Vector Indexing Explained: Everything You Need to Know
Vector indexes transform how data is searched and retrieved, bringing contextual depth to AI models. How does this innovative indexing differ from traditional database methods in AI applications?
A vector index is a data structure used in computer science and information retrieval to efficiently store and retrieve high-dimensional vector data, enabling fast similarity searches and nearest neighbor queries.
The use of Generative AI and Large Language Models (LLMs) is growing at a very fast pace. Generative AI models are able to create realistic and interactive text, images, video, and audio for a variety of problems. Companies are finding many uses for these types of AI algorithms from building virtual assistants, new ways to search data, and tools to make people’s work more efficient.
Generative AI models can be tailored to specific use cases by providing them with additional context as well as long-term memory. A common pattern to provide this extra context is called Retrieval Augmented Generation (RAG).
For many use cases, RAG is implemented by creating a set of vector embeddings that encode semantic information about the datasets the generative AI application will use, and then searching and retrieving relevant objects from that dataset of vector embeddings to provide back to the generative AI model.
A vector index is a critical piece of the puzzle for implementing RAG in a generative AI application. A vector index is a data structure that enables fast and accurate search and retrieval of vector embeddings from a large dataset of objects. Datastax Astra DB (built on Apache Cassandra) is a vector database that provides a vector index for fast object retrieval as well as efficient storage and data management for your vector embeddings.
In this guide, we will discuss vector indexing, how it works, its importance to generative AI apps through RAG, and how Datastax and Astra DB can help you implement vector indexing easily and efficiently for your generative AI products.
Understanding vector indexing
The purpose of a vector index is to search and retrieve data from a large set of vectors. Why is this important to generative AI applications? Vector representations of data bring context to generative AI models. A vector index enables us to find the specific data we are looking for in large sets of vector representations easily.
Embeddings are a mathematical representation of data that captures the meaning of the object. An embedding is created by taking the object and converting it into a list of numbers, or a vector representation. The resulting embeddings then place related content nearby to other similar content in the vector space.
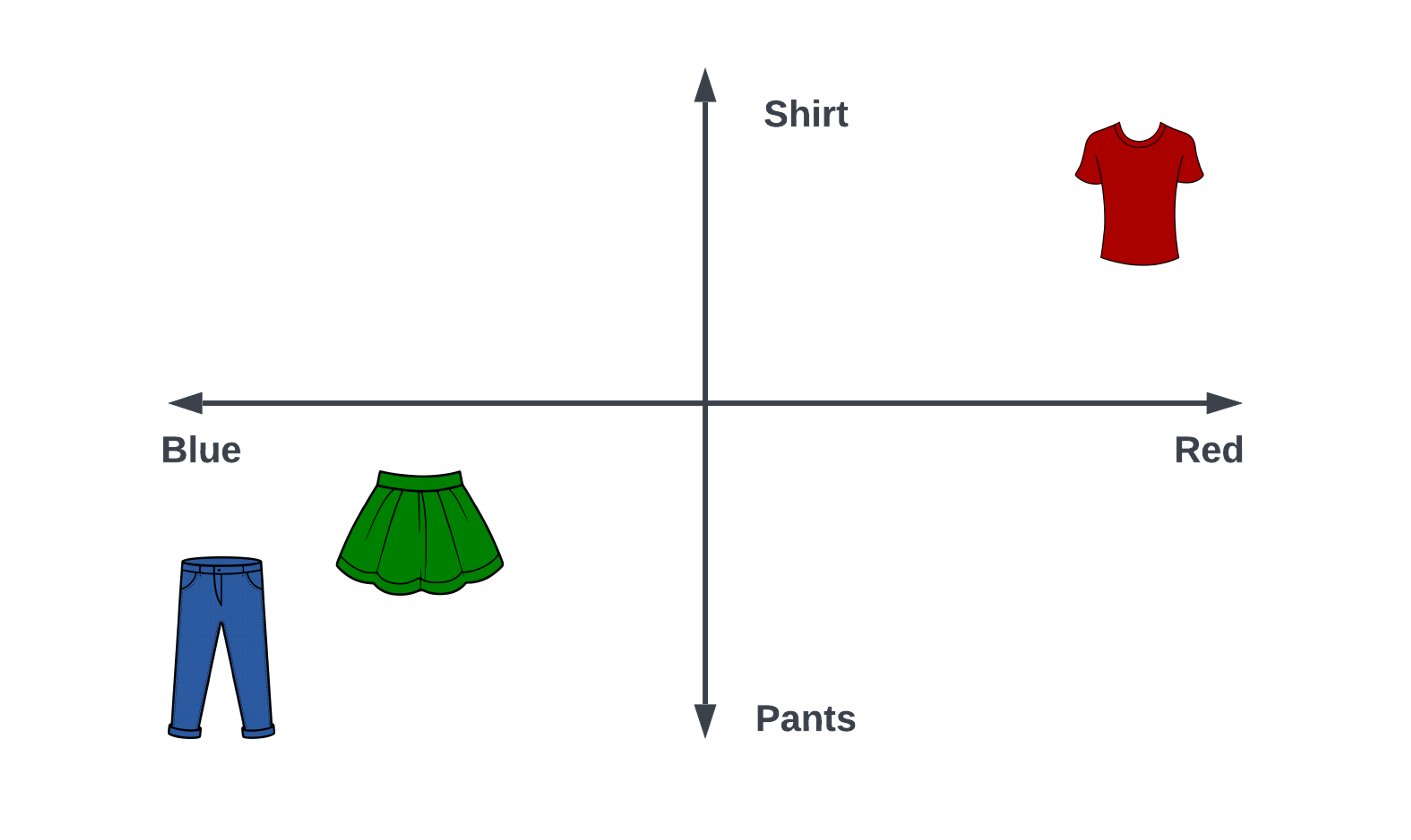
Let’s look at an example to make this more clear. In Figure 1 we show a simple embedding space with two dimensions, one for the type of clothes and a second dimension for the attribute of color.
Figure 1. A 2-dimensional embedding space for clothes.
In this example, the vectors have two dimensions, and the entries represent [clothing type, color]. The red shirt has a vector [1,1] and the blue pants would have a vector [-1,-1]. Now let’s look at the green skirt. A skirt is closer to a pair of pants in function and green is near to blue in the color spectrum, so its embedding vector is near the blue pants and might look like [-0.8,-0.8].
