The Astra Assistants API Now Supports Streaming: Because Who Wants to Wait?

Sebastian EstevezDataStax

One of ChatGPT’s most appreciated features is its ability to stream answers back to users in real-time, especially for those lengthy responses that take a bit longer to generate. This dynamic interaction not only improves user engagement but also provides reassurance that the system is actively working on delivering results.
Four months after they launched the initial beta of their Assistants API, OpenAI added streaming support to the service last week. Today, we’re announcing support for OpenAI style streaming runs in Astra Assistants--it is available both in the managed service and the open source codebase.
If you're in a hurry, check out examples for both retrieval and function calling in the astra-assitants-api GitHub repo.
The challenge
One of the main drawbacks of the previous iteration of the OpenAI Assistants API beta is that it didn't support streaming. This impacted end users and limited potential use cases by adding up-front latency for every generation. Rather than streaming results almost immediately, calls to list messages associated with a run could only be executed once the model is done generating.
More powerful models like GPT-4 generate tokens relatively slowly, and the longer a message is, the longer it will take to generate. It doesn’t take very long messages for the latency to be too slow for what humans perceive as interactive time. From some quick experimentation with the API, we see messages with about 5,000 characters or 380 words can take over a minute to generate.
How we got here
We actually grew impatient with this situation and implemented and released our own support for streaming back on February 5:
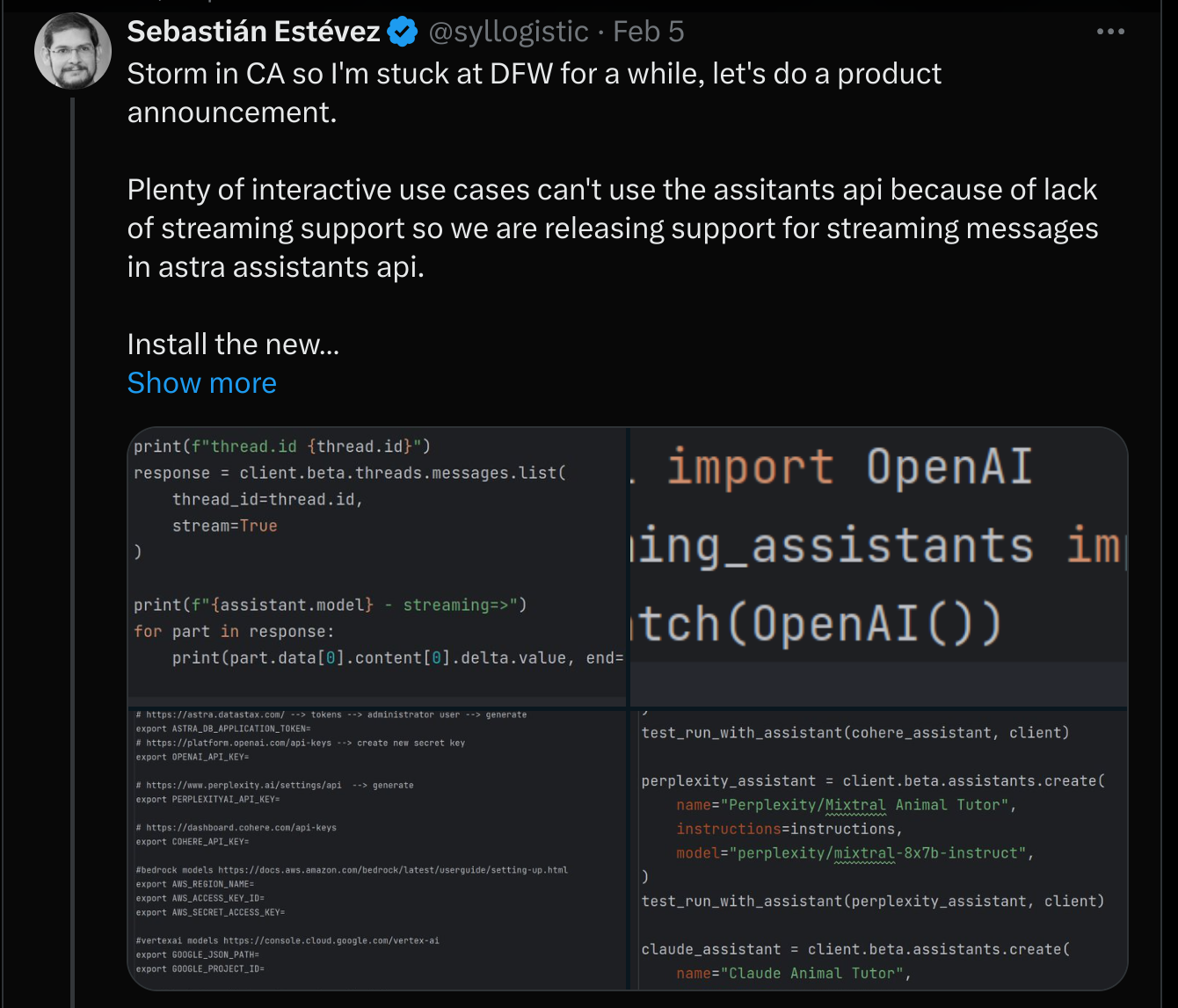
We were excited to see OpenAI unveil their streaming support for Assistants. We first noticed the functionality preview in the UI on March 8:
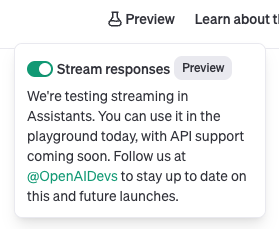
OpenAI did a much more thorough job by implementing streaming runs instead of streaming messages so we quickly went about implementing them in Astra Assistants.
If you're not intimately familiar with the Assistans API, its core resource is a run. Runs are the way you get the LLM to act on a thread of messages and it incorporates all the retrieval augmented generation and function calling. Here is the lifecycle of a run from the OpenAI docs:
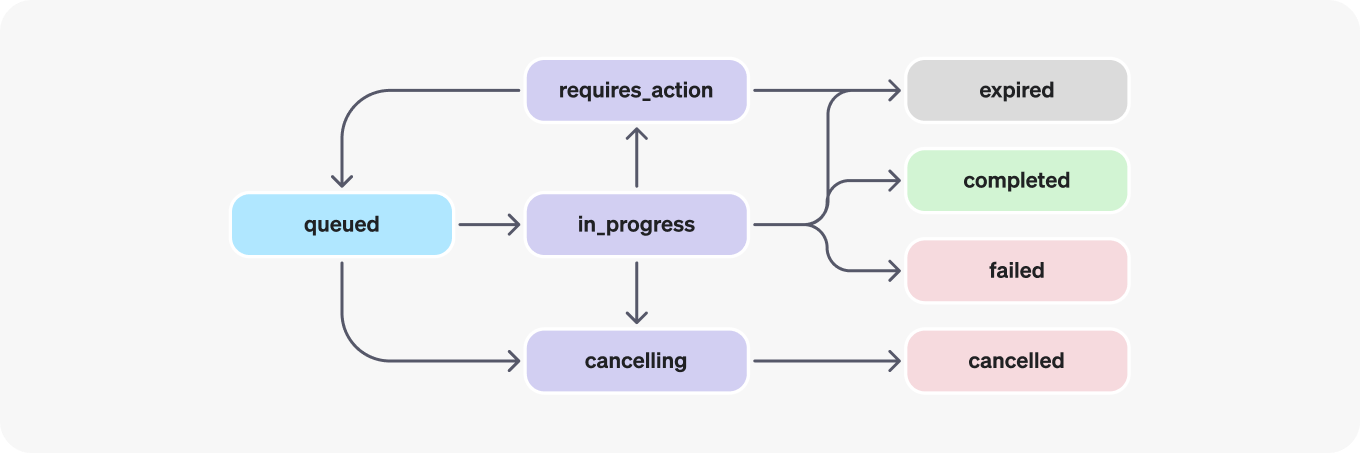
In the old design, users had to create the run and then poll it for status to find out where it was in its lifecycle. When the run reached completed state, you could go and list messages to get the latest completion output.
In the new design, you get a server side events (SSE) stream when you post the run endpoint and it returns events for everything that happens as part of the run. There is a slightly confusing case in function calling where the event stream stops because the run requires_action and you have to start a new one when you submit the tool output. All in all, the new design is much simpler and user friendly than the old polling-based approach. We really like what OpenAI (and the Stainless SDK team) did here.
Compatibility
When we released our original streaming implementation, we communicated the following message in terms of future compatibility:
