Quatre raisons pour lesquelles Apache Pulsar est essentiel dans votre stack data moderne

Yahya JARRAYA

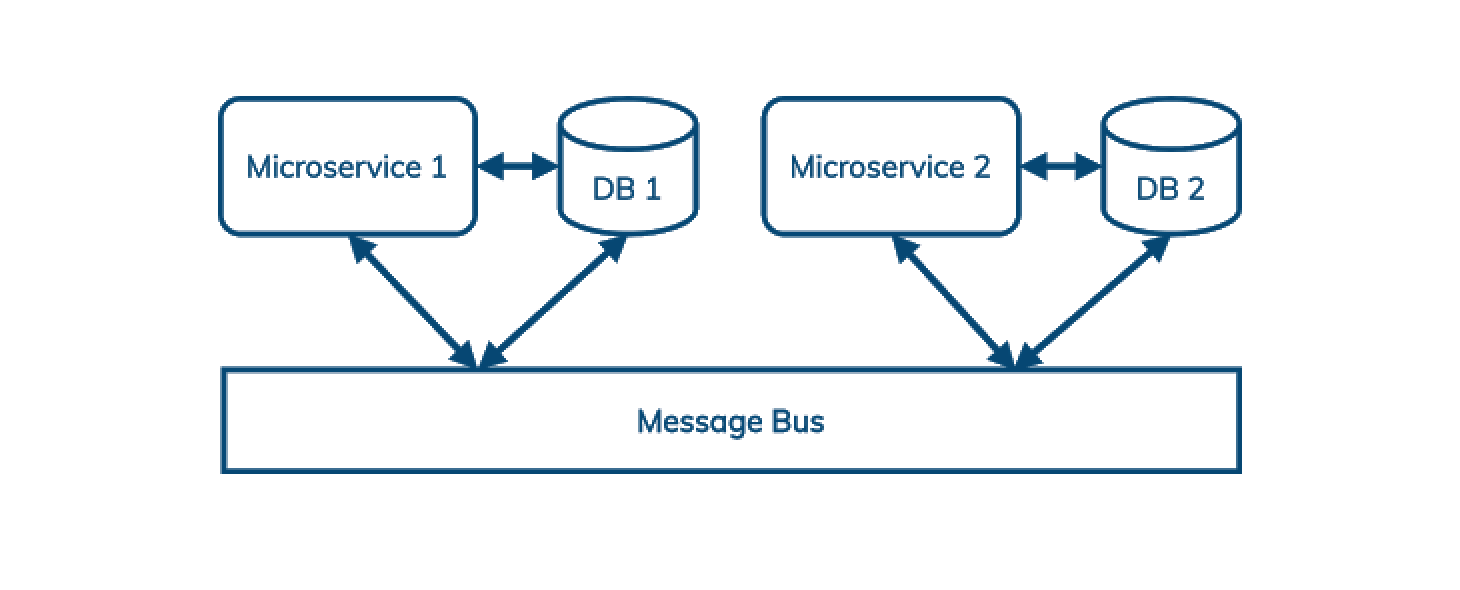
Le messaging/streaming est sur le radar de DataStax depuis plusieurs années: la popularité croissante des architectures basées sur les microservices constitue un facteur de motivation important (et une complémentarité avec les bases de données distribuées): les architectures microservices utilisent un bus de messages pour découpler la communication entre les services; ainsi que pour simplifier le rejeu, la gestion des erreurs et les pics de charge.
Avec Cassandra et Astra, les développeurs et les architectes disposent d'un écosystème de base de données
- Basé sur l'open source
- Bien adapté aux déploiements hybrides, multi-régions et multi-clouds
- Disponible en mode cloud-natif
Il n’existe actuellement pas de solution de messaging qui réponde à ces mêmes exigences. Nous souhaitons donc en construire une.
Nous avons commencé par évaluer l'option la plus populaire, Apache Kafka. Nous avons constaté que Kafka était insuffisant dans quatre domaines:
- Géo-réplication
- Mise à l'échelle (scaling)
- Multitenancy
- Queuing
Apache Pulsar, quant à lui, résout tous ces problèmes à notre satisfaction. Examinons chacun de ces éléments.
