Run Analytics On Operational And Historical Data With The New DataStax Enterprise 4.5 and External Hadoop Integration

Pavan Venkatesh

DataStax Enterprise (DSE) 4.5 provides integration with external Hadoop vendors such as Cloudera and Hortonworks, further enhancing DSE's analytical capabilities. This external integration, also known as bring your own Hadoop (BYOH) allows certain Hadoop components from a prefered vendor to be installed on a DSE cluster in order to run analytic jobs directly on Apache Cassandra™ data.
The new analytic offering comes on top of DSE’s existing integrated Hadoop.
The external Hadoop integration with DSE is aimed at the following scenarios:
- Customers who already have Hadoop cluster in place and would like to connect to DSE cluster, so they can run MapReduce jobs on Cassandra alone or run MapReduce jobs on both Cassandra (hot data) and Hadoop (historical, cold data). The resultant data can either be stored in Cassandra or sent across to the Hadoop cluster for further analysis.
- Customers who wants to utilize latest and greatest Hadoop tools to run analytics on Cassandra data.
Customers looking for integrated analytics solution should use the new Apache Spark™/Shark option available as part of DSE 4.5.
Lets walk through how this new external Hadoop integration works on DSE with an architecture diagram followed by a sample demo.
Architecture
The integration requires deploying one DataStax Enterprise 4.5 cluster and one external Hadoop cluster. The external Hadoop can either be a Cloudera cluster with versions 4.5/4.6/5.0.x or a Hortonworks cluster with versions 1.3.3/2.0.x.
You'll need the following master services in the external hadoop cluster:
- Job Tracker or Resource Manager
- HDFS Name Node
- HDFS Secondary Name Node or a High Availability set up
You'll also need to have at least one set of hadoop slave nodes each having installed:
- HDFS Data Node
- Task Tracker or Node Manager
In your DSE BYOH data center you should install:
- Task Tracker or Node Manager
- Hive, Pig or Mahout clients
You may also install an HDFS Data Node on your DSE BYOH nodes, but we recommend against it. The node has enough going on as it is!
One thing to note is that BYOH nodes are not part of DSE's analytic datacenter. Best practice is to deploy BYOH nodes (Cassandra nodes) in a virtual data center and run external Hadoop services on the same nodes as Cassandra, so the resources on the Cassandra (OLTP) will not interfere with the resources on the BYOH analytic workload.
The diagram below depicts a high level architecture overview of DataStax Enterprise and how it integrates with external Hadoop system.
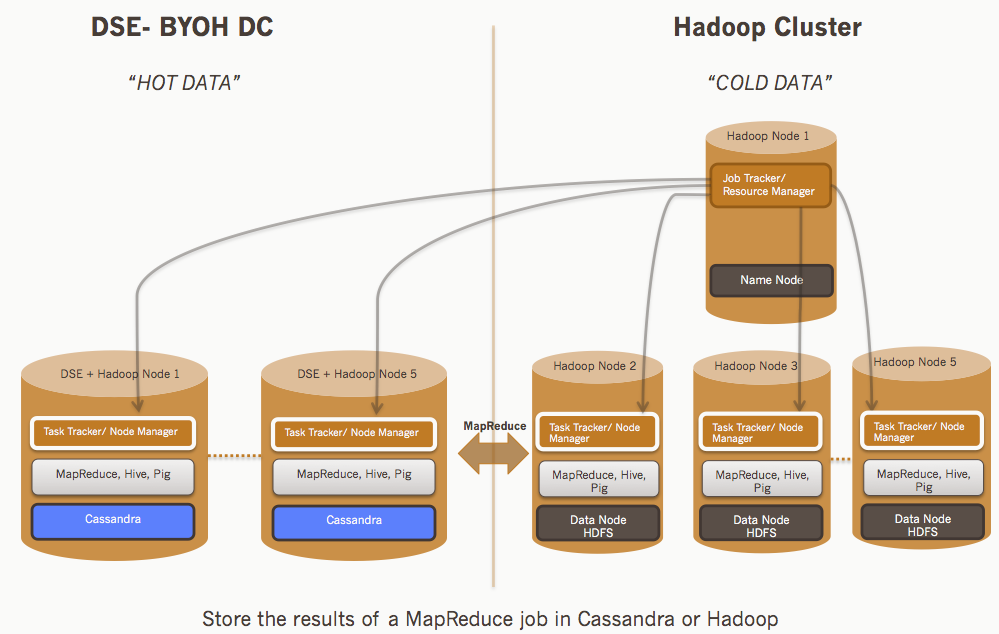
As shown in the diagram above, clients can submit a MapReduce/Hive/Pig job to the Job Tracker (JT)/Resource Manager (RM). JT evaluates the job and the ColumnFamilyInputFormat creates input splits and assign tasks to the various Task Trackers (TT)/Node Managers (NM)- considering Cassandra as the source data. The resultant data can then be either stored in Cassandra or in Hadoop.