In order to search and retrieve data from a set of embeddings, we need to define a method to compare two vectors. This is often called a similarity measure or similarity metric. These metrics determine that two vectors are nearly the same by comparing the distance or angle between them. Common similarity metrics used in vector search include:
Cosine similarity. Measure the angle between the two vectors. Values range from -1 to 1. For a value of 1, both vectors point in the same direction, -1 they point in opposite directions, and 0 they are orthogonal (perpendicular).
Dot product / inner product. Measures how well two vectors align with each other. Values range from -∞ to ∞. Positive values indicate the vectors are in the same direction, negative values that they are in opposite directions, and 0 are orthogonal.
Euclidean distance: Measures the distance between two vectors. Values range from 0 to ∞. Zero means the vectors are identical and larger numbers are further apart.
In the next section we’ll look at how a vector index works using the concepts of vector embeddings and similarity measure we just discussed.
How does a vector index work?
In traditional databases and indexes, we store data as a row representing some fact or concept, and a set of columns that describe that concept in more detail or link us to supporting tables that contain more information. These data are scalar, meaning they have just a single value instead of vector data, which contains multiple values.
When we query the scalar index to retrieve rows or records, we generally query for exact matches. The power of indexes using vector embeddings that capture semantic information is we can instead search the index for approximate matches. We provide a vector as input and ask the vector index to return other vectors that are similar to the input or query vector. This allows us to search large datasets of vectors very quickly. The class of algorithms used to build and search vector indexes is called Approximate Nearest Neighbor (ANN) search.
ANN algorithms rely on a similarity measure to determine the nearest neighbors. The vector index must be constructed based on a particular similarity metric. In order to build the vector index, we select a similarity metric and a method to create the index. We’ll look at the specific approaches to constructing an index below.
Build Generative AI Apps at Scale with Astra DB
Astra DB gives developers the APIs, real-time data and complete ecosystem integrations to put accurate GenAI apps in production — FAST.
Let’s look more closely at a few different approaches to building a vector index. We can explore implementations of these different index strategies using the Facebook AI Similarity Search (FAISS) library, a popular vector index library. Note that FAISS is only an index and not a vector database like Astra DB. See our guide on vector databases for the benefits of a vector database over a simple index like FAISS.
We’ll give a high-level overview of a few common indexing strategies below.
Flat indexing
Flat indexing is an index strategy where we simply store each vector as is, with no modifications.
