When Rotten Tomatoes Isn't Enough: Twitter Sentiment Analysis with DSE Part 1

Amanda Moran

A natural language processing example using DataStax Enterprise Analytics with Apache Cassandra andApache Spark, Python, Jupyter Notebooks, Twitter API, Pattern (python package), and Sentiment Analysis

What Problem Are We Trying to Solve?
The question of our time: "What movie should I actually see?" Wouldn't it be great if you could ask 1 million people this question? Wouldn't it be great if I could automate this process?
Data analytics doesn't have to be complicated! It can be as simple as trying to figure out what movie to see!
To do this we can use the power of Big Data, and power of a combination of technologies: DataStax Enterprise Analytics with Apache Spark and Apache Cassandra, Spark Machine Learning Libraries, Python, Pyspark, Twitter Tweets, Twitter Developer API, Jupyter notebooks, Pandas, and a python package Pattern.
How Are We Going to Solve It?
The Jupyter notebook that is available on Github https://github.com/amandamoran/sentimentAnalysisDSE will walk us through each of these following steps to get to our ultimate answer "Should I see this movie?"
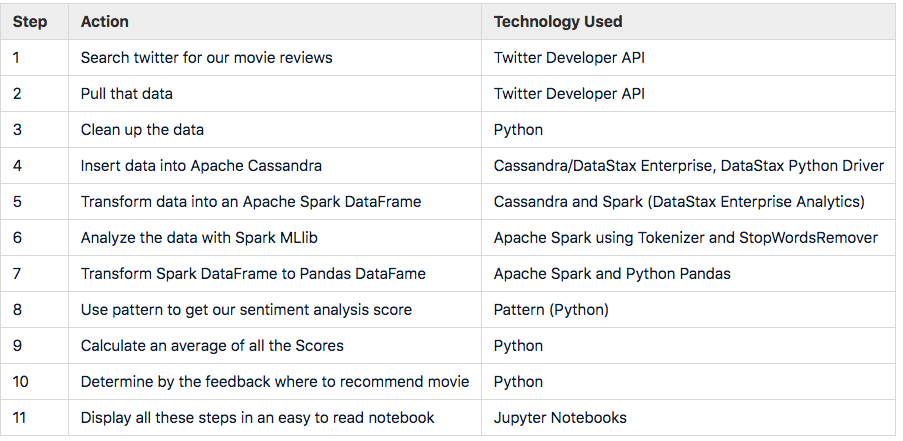
Why Did We Choose Apache Cassandra and Apache Spark?
Apache Cassandra
Apache Cassandra is a highly available distributed decentralized database.
The 4 major advantages of Cassandra are:
- Distribution
- Replication
- Elastically Scalable
- High Availability
Distributed
Each node in the cluster does the exact same job and is available for reads and writes from the client. Because each node in the cluster is the same, adding and removing nodes is a simple process and requires no downtime – not even a restart.
Replication
A distributed database that is highly available, which means surviving a node going down, requires that data be copied to more than one node. Data is replicated out through the cluster asynchronously through peer-to-peer communication. Replication factor can be set by the user and can be anywhere from 1 replica of the data to the number of nodes you have in your cluster.
Elastically Scalable
The read and write path of Cassandra allows for very high performance. Cassandra is elastically scalable, as more nodes are added (which there is actually no set upper limit!) performance increases linearly. Both reads and writes scale linearly, as you increase the number of nodes the ability to read and write data is increased.
High Availability
Cassandra has no single-point of failure because of the lack of a master-worker architecture. The lack of a master node is what allows for such high levels of availability. Cassandra was built with the expectation that nodes in the cluster will fail and because of this when it does, our database doesn't panic.
Think about your application:
- Do you have Big Data (a lot of it!)?
- Do you need to be able to read/write fast?
- Do you need to be able to scale up/down easily?
- Do you need High Availability?
- Do you need multiple data center support?
- Multi-cloud/hybrid cloud support?
If you application needs any of these things, you want to consider Cassandra!
Apache Spark
“Apache Spark is a unified analytics engine for large-scale data processing” --https://spark.apache.org.