Géo-réplication
Cassandra prend en charge la réplication synchrone et asynchrone dans (ou entre) les datacenters (le plus souvent, Cassandra est configuré pour la réplication synchrone dans une région et la réplication asynchrone entre les régions). Cela permet aux utilisateurs de Cassandra comme Netflix de servir les clients partout dans le monde avec une latence locale, de se conformer aux réglementations de souveraineté des données (exemple, stockage local avant réplication géographique, ou encore des copies strictement locales) et de survivre aux pannes d'infrastructure. (Lorsque AWS a redémarré 218 nœuds Cassandra pour corriger une vulnérabilité de sécurité, «Netflix a connu 0 temps d'arrêt.»)
Kafka est conçu pour s'exécuter dans une seule région et ne prend pas en charge la réplication entre les datacenters. Les clients en dehors de la région où Kafka est déployé doivent simplement tolérer la latence accrue. Il existe plusieurs projets qui tentent d'ajouter une réplication inter-datacenters à Kafka au niveau du client, mais ceux-ci sont nécessairement difficiles à exploiter et sujets à l'échec.
Comme Cassandra, Pulsar intègre la géo-réplication dans son ADN. (De même que Cassandra, vous pouvez choisir de le déployer dans une configuration synchrone ou asynchrone, et vous pouvez configurer la réplication par topic.) Les producteurs peuvent écrire dans un topic partagé à partir de n'importe quelle région, et Pulsar veille à ce que ces messages soient visibles pour les consommateurs partout.
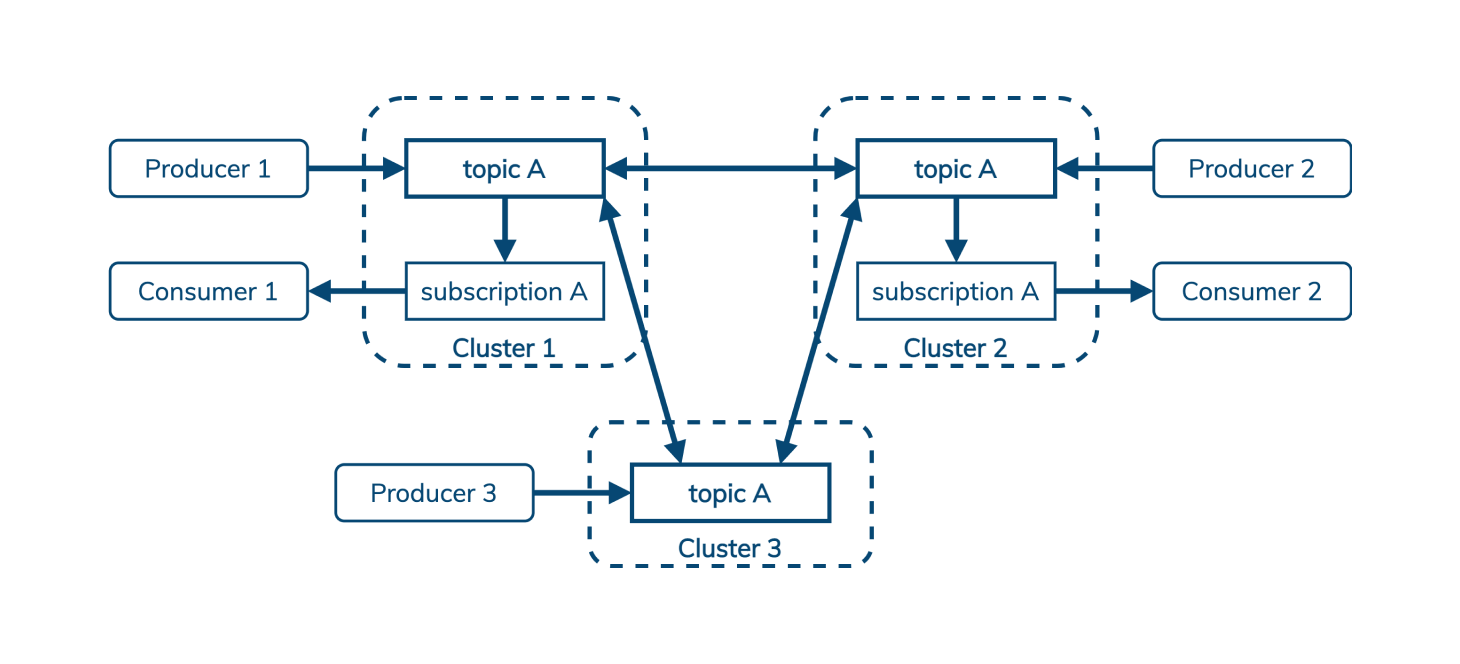
Splunk a rédigé un bon aperçu de la géo-réplication Pulsar en deux parties: partie 1, partie 2.