Flat indexing is simple, easy to implement, and provides perfect accuracy. The downside is it is slow. In a flat index, the similarity between the query vector and every other vector in the index is computed.
We then return the K vectors with the smallest similarity score.
Flat indexing is the right choice when perfect accuracy is required and speed is not a consideration. If the dataset we are searching is small, flat indexing may also be a good choice as the search speed can still be reasonable.
Locality Sensitive Hashing (LSH) indexes
Locality Sensitive Hashing is an indexing strategy that optimizes for speed and finding an approximate nearest neighbor, instead of doing an exhaustive search to find the actual nearest neighbor as is done with flat indexing.
The index is built using a hashing function. Vector embeddings that are nearby each other are hashed to the same bucket. We can then store all these similar vectors in a single table or bucket.
When a query vector is provided, its nearest neighbors can be found by hashing the query vector, and then computing the similarity metric for all the vectors in the table for all other vectors that hashed to the same value. This results in a much smaller search compared to flat indexing where the similarity metric is computed over the whole space, greatly increasing the speed of the query.
Inverted file (IVF) indexes
Inverted file (IVF) indexes are similar to LSH in that the goal is to first map the query vector to a smaller subset of the vector space and then only search that smaller space for approximate nearest neighbors. This will greatly reduce the number of vectors we need to compare the query vector to, and thus speed up our ANN search.
In LSH that subset of vectors was produced by a hashing function. In IVF, the vector space is first partitioned or clustered, and then centroids of each cluster are found. For a given query vector, we then find the closest centroid. Then for that centroid, we search all the vectors in the associated cluster.
Note that there is a potential problem when the query vector is near the edge of multiple clusters. In this case, the nearest vectors may be in the neighboring cluster. In these cases, we generally need to search multiple clusters.
Hierarchical Navigable Small Worlds (HNSW) indexes
Hierarchical Navigable Small World (HNSW) is one of the most popular algorithms for building a vector index. It is very fast and efficient. We won’t get into the full details of how to implement HNSW works as it is a bit complicated, but we’ll hit some of the key points here.