Demo
This demo assumes an existing setup of DSE and Hadoop cluster with all the required Hadoop components installed on DSE as mentioned above (using either Cloudera Manager (CDH) or Hortonwork’s Ambari). Please visit our online documentation on how to set this up.
Mark Dewey (QA Engineer) extends the weather sensor demo (available as part of DSE 4.5) to BYOH below. We’ll be using this demo to load data into Cassandra and perform sample Hive queries.
1. First we have to load the demo data into Cassandra. In cqlsh:
CREATE KEYSPACE IF NOT EXISTS weathercql WITH replication = {
'class': 'SimpleStrategy',
'replication_factor': '1'
};
USE weathercql;
CREATE TABLE IF NOT EXISTS station (
stationid text,
location text,
PRIMARY KEY (stationid)
);
COPY weathercql.station
(stationid,location)
FROM 'resources/station.csv'
WITH HEADER='true';
2. We also want to load different data into HDFS. In BYOH Hive:
CREATE TABLE IF NOT EXISTS daily ( stationid string, metric string, date timestamp, location string, max int, mean int, median int, min int, percentile1 int, percentile5 int, percentile95 int, percentile99 int, total int) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' STORED AS TEXTFILE; LOAD DATA LOCAL INPATH 'resources/byoh-daily.csv' overwrite into table daily;
3. Let's do a join looking for the temperature highs and locations of the set of stations in our cassandra table:
SELECT h.stationid AS stationid, s.location AS location, max(h.max) AS max FROM daily h JOIN weathercql.station s ON (h.stationid = s.stationid) WHERE metric = 'temperature' GROUP BY h.stationid, s.location;
hive> SELECT h.stationid AS stationid, > s.location AS location, > max(h.max) AS max > FROM daily h > JOIN weathercql.station s > ON (h.stationid = s.stationid) > WHERE metric = 'temperature' > GROUP BY h.stationid, s.location; ... Usual MapReduce status output here ... OK GKA Goroka 134 GOH Nuuk 134 HGU Mount Hagen 134 LAE Nadzab 134 MAG Madang 134 POM Port Moresby Jacksons Intl 134 SFJ Sondre Stromfjord 134 THU Thule Air Base 134 UAK Narsarsuaq 134 WWK Wewak Intl 134 Time taken: 71.821 seconds, Fetched: 10 row(s)
The weather sensor data is arbitrarily generated. So it’s not surprising that everywhere gets such hot (!) temperatures. Sharp eyes may notice that the join was not strictly needed in this particular query. We did it to demonstrate that it doesn’t matter whether the table is in Cassandra (as the weathercql.station table) or HDFS (as the daily table). For those wanting a stronger taste, check out the Weather Sensor demo (available as part of DSE 4.5 under /demos directory) and try replicating the queries there to actually produce the daily data from scratch.
Start downloading DSE 4.5 and try out the new BYOH integration to run analytics on data stored in DSE-Cassandra cluster (hot data) and the data stored in external Hadoop cluster (cold, historical data).
More Company
View All

The Top 5 DataStax Stories from 2023