Mise à l'échelle (scaling)
Dans Kafka, l'unité de stockage est un fichier segment, mais l'unité de réplication est l'ensemble des fichiers segment d'une partition. Chaque partition appartient à un seul broker leader, qui se réplique vers plusieurs abonnés. Ainsi, lorsque vous devez ajouter de la capacité à votre cluster Kafka, certaines partitions doivent être copiées sur le nouveau nœud avant de pouvoir participer à la réduction de la charge sur les nœuds existants.
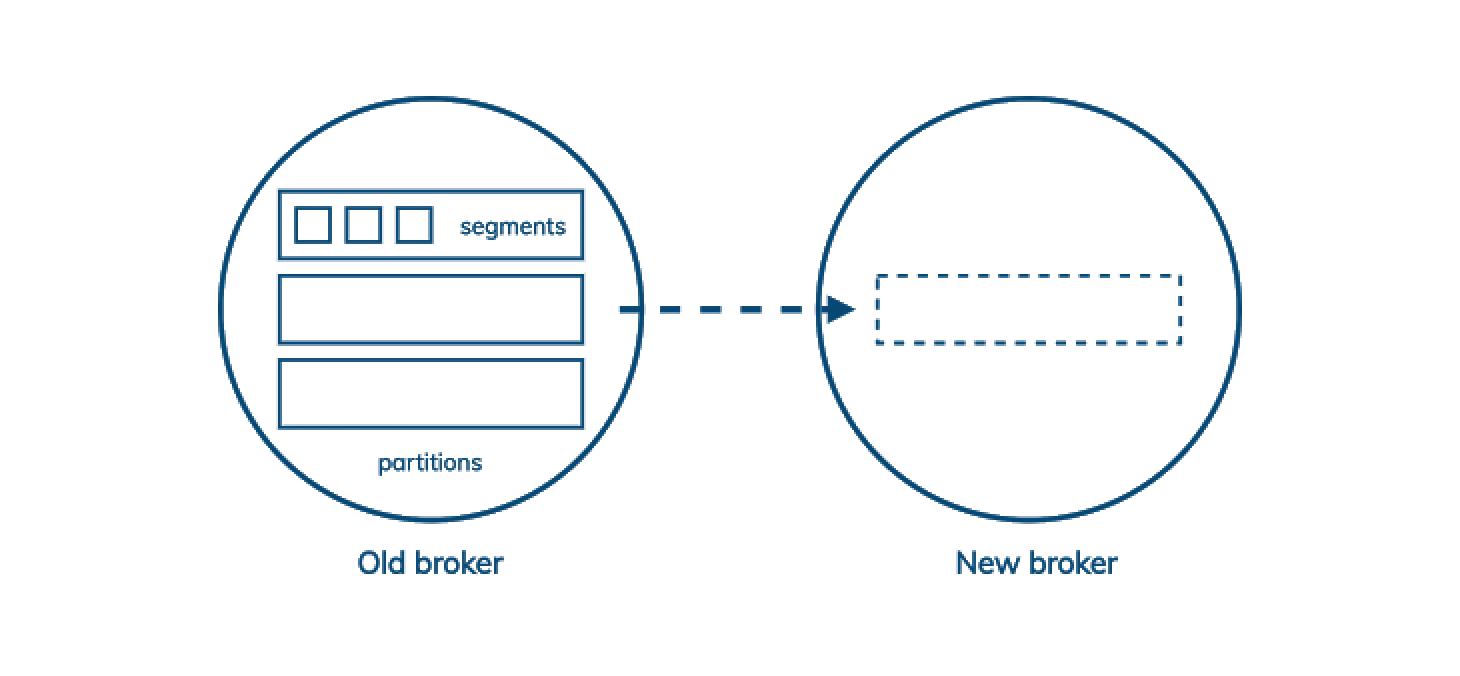
Cela signifie que l'ajout de capacité à un cluster Kafka le ralentit avant de le rendre plus rapide. Si votre ‘capacity planning’ prévoit cela et que cela vous convient, alors c'est bien; mais si les besoins de l'entreprise changent plus rapidement que prévu, cela pourrait être un problème sérieux.