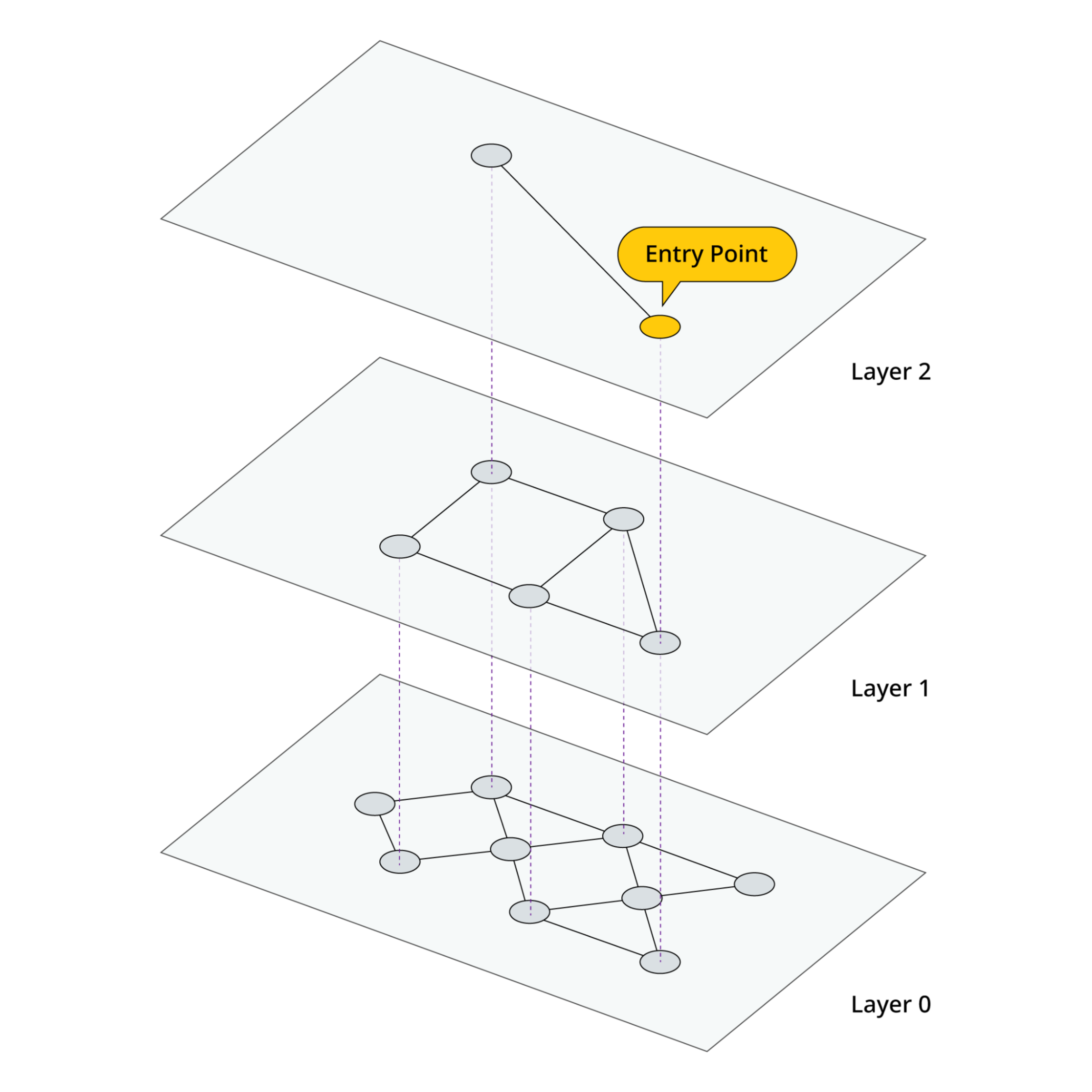
HNSW is a multi-layered graph approach to indexing data. At the lowest level, every vector in the index is captured. As we move up layers in the graph, data points are grouped together based on similarity to exponentially reduce the number of data points in each layer. In a single layer, points are connected based on their similarity. Data points in each layer are also connected to data points in the next layer.
Figure 1: Example of a HNSW graph and the connection of points between layers.
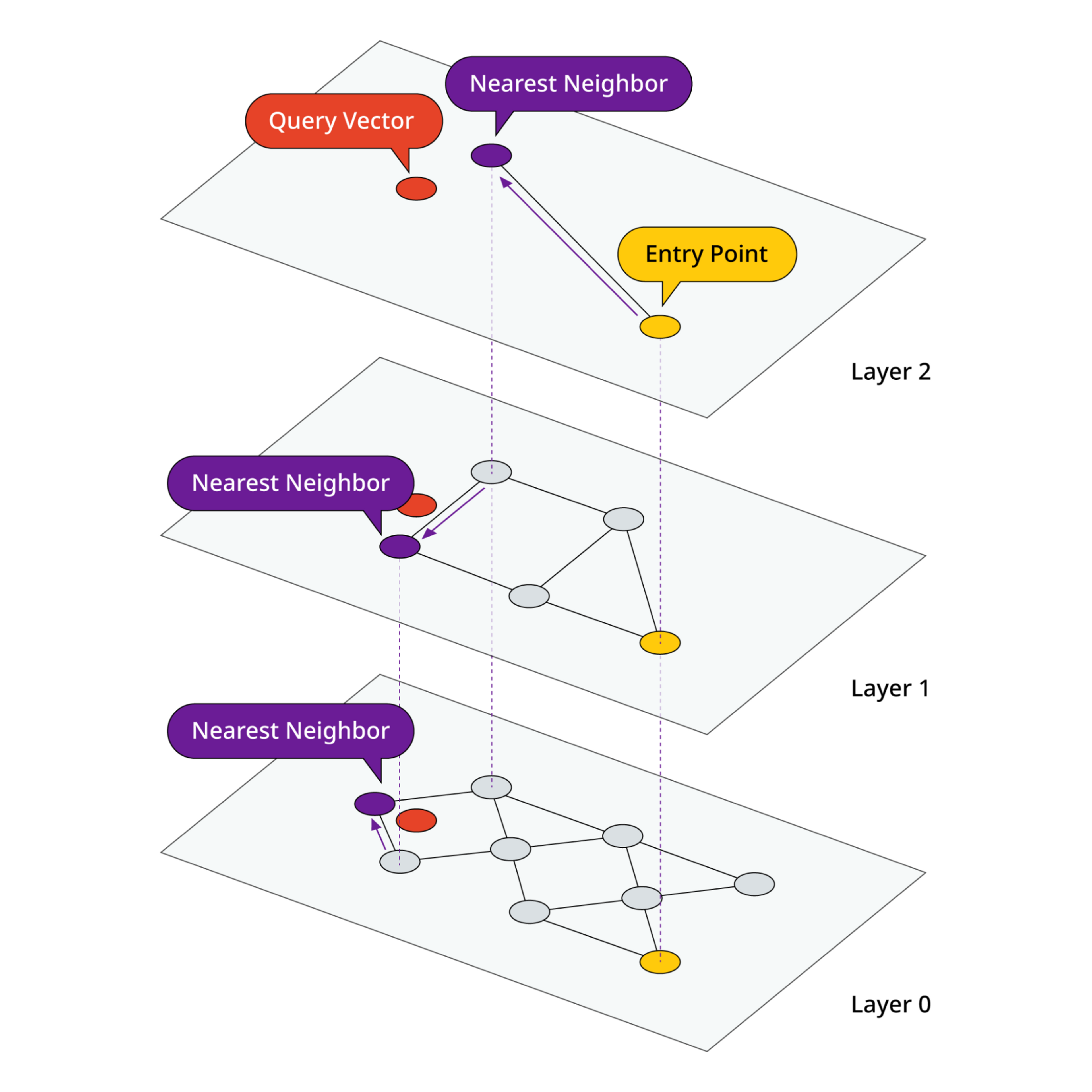
To search the index, we first search for the highest layer of the graph. The closest match from this graph is then taken to the next layer down where we again find the closest matches to the query vector. We continue this process until we reach the lowest layer in the graph.
Figure 2: Example of a search on a HNSW graph. We start at the yellow entry point and find the nearest neighbor to the query vector on layer 2. We then continue down layers finding the nearest neighbor at each layer.
DataStax has built a state of the art open source vector index call JVector that implements a modified version of HNSW called DiskANN.
Challenges and limitations
There are many considerations for choosing an appropriate vector index strategy. First, we have use case considerations. How fast do you need the results? How accurate do you need them to be? All vector index methods have some balance between the speed at which we can retrieve data and find similar vectors and how accurate the results will be.
Additional challenges that are encountered in indexes is how much memory is used. Different algorithms may greatly increase the amount of data that needs to be stored to run the ANN searches efficiently.
The index also needs to be built before we can start executing queries against it. Considerations for how complex is it to build the index need to be considered. Also, how difficult is it to update the index when new vectors are added to the index? If we have to recompute the entire index each time a new vector is added, we need to ask ourselves how often our index will be updated.
How can DataStax help with vector indexing?
Vector indexing enables fast search and retrieval using ANN methods from large datasets. Datastax Astra is a vector database that takes all the complexity of building and maintaining vector indexes so you can focus on building your generative AI app.