Spark is over 100 times faster than Hadoop for analytics, as it utilizes in-memory processing and amazing parallelism. Spark has a variety of Machine Learning Libraries to do text analytics, transformations, clustering, collaborative filtering, classification and more. Spark also has Spark SQL, Spark Streaming, and SparkR. Spark is for performing analytics at scale on very large datasets quickly.
Think about your application:
- Do you have Big Data?
- Do you need High Availability?
- Do you need analytics at lightning speed?
- Do you need a simple way to get insights into your data?
If you application needs any of these things, you want to consider Spark!
DataStax Enterprise Analytics
Spark integration comes out of the box in DataStax Enterprise Analytics. Cassandra can connect to a Spark instance with connectors, but this all must be configured and managed by hand. DSE Analytics has its own file system (DSEFS) that does not have a single point of failure, where the namenode is a single point of failure is HDFS which does not allow for high availability. DSE comes with a highly available Spark Resource Manager -- out of the box! There is no special setup required to enable HA for the Spark Resource Manger on DSE.
Also get all the other benefits of DSE over Cassandra, support, easy of deployment, more testing, a graph engine, search. The list keeps going!
Sentiment Analysis
What IS Sentiment Analysis? Sentiment Analysis at a high level is very simple, it is natural language processing and text analytics to determine if a word or sentence is:
- Positive
- Negative
- Neutral
This is very easy concept for humans to understand, but its very difficult to teach a machine how to do this. Actually, is it that easy for humans to understand and do text analytics? Who hasn't gotten that confusing text with a "period" instead of a "exclamation point" ok. vs ok! The more we move to a text only world with less human face to face time, the more that understand text analytics is important not just for machines learning but for our intereactions with each other.
How to Get Started
Requirements
- Mac OS or Linux
- Python 2.7
- DataStax Enterprise 6
- Jupyter (latest)
- Twitter Development API Access
- Python Packages: pandas, tweepy, cassandra-driver, pattern
- Notebook downloaded from: https://github.com/amandamoran/sentimentAnalysisDSE
This was all setup on a Mac OS laptop and all instructions should also work for a Linux machine. Other variations will work, but not by the instructions listed below.
Twitter API Access
Twitter Developer API access detailed instructions can be found here: https://developer.twitter.com/en/docs/ads/general/guides/getting-started.html
You must create a Twitter app to be able to use the Twitter Dev API. It's a bit confusing the first time you create an app, but just walk through the instructions they provide and its actually straight forward.
Twitter has recently added an additional step that you must fill out an application for a Developer Account before creating the Twitter App.
Note: You can still run the demo with out Twitter API access. Another notebook "When Rotten Tomatoes isn’t Enough CSV.ipynb" with two CSV files is also included in github.
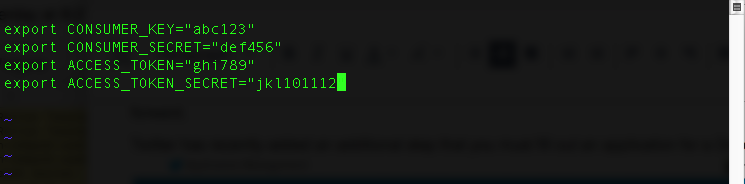
Once you get you authentication keys "Consumer Key, Consumer Secret, Access Token, and Access Token Secret" you will need to set these as environment variables.
In ~/.bashrc (or on Mac ~/.bash_profile):
Install DataStax Enterprise
Installing DataStax Enterprise on one node (even multiple nodes!) is actually very simple. This link has very complete installation instructions https://docs.datastax.com/en/install/doc/install60/installTOC.html
If installing on a Mac machine (or Linux) the instructions are detailed here: https://docs.datastax.com/en/install/doc/install60/installTARdse.html
As long as you have a DataStax Academy account you can download the tar file from here: https://academy.datastax.com/downloads#dse
Note: I used all the defaults and did not setup different locations for my data, logs, and Spark directories. This took around 20 minutes.
After the installation has completed note down the full path names to these two pyspark.zip files. These will need to be added to the notebook to be run later.