Pulsar ajoute une couche d'indirection. (Pulsar sépare également le calcul et le stockage, qui sont respectivement gérés par le broker et le bookie, mais la partie importante ici est de savoir comment Pulsar, via Bookkeeper, augmente la granularité de la réplication.) Dans Pulsar, les partitions sont divisées en ledgers, mais contrairement aux segments Kafka, les ledgers peuvent être répliqués indépendamment les uns des autres. Pulsar conserve une carte des ledgers appartenant à une partition dans Zookeeper. Ainsi, lorsque nous ajoutons un nouveau nœud de stockage au cluster, tout ce que nous avons à faire est de démarrer un nouveau ledgers sur ce nœud. Les données existantes peuvent rester là où elles sont, aucun travail supplémentaire ne doit être effectué par le cluster.

Consultez le blog de Jack Vanlightly pour une explication approfondie de l'architecture et du modèle de stockage de Pulsar.
Multitenancy
L'infrastructure multi-tenant (traduit par multi-locataires) peut être partagée entre plusieurs utilisateurs et organisations tout en les isolant les uns des autres. Les activités d'un tenant (qu’on pourrait assimiler à un locataire) ne doivent pas pouvoir affecter la sécurité ou les SLA des autres ‘occupants’.
Fondamentalement, le multi-tenant réduit les coûts de deux manières. Premièrement, en partageant simplement une infrastructure qui n’est pas maximisée par un seul occupant, le coût de ce composant peut être amorti pour tous les utilisateurs. Deuxièmement, en simplifiant l'administration - lorsqu'il y a des dizaines, des centaines ou des milliers de tenants, la gestion d'une seule instance offre une simplification significative. Même dans un monde conteneurisé, «ouvrir un compte sur ce système partagé» est beaucoup plus facile à remplir que «me proposer une nouvelle instance de ce service».
Tout comme la géo-réplication, la mutualisation (multitenancy) est difficile à greffer sur un système qui n’a pas été conçu pour cela. Kafka est une conception à tenant unique, mais Pulsar intègre la multitenancy nativement.
