Supercharge AI Assistants with Superagent and DataStax

Alex LeventerHead of GenAI Ecosystem

At their recent Developer Day, OpenAI announced some exciting features that enable developers and enterprises to use GPT4 with their own data. Many of these capabilities are already available as part of the vibrant open source AI ecosystem. We're excited to tell you about how DataStax Astra DB is now integrated with SuperAgent, an open framework that helps developers build and deploy AI assistants to production fast. This is a story of how embracing open source enables the enterprises we work with to bring this quickly evolving AI ecosystem directly to their data.
Why Superagent?
When considering partnerships and integrations, we look for teams with similar open source values. These are the startups that embrace contributions from a global community of developers with code that any enterprise can inspect and independently choose to use and trust.
Superagent, an open source framework for building autonomous AI agents, is underpinned by LangChain. The folks at LangChain understood that Superagent was improving the experience for developers building AI agents, and decided to promote it. LangChain became the catalyst for Superagent becoming the number one project on GitHub. Open source is a positive sum game: Superagent became a top project, and LangChain became accessible to a broader set of users. That’s how we, and thousands more, found Superagent. Open source works!
Superagent is an open source alternative to OpenAI’s Assistants API that integrates directly with Astra DB with vector, as well as with an extensive ecosystem of real-time data feeds and anything else you’re already using with LangChain. Developers who are considering using Superagent with Astra DB want a simple but powerful way to build AI agents that are fed by real-time data.
Retrieval augmented generation (RAG), which OpenAI refers to as “knowledge retrieval,” is a common design pattern for generative AI applications. In this pattern, an enterprise creates and stores vector embeddings for a data set. A user’s query of that data is similarly embedded and used to find similar data. That similar data, the user’s query, and a little magic are sent to the LLM, which is able to provide an apt response using the context it’s been provided.
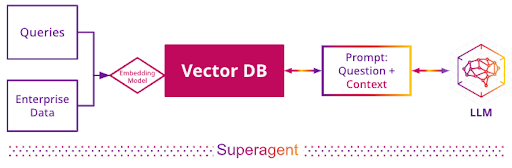
Novel insights and scale: Where Superagent and Astra DB shine
Let’s use the combined powers of Superagent and Astra DB with vector to apply this pattern to something that requires scale, is difficult to do without AI, is able to empower new insights and useful analysis, and offers a broadly applicable design pattern.
If you’ve ever been curious about how a public company measures their success, you’ve probably ended up reading quarterly reports that the company filed with the Securities and Exchange Commission. You also might have compared key metrics of competitive companies and might have even automated that work with the SEC’s API. That data is interesting, but it’s rarely the data that tells the real story of those companies. The good stuff (non-GAAP financials, customer counts, headcount growth, and statements around macro impacts) is buried as unstructured data that’s reported slightly differently by every company.
By automating the combination of structured and unstructured SEC data, we can better understand companies and industries. We now have a use case that:
- Requires scale - historical financial reports of a broad set of companies
- Is difficult to do without AI - the good stuff is unstructured text within SEC filings
- Can provide novel insights and useful analysis - the valuable outcome of democratized access to better data
- Is broadly applicable - anywhere you need to combine structured and unstructured data for new insights
Get started
You can get started with this example today; you can learn from it, extend it, or reuse the pieces that make sense for your own ideas. We recommend starting with the video below, checking out this example app, reading the docs, and jumping onto Superagent’s Discord channel to ask questions.
The GenAI landscape is evolving quickly. If there’s an example you want to see, or technology you think we should know about, please contact us via this form.
Datastax and Superagent are better together; find more information on how to set up and deploy Astra DB, one of the world’s highest performing vector stores, built on Apache Cassandra.
To get started for free, register here.
More Technology
View All
Introducing the DataStax AI Terraform Module