<>/dse-6.x.x/resources/spark/python/lib/pyspark.zip
<>/dse-6.x.x/resources/spark/python/lib/py4j-0.10.4-src.zip
Install Jupyter Notebooks
Jupyter can be very easily installed via pip: http://jupyter.org/install
Note: I installed jupyter locally, but it will work with any python based virtual environment like anaconda.
python -m pip install jupyter
Install Python Packages
python -m pip install cassandra-driver
python -m pip install tweepy
python -m pip install pattern
python -m pip install pandas
Start DataStax Enterprise with Analytics
To start a DSE Analytics Cluster, no added configuration needs to be done. Simply start with a -k to start DSE in analytics mode.
dse cassandra -k
Start Jupyter
The most unique element to the setup that is different from other Jupyter notebook installs is how Jupyter is started. To get all the needed enviroment variables needed to connect Jupyter to our DSE cluster, we must start the Jupyter notebooks as a DSE process. From here Jupyter will launch a local browser at http://localhost:8888
dse exec jupyter notebook
A token will be needed to sign in, review the standard out/log files to find this token for the first time login.
[I 13:03:07.074 NotebookApp] The Jupyter Notebook is running at:
[I 13:03:07.074 NotebookApp] http://localhost:8888/?token=66d194ea4f0302a05d7adda7b74f1f1f5e89dd9be829785a
[I 13:03:07.074 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 13:03:07.075 NotebookApp]
Copy/paste this URL into your browser when you connect for the first time,
to login with a token:
http://localhost:8888/?token=66d194ea4f0302a05d7adda7b74f1f1f5e89dd9be829785a&token=66d194ea4f0302a05d7adda7b74f1f1f5e89dd9be829785a
Navigate to Notebook
Navigate to the notebook via the tree directory that has been launched.
Running the Notebook
Once the notebook is open, one last configuration must be done. In the 4th cell of the notebook, two enviroment variables must be set to the paths to the pyspark.zip files found above.
<>/dse-6.x.x/resources/spark/python/lib/pyspark.zip
<>/dse-6.x.x/resources/spark/python/lib/py4j-0.10.4-src.zip
After that is complete it is time to run the notebook!!

Click "Run" for each cell. Take time to understand what each cell is doing.
Let's Explore
Now its time to do the real work of a Data Scientist: Explore!
Change the movie title and search for new movies!
Was Rotten Tomatoes enough? Did you find out new insights that might have been hidden to you before? Data analytics does not have to be complicated!
Stay Tuned for Part 2 and Part 3
Part 2 will focus on how to get this all set up via Docker.
Part 3 will focus on a step-by-step describtion of each cell of the notebook.
More Information
| Technology | Link |
|---|---|
| Twitter Developer API | https://developer.twitter.com/en/docs/ads/general/guides/getting-started.html |
| Apache Cassandra | http://cassandra.apache.org/ |
| DataStax Enterprise Analytics | https://www.datastax.com/products/datastax-enterprise-analytics |
| DataStax Python Driver | https://datastax.github.io/python-driver/ |
| Apache Spark | https://spark.apache.org/ |
| Apache Spark MLlib | https://spark.apache.org/docs/latest/ml-guide.html |
| Python Pandas | https://pandas.pydata.org/ |
| Pattern (Python) | https://www.clips.uantwerpen.be/pages/pattern-en#sentiment |
| Jupyter Notebooks | http://jupyter.org/ |
| DataStax Academy | https://academy.datastax.com/ |
| DataCon LA Presentation | https://www.youtube.com/watch?v=I8-bxR1Wew8 |
What Problem Are We Trying to Solve?
How Are We Going to Solve It?
Why Did We Choose Apache Cassandra and Apache Spark?
Apache Cassandra
Apache Spark
DataStax Enterprise Analytics
Sentiment Analysis
How to Get Started
Requirements
Twitter API Access
Install DataStax Enterprise
Install Jupyter Notebooks
Install Python Packages
Start DataStax Enterprise with Analytics
Start Jupyter
Navigate to Notebook
Running the Notebook
Let's Explore
Stay Tuned for Part 2 and Part 3
More Information
More Technology
View All
Introducing the DataStax AI Terraform Module


