on the next request, once the user selects that “Show more comments” button. Even though the paging state is being passed to the web application, we refer to this as a database level paging example, since the knowledge of the paging state and its meaning comes from the database. The paging state is considered an immutable string and should not be introspected. Any attempt to manipulate its contents can potentially break across versions.
Another aspect to consider is the explicit control over paging that is required. You will notice that the code uses the asynchronous version of the driver API. This doesn’t significantly affect the approach to paging, which looks something like this:
- Receive the request for comments for a video
- Prepare the statement for execution
- If the request contains a non-empty paging state, set the paging state on the statement
- Execute the statement (asynchronously)
- Process the results (asynchronously), counting the number of results and retrieving the paging state
- Return the updated paging state as part of the response (note that it may be null if there are no more results)
In summary, the service is just a pass through for the paging state, which is managed by Cassandra. The Search service (GRPC spec | Java implementation | Node implementation) uses a similar approach to the Comments service.
Application and Database-level Paging Combined
Since KillrVideo is a reference application for DataStax Enterprise and Apache Cassandra, it doesn’t contain an example of paging that works only at the application level. However, it does contain a really interesting example of a paging scheme that incorporates both application level and database level elements.
When you first visit the KillrVideo site, you’ll see a page that looks something like this, with a section called “Recent Videos” at the top.
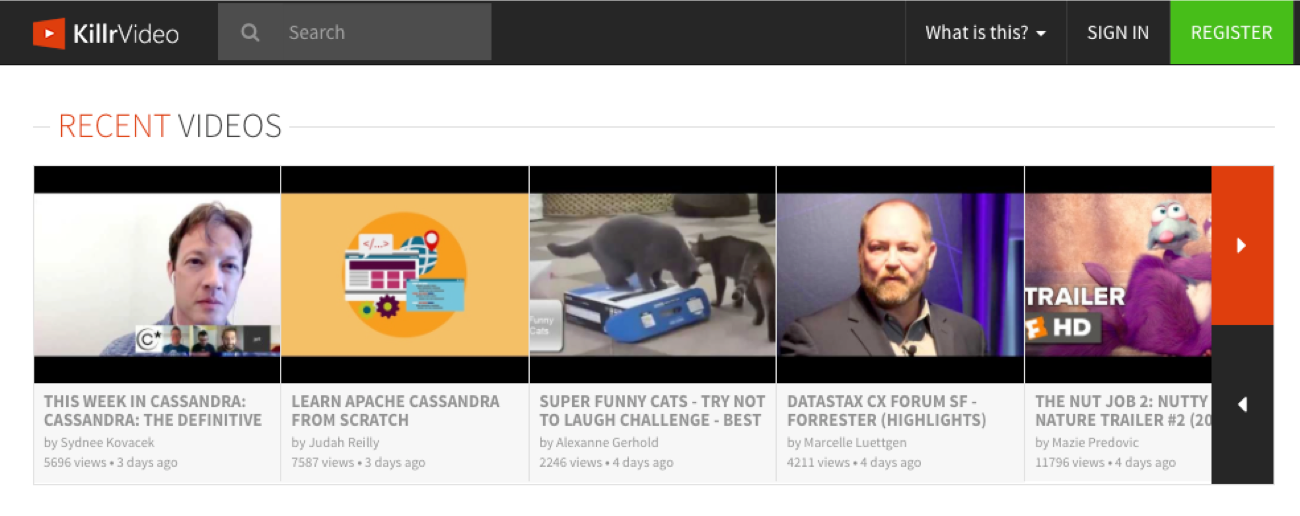
If you click on the red arrow to the upper right, you can see additional recent videos, and then page back and forth through the list. This behavior is enabled by the Video Catalog service. The code that sits behind this behavior is the getLatestVideoPreviews() operation.
If you examine the GRPC spec, you’ll notice that it looks similar to the the Comment service example we looked at above: a single paging state field is included in the request and response payloads. However, if you look at the comments in the Java implementation, you’ll note that the contents of the paging state are different than in the Comment service. There are extensive comments in the source code to explain what is happening, I’ll try to summarize here.
This is a more sophisticated paging scheme that uses a concatenation of application state and Cassandra paging state. The application paging state consists of a list of dates, and an indication of which of those dates represents the oldest date in the list. By limiting this list of dates to the previous seven days, the application enforces a definition of “recent”.
Let’s think about why this application state is necessary. The purpose of this scheme is to address the mismatch between queries that our Cassandra table can support, and queries that can be supported by the web application. Let’s examine the schema for the table that supports this behavior, the latest_videos table:
CREATE TABLE IF NOT EXISTS latest_videos (
yyyymmdd text,
added_date timestamp,
videoid uuid,
userid uuid,
name text,
preview_image_location text,
PRIMARY KEY (yyyymmdd, added_date, videoid) ) WITH CLUSTERING ORDER BY (added_date DESC, videoid ASC);
As you can see, the partition key for this table is the added_date. This means that we can only query for one day’s worth of latest videos at a time. Therefore, the Cassandra paging state only has meaning within the context of a single partition (day). We need the application paging state to give us the additional context of the partition to which the paging state applies.
Therefore, the algorithm for getting the list of latest videos works something like this, assuming the application has requested a page size of N videos:
- Starting from the date specified in the application paging state (or for the initial query, the current date), retrieve up to N latest videos from the partition for that date, starting from the Cassandra paging state (if any)
- If N videos are obtained and there are more videos in the partition for that date, return the data along with a combined paging state including the date and the Cassandra paging state.
- If less than N videos are obtained, go to the previous date and perform another query to attempt to get enough videos to fulfill the application’s requested page size
- The process continues until either N videos have been obtained, or there are no more dates in the list (we’ve gone back further than a week).
Continuous Paging and its Use Cases
Well, that’s the story on paging in KillrVideo. There is one more feature to mention related to paging in our world: continuous paging, which was introduced in DataStax Enterprise 5.1. Continuous paging streams bulk amounts of records from DSE to the client driver, which can improve read performance up to 3x for analytic queries such as those requiring full table scans.
We haven’t built any functionality into KillrVideo that requires continuous paging, but maybe someday we will create an administrative interface that provides statistics across all users, comments, or videos in the system. Stay tuned to see what we implement next...
More Technology
View All