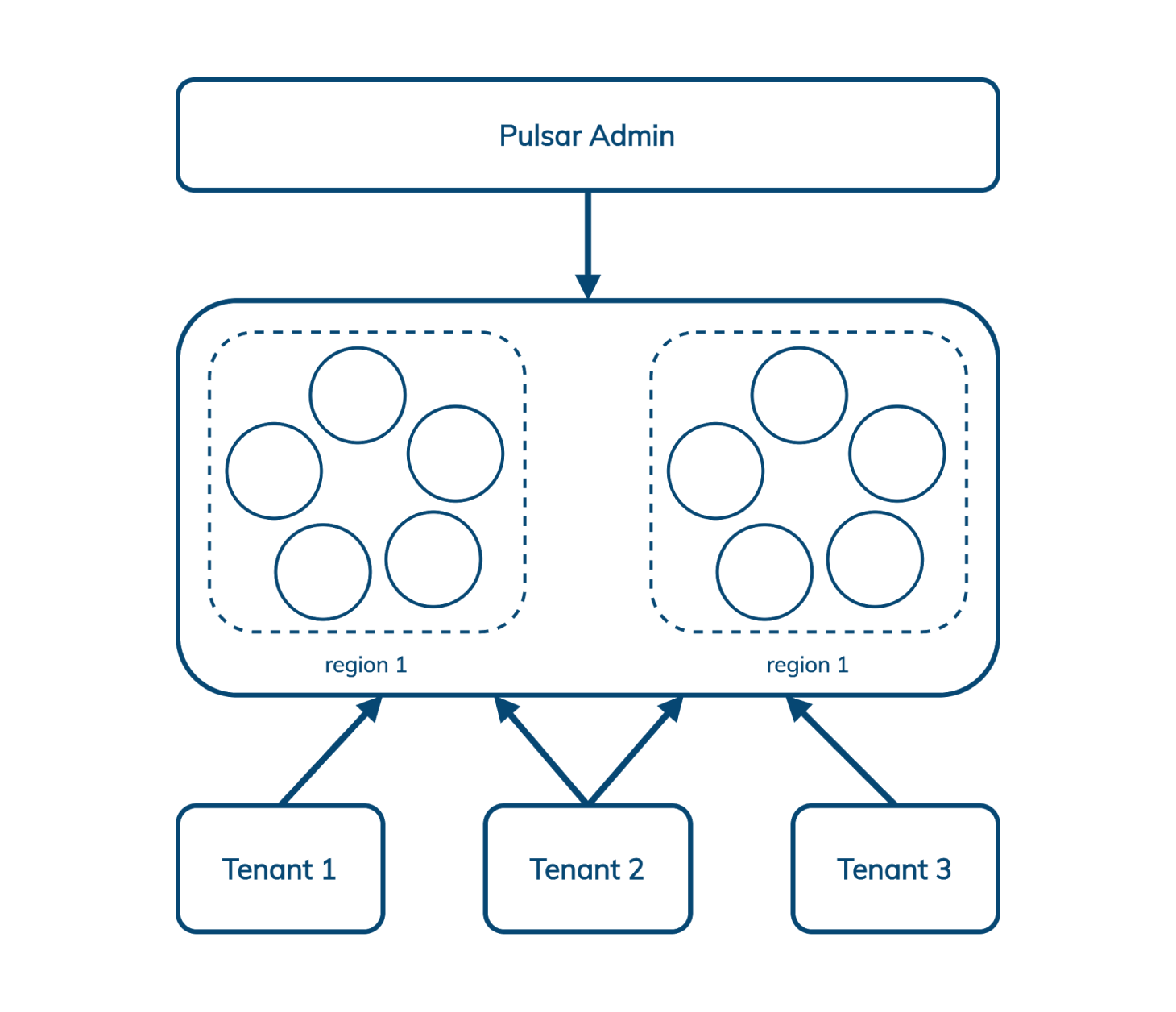
Pulsar nous permet de gérer plusieurs tenants dans plusieurs régions à partir d'une seule interface qui inclut l'authentification et l'autorisation, la politique d'isolation (Pulsar peut éventuellement supprimer du matériel dans le cluster qui est dédié à un seul tenant) et des quotas de stockage. CapitalOne a rédigé un bon article sur la multitenancy de Pulsar ici.
La nouvelle console d'administration de DataStax pour Pulsar rend cela encore plus facile.
Queuing
Kafka propose un modèle de messaging classique pub/sub (publication/abonnement) - les publishers envoient des messages à Kafka, qui les classe par partition dans une topic et en envoie une copie à chaque subscriber (ou «consommateur»).
