SkyPoint: How to Train Your LLM Dragon

Alan HoChief Science Officer

Abhilash SharmaPrincipal data engineer, SkyPoint

Building generative AI prototypes with retrieval augmented generation (RAG) is relatively easy, but what does it take to get an application to production? Skypoint, a provider of AI-based solutions for the senior care industry, has notched some significant successes, using large language models to improve data accessibility, provide conversational AI, and streamline administrative processes at senior care facilities.
In a recent webinar hosted by DataStax, SkyPoint founder and CEO Tisson Mathew and Skypoint principal engineer Abhilash Sharma shared tips and insights to consider when building generative AI applications.
Use case
Skypoint’s generative AI application gives healthcare providers instant access to public and private data. Skypoint offers both its own interface for users as well as a ChatGPT interface:
Mathew detailed some examples of AI interactions, along with how they relate to SkyPoint’s goal of improving patient care:
“Do they (patients) have care gaps? How do you actually take care of them? What type of clinical protocols are there? So eventually as we are building this, we want the AI agents to write the care plan for a patient. Essentially you are looking at PHI (personal health information) data, compliance, clinical protocols, all of that. And that's how you write a care plan.”
Architecture
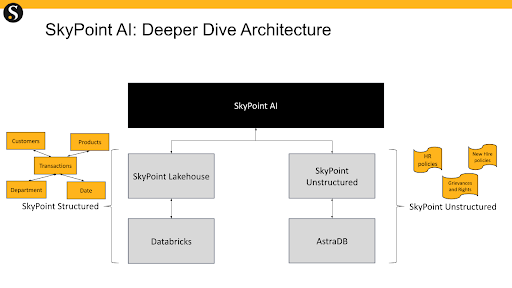
The Skypoint AI application is driven by a combination of structured and unstructured data. Structured data (elderly care information and assisted living ratings, for example) is stored in its lakehouse (backed by Databricks). Unstructured data (such as policy PDFs and legal documents) are stored in DataStax Astra DB with vector search.
LLMs can handle structured and unstructured data, making them versatile for various healthcare applications, such as extracting information from electronic health record (EHR) systems, analyzing vital signs, and answering patient-level questions.
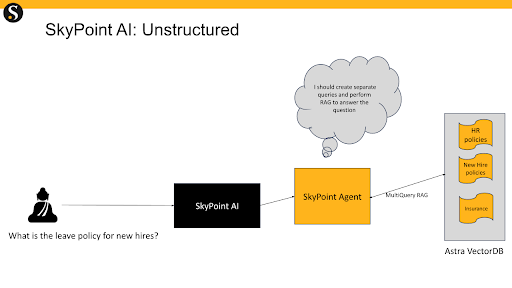
Skypoint AI uses several cutting-edge techniques such as ReAct to use LLMs to determine what data should be queried for a given prompt. If the data is unstructured, it performs the traditional RAG workflow.
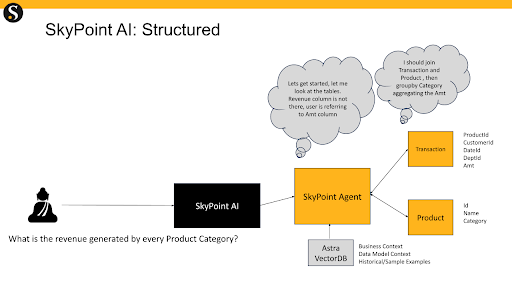
For structured data queries, Skypoint AI translates the natural language query into SQL and executes it against its lakehouse.
Vector database use case: Multiquery RAG
When performing unstructured queries, a single query is turned into multiple queries to increase the amount of data that is summarized and returned to users. This is similar to forward-looking active retrieval (paper, code), and advanced RAG techniques to improve the answer quality and reduce hallucinations.
Skypoint AI uses Apache Cassandra’s intrinsic ability to parallelize queries to achieve fast performance for multi-query RAG within the strict latency SLAs.
Vector database use case: Few-shot prompting
In the scenario of generating SQL statements from natural-language queries, the quality of the SQL can be greatly enhanced using few-shot prompting. Example natural language -> SQL pairs are stored in the vector database. Upon getting a new natural language query, multiple similar natural queries and SQL pairs are put into the prompt (this is also known as chain-of-thought), and SQL is generated. Few-shot prompting is especially useful when generating SQL statements with JOINS.
Vector DB Use Case: LLM Caching
When performing structured queries, Skypoint needs serial calls to LLMs and databases to retrieve schemas and interpret them to generate the appropriate SQL statement for querying the database. This can result in an unacceptable delay in responding to the user. By using the vector store as an LLM cache, the multiple LLM calls can be eliminated, drastically improving the performance of the database.
Skypoint uses Cassandra’s intrinsic fast response times and ability to index new data in its vector store immediately.
Vector DB Use Case: Store conversation traces for debugging and fine-tuning
Storing the thought traces for future analysis serves three purposes:
- Adding conversational context In a conversation with an LLM, properly selecting components of a previous conversation helps the LLM give more contextually relevant answers.
- Debugging By capturing conversations, one can analyze offline whether Skypoint’s agent is correctly answering the customer’s inquiry
- Fine-tuning After accumulating enough thought traces, you can fine-tune the model with the thought traces to ensure that the steps taken to answer a question are more deterministic.
Skypoint uses DataStax Astra DB’s ability to cost-efficiently store, query, and export this information for the purposes of offline analysis or fine-tuning.
Technical and business tips for Gen AI
Add a validation layer (skip to webcast segment) - To reduce hallucinations when performing structured queries, Skypoint performs a validation using an LLM to ensure that the answer is consistent with the question being asked.
Focus on real-world use cases (skip to webcast segment) - In healthcare, LLMs can answer questions, reduce administrative burdens, and improve patient care. Real-world applications include question-answering, creating care plans, and providing data-driven insights.
Structured and unstructured data integration (skip to webcast segment) - LLMs can handle both structured and unstructured data, making them versatile for various healthcare applications, such as extracting information from EHR systems, analyzing vital signs, and answering patient-level questions.
Progressive implementation (skip to webcast segment) - When rolling out generative AI applications, follow a step-by-step process, starting with a subscription to the platform, then a proof of concept (POC) or MVP, and gradually expand to different use cases. Ensure security, privacy, and compliance at each stage.
Educate and train users (skip to webcast segment) - Training and educating users on interacting with the generative AI system is crucial. Feedback and user adoption are essential for the success of AI applications.
Plan for the future (skip to webcast segment) - Consider the future capabilities of generative AI, such as autonomous agents, and plan for advanced use cases beyond the initial implementation.
Conclusion
RAG application prototypes are relatively simple to build, but creating a production-grade application requires highly sophisticated techniques to reduce hallucinations and take advantage of both structured and unstructured data.
Skypoint uses a combination of advanced RAG techniques and the advanced capabilities of Cassandra/Astra DB to achieve production-grade customer experiences for regulated industries like healthcare. If you want to replicate some of the techniques outlined here, sign up to try Astra DB.
For more about Skypoint, check out “Path to Production: Skypoint’s Journey with LangChain and Apache Cassandra,” with Harrison Chase, CEO of LangChain, and Tisson Mathew, CEO of Skypoint, as they share experiences and insights in taking LLM apps into production via on-demand here.