"We had to make some design decisions that may or may not match what OpenAI will do in their official implementation.
As soon as OpenAI releases official streaming support we will close the compatibility gap as soon as possible while doing our best to support existing users and to avoid breaking changes. This will be a tricky needle to thread but believe that giving folks an option today will be worth the trouble tomorrow.”
We're happy to have been able to quickly deliver on this promise by adding support for the official design only five days after it was released in OpenAI’s API on March 13 and we will continue to support our streaming messages implementation for existing users.
How to use it
Install streaming_assistants using your Python package manager of choice. This small wrapper library picks up environment variables for your third party LLMs so you can use Assistants with non OpenAI models. We might rename the package in the near future given the new official streaming functionality, to either: poetry add streaming_assistants or pip install streaming_assistants.
Import and patch your client:
python from openai import OpenAI from streaming_assistants import patch client = patch(OpenAI()) …
You can quickly print your responses as they are generated by using the client.beta.threads.runs.create_and_stream convenience method in the SDK.
python
print(f"creating run")
with client.beta.threads.runs.create_and_stream(
thread_id=thread.id,
assistant_id=assistant.id,
) as stream:
for text in stream.text_deltas:
print(text, end="", flush=True)
print()You can also iterate through the events instead for more details:
python
print(f"creating run")
with client.beta.threads.runs.create_and_stream(
thread_id=thread.id,
assistant_id=assistant.id,
) as stream:
for event in stream:
print(text, end="", flush=True)
print()Or use a custom EventHandler to handle events as they come. Here's a simple example for function calling:
python
class EventHandler(AssistantEventHandler):
def __init__(self):
super().__init__()
@override
def on_exception(self, exception: Exception):
logger.error(exception)
raise exception
@override
def on_tool_call_done(self, toolCall: ToolCall):
logger.debug(toolCall)
tool_outputs = []
tool_outputs.append({"tool_call_id": toolCall.id, "output": "75 degrees F and sunny"}) # actually call out to your function here
with client.beta.threads.runs.submit_tool_outputs_stream(
thread_id=self.current_run.thread_id,
run_id=self.current_run.id,
tool_outputs=tool_outputs,
event_handler=EventHandler(),
) as stream:
#for part in stream:
# logger.info(part)
for text in stream.text_deltas:
print(text, end="", flush=True)
print()
with client.beta.threads.runs.create_and_stream(
thread_id=thread.id,
assistant_id=assistant.id,
event_handler=EventHandler()
) as stream:
stream.until_done()Conclusion
By adding streaming to the Assistants API, you can make your retrieval-augmented generation (RAG) applications much more engaging and effective and give users the interactivity they have grown to expect.
Try the Astra Assistants API today and discover the potential of real-time generative AI interactions. We can't wait to see what you build!
More Technology
View All
Tips and Tricks for the DataStax Astra CLI

How to Build a Crystal Image Search App with Vector Search