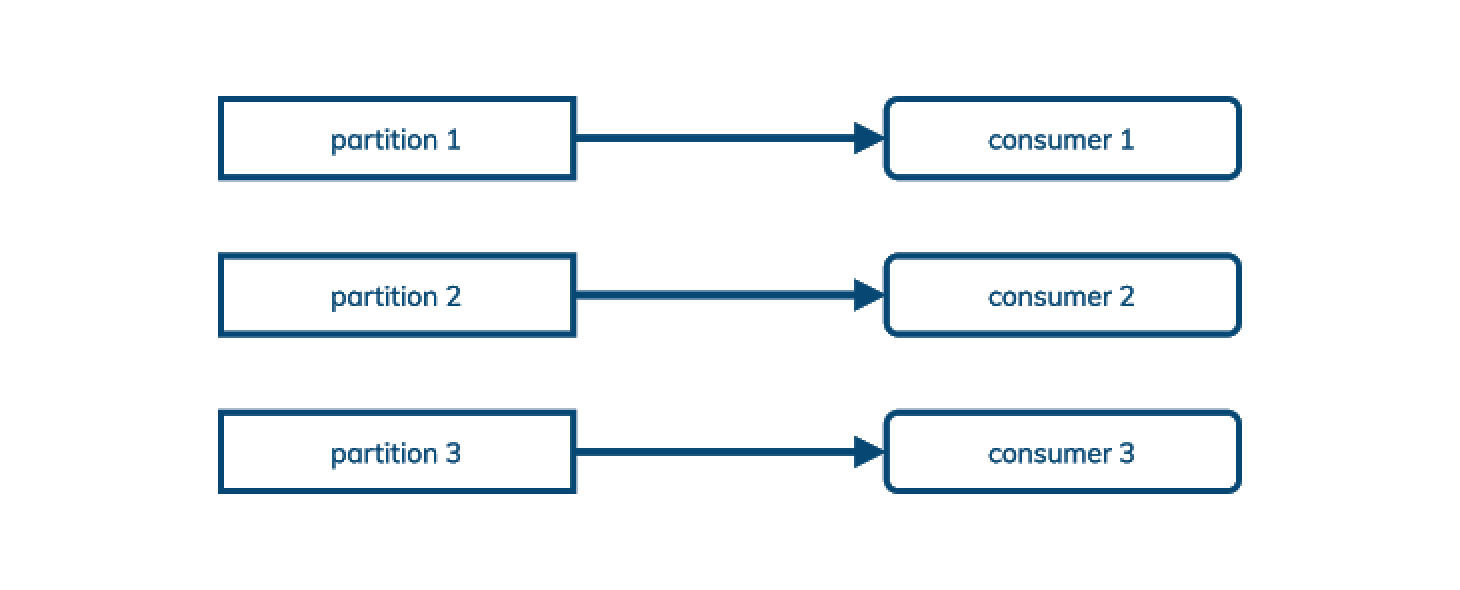
Kafka enregistre les messages qu'un consommateur a vu avec un décalage (offset) dans les logs: cela signifie que les messages ne peuvent pas être confirmés dans le désordre, et donc une souscription ne peut pas être partagée entre plusieurs consommateurs. (Kafka permet de mapper plusieurs partitions à un seul consommateur dans sa conception de groupe de consommateurs, mais pas l'inverse.)
C'est parfait pour les cas d'utilisation pub/sub, parfois (souvent) appelés streaming. Pour la diffusion en continu, il est important de consommer les messages dans le même ordre dans lequel ils ont été publiés.
Pulsar prend en charge le modèle pub/sub tel que décrit précédemment, mais il prend également en charge le modèle de queuing, où l'ordre de traitement n'est pas important. Exemple : nous voulons simplement équilibrer la charge des messages dans un topic sur un nombre arbitraire de consommateurs. Nous appelons cela du “queuing”:
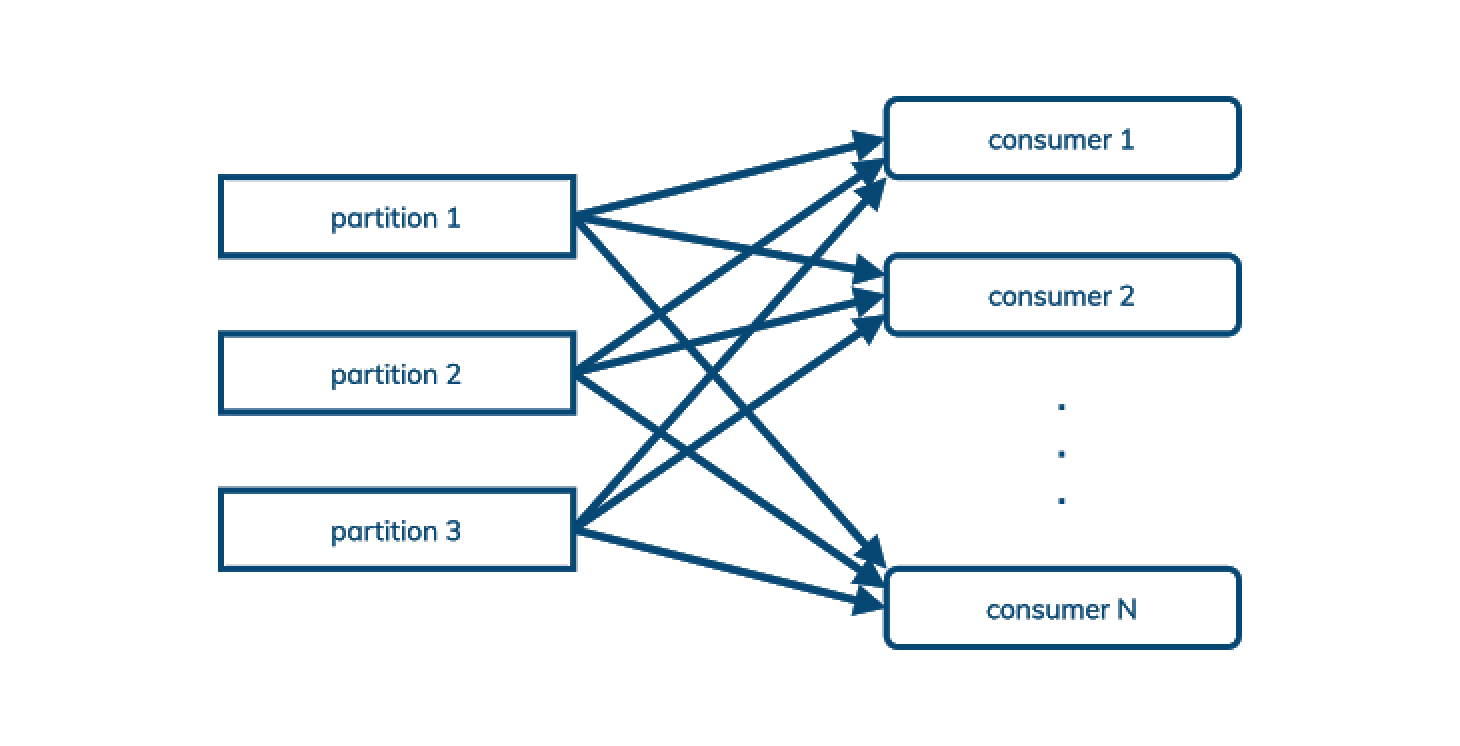