Astra supports all the similarity metrics discussed in this guide including cosine similarity, dot product, and Euclidean distance.
A vector index is a data structure for fast retrieval of vector embeddings from large datasets, crucial for implementing Retrieval Augmented Generation (RAG) in generative AI applications. This structure is fundamental for enabling AI models to understand and utilize the embedded information efficiently.
How does vector indexing work?
It enables searching and retrieving data from a large set of vectors, bringing context to generative AI models by finding specific data in large sets of vector representations. This functionality enriches generative AI applications by facilitating a deeper understanding of the data context.
What are embeddings in vector indexing?
Embeddings are mathematical representations of data, converted into a list of numbers or a vector representation, placing related content nearby to other similar content in the vector space. They encapsulate the essence of the data, enabling precise representation and comparison.
How are similarity measures utilized in vector indexing?
They compare two vectors to determine their likeness, using metrics like Cosine similarity, Dot product, or Euclidean distance, aiding in data search and retrieval. These measures are pivotal for identifying similarities and differences among vectors, guiding the retrieval process efficiently.
What differentiates vector indexing from traditional indexing?
Unlike traditional indexing which queries for exact matches, vector indexing searches for approximate matches using vector embeddings, enabling faster search in large datasets. This nuanced approach augments the search capabilities, especially in datasets with high-dimensional vectors.
What is approximate nearest neighbor (ANN) search in vector indexing?
It's a class of algorithms used to build and search vector indexes, relying on a similarity measure to find vectors that are similar to the input or query vector. ANN search exponentially enhances the speed and efficiency of vector searches by focusing on approximate nearest neighbors rather than exact matches.
Astra DB gives JavaScript developers a complete data API and out-of-the-box integrations that make it easier to build production RAG apps with high relevancy and low latency.