

This article is a simple tutorial explaining how to connect Tableau Software to Apache Cassandra® via Apache Spark™.
Note: This blog post was written targeting DSE 4.8 which included Apache Spark™ 1.4.1. Please refer to the DataStax documentation for your specific version of DSE if different.

This tutorial explains how to create a simple Tableau Software dashboard based on Cassandra data. The tutorial uses the Spark ODBC driver to integrate Cassandra and Apache Spark. Data and step-by-step instructions for installation and setup of the demo are provided.
1/ Apache Cassandra and DataStax Enterprise
First you need to install a Cassandra cluster and an Apache Spark™ cluster connected with the DataStax Spark Cassandra connector. A very simple way to do that is to use DataStax Enterprise (DSE), it’s free for development or test and it contains Apache Cassandra and Apache Spark already linked.
You can download DataStax Enterprise from https://academy.datastax.com/downloads and find installation instructions here http://docs.datastax.com/en/getting_started/doc/getting_started/installDSE.html.
After the installation is complete, start your DSE Cassandra cluster (it can be a single node) with Apache Spark™ enabled with the command line "dse cassandra -k".
2/ Spark Thrift JDBC/ODBC Server
The Spark SQL Thrift server is a JDBC/ODBC server allowing JDBC and ODBC interfaces for client connections like Tableau to Spark (and then to Cassandra). See here for more details http://docs.datastax.com/en/datastax_enterprise/4.8/datastax_enterprise/spark/sparkSqlThriftServer.html.
Start the Spark Thrift JDBC/ODBC server with the command line "dse start-spark-sql-thriftserver".
You should see a new SparkSQL application running here http://127.0.0.1:4040/ from the Spark UI manager http://127.0.0.1:7080/.
The IP address is the address of your Spark Master node. You may need to replace 127.0.0.1 with your instance IP address if you are not running Spark cluster or DSE locally. With DSE, you can run the command "dsetool sparkmaster" to find your Spark Master node IP.
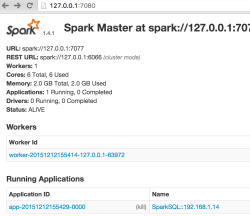
Note that to connect Tableau Software to Apache Cassandra we would have been able to connect directly via the DataStax ODBC driver. But in this case all computations, joins, aggregates are done on the client side, so it's not efficient and risky for large dataset. On the contrary, with Spark jobs everything is done on the server side and on a distributed manner.
3/ Demo Data
Create the 3 demo tables, you can find all data and the script to create CQL schemas and to load tables here : https://drive.google.com/drive/u/1/folders/0BwpBQmtj50DFaU5jWTJtM1pleUU.
When you have downloaded everything, run the script “ScriptCQL.sh” to create schemas and load data (cqlsh must be in your path or download everything into the cqlsh directory). A keyspace named ks_music with 3 tables albums, performers, countries is created.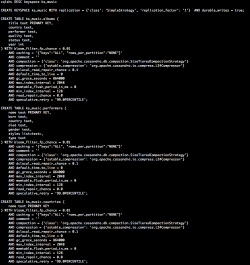

4/ ODBC Driver
Download and install the Databricks ODBC driver for Spark from https://databricks.com/spark/odbc-driver-download or from https://academy.datastax.com/download-drivers.
No specific parameter is need, the default installation is ok. The Mac version can be found only on the Databricks Web site.
5/ Tableau Software
Open Tableau and connect to the Apache Spark server with following settings from the Connect panel:
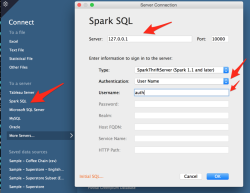
The server IP is the ip address of sparksql thriftserver which may also change depending of your installation. You may also change authentication settings depending of your configuration.
6/ Cassandra Connection
Then you should be able to see all Apache Cassandra keyspaces (named Schema in Tableau interface) and tables (click enter in Schema and Table inputs to see all available Cassandra keyspaces and tables).
Drag and drop albums and performers tables from the ks_music keyspace.
Change the inner join clause with right columns from the 2 tables, Performer from albums table and Name from performers table (click on the blue part of the link between the 2 tables to be able to edit this inner join).
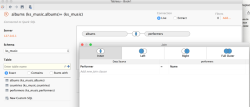
Keep a “Live” connection ! Don’t use “Extract” because otherwise all your data will be loaded into Tableau.
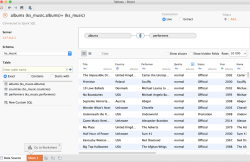
“Update Now” to see a sample of data returned.
7/ Tableau Dashboard
Go to the Tableau worksheet “Sheet 1” and start a simple dashboard.
Convert Year column (from albums table) to Discrete type (click at the right of the Year column to do that from a menu).
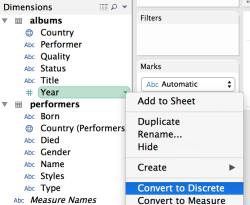
Add Year (from albums table) as Rows, Gender (from performers table) as Columns and Number of Records as the measure.

And with the “Show Me” option, convert your table into a stacked bars chart.

Done, you have created your first tableau dashboard on live Cassandra data !
8/ SparkSQL and SQL Queries
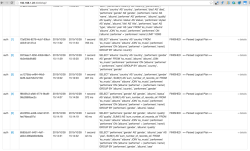
Finally you can check SQL queries generated on the fly and pass to SparkSQL from the Spark UI http://127.0.0.1:4040/sql/ (SQL tab of the SparkSQL UI).
This shows SparkSQL processes and all SQL queries generated by Tableau Software and executed on top of Apache Cassandra data through the Spark Cassandra connector.
Additional links
- Related article on Tableau and SparkSQL http://www.tableau.com/fr-fr/about/blog/2014/10/tableau-spark-sql-big-data-just-got-even-more-supercharged-33799
- Apache Spark Drivers for ODBC and JDBC with SQL Connector http://www.simba.com/connectors/apache-spark-driver
- DataStax Spark Cassandra Connector https://github.com/datastax/spark-cassandra-connector
More Technology
View All