Cela (et des fonctionnalités orientées queuing telles que la “dead letter queue” et “negative acknowledgment with redelivery”) signifie que Pulsar peut souvent remplacer les cas d'utilisation AMQP et JMS ainsi que les topics comme Kafka, offrant ainsi une nouvelle opportunité de réduction des coûts aux entreprises adoptant Pulsar qui permet l’usage des deux approches.
Conclusion
L'architecture de Pulsar lui confère des avantages importants par rapport à Kafka en matière de géo-réplication, de mise à l'échelle (scalabilité), de multitenancy et de queuing (et topic/streaming).
DataStax est ravi de rejoindre la communauté Pulsar avec l'annonce de notre acquisition du Kesque, Pulsar-as-a-service et de l'open-sourcing des outils de gestion et de surveillance et monitoring construits par l'équipe Kesque dans notre nouvelle distribution Luna Streaming de Pulsar.
En savoir plus sur ce que Pulsar peut faire pour Cassandra et ce que Cassandra peut faire pour Pulsar:
- Blog: Data, Data Everywhere: Bringing Together the High Performance Stack for Distributed Data
- Workshop à revoir: Bring Streaming to Cassandra with Apache Pulsar!
- Webinaire: Apache Kafka or Apache Pulsar For Scale-out Event Streaming? (2/16 ou 2/18)
- Conversation (vidéo) RedMonk avec Ed Anuff: The Intersection of Application Development and Databases in 2021