

Flexibility
Doesn’t require a predefined schema. New data types and fields can be added on the fly.
NoSQL databases are designed to support cloud application requirements and overcome the scale, performance, data model and data distribution limitations of traditional relational databases (RDBMS’s).
To better understand NoSQL databases, let’s first take a look at their alternative: relational databases. The SQL programming language was designed as an easy way to query and modify relational databases. Relational databases that use SQL in this way are simply called SQL databases. Their use dates back to the early 1970s, a time when data storage was extremely expensive. For that reason, data duplication between the tables in relational databases is minimized. While extremely organized, this also makes SQL databases extremely inflexible and difficult to modify. Substantial time and thought needs to be dedicated to their design before the database is created.
Since then, the cost of storage has plummeted, making it far less important to spend time and resources focusing on eliminating data duplication. Instead, the cost of developer time increased dramatically. To maximize developer productivity, NoSQL databases were designed to be extremely flexible and easy to work with and aren’t limited to the table approach. All data types can be stored and accessed together in the same data structure.
Another key factor in NoSQL’s development and adoption—exploding data volume and variety. Since the rise of the Internet in the 1990s, there’s been an ever-increasing flood of data; it comes from everywhere and in all shapes and sizes. Rigid, tabular relational database boxes are no longer a good fit for the ever-expanding variety of data sources, including internet interactions, mobile devices, e-commerce transactions, social media, video, audio, digital images, IoT sensors, analytics, weather readings, AI, machine learning, and much more. Companies needed a sequel to SQL—a database solution that has the flexibility to handle all data types, structured and unstructured, and that can also cost-effectively scale to reliably store it all, no matter how enormous the stockpile becomes.
Internet leaders like Amazon, Google, and Facebook felt this pain first around the turn of the century and created NoSQL (not-only-SQL or non-SQL), a new way to store and access data that no longer relied on relational databases. These tech-giants required massively scalable database management systems that could write and read data anywhere in the world, while delivering performance and availability to billions of users. With the continued rise of cloud computing and big data, today, most organizations must deliver large-scale applications that personalize the customer experience. NoSQL is the database technology of choice for powering such systems.
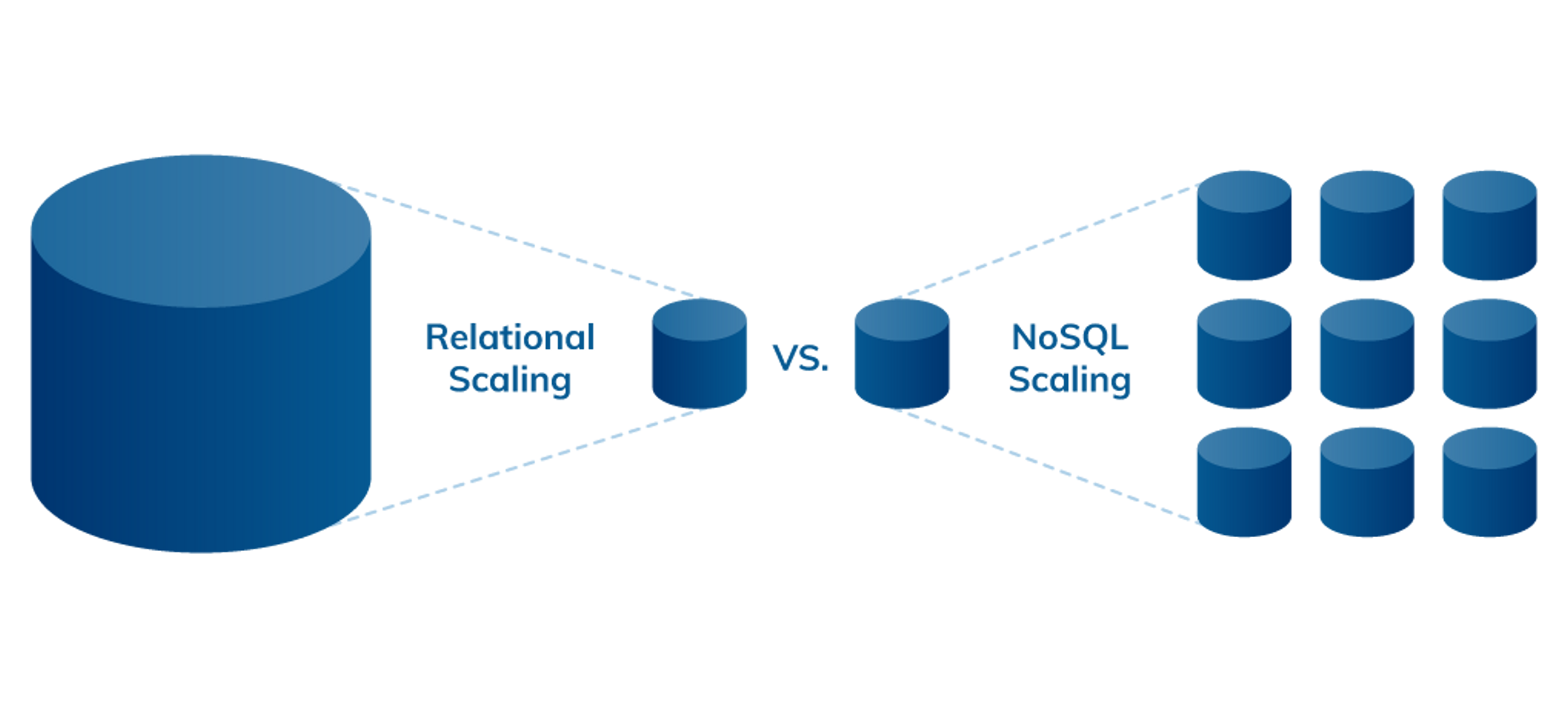
As illustrated below, scalability is one of the key differences between relational and NoSQL databases. The norm for relational databases is to scale-up vertically, where capacity can only be expanded by increasing capabilities, such as RAM, CPU, and SSD, on the existing server or by migrating to a larger, more expensive one. On the other hand, NoSQL databases scale-out horizontally. Rather than upgrading expensive hardware, they can cheaply expand by simply adding commodity servers or cloud instances.
NoSQL and RDBMS databases (such as SQL) support different application requirements and frequently co-exist in enterprises to support different use cases. The key technological decision criteria include the following:
| Relational databases | NoSQL |
|---|---|---|
Use Case | Centralized, monolithic applications | Decentralized (highly scalable), microservice applications |
Availability | Moderate to high availability | Continuous availability, zero-downtime |
Speed | Moderate velocity data | High-velocity data (devices, sensors, etc.) |
Data Types | Primarily structured data | Structured, semi-structured, or unstructured |
Transactions | Complex/nested transactions and joins | Simple transactions and queries |
Read + Write | Scaling reads | Scaling both writes and reads |
Scalability | Scaling up (aka “vertical scalability”) | Scaling out (aka “horizontal scalability”) |
NoSQL also has several database types, giving you the flexibility to choose what’s the best fit for your data and objectives. The main types are:
Key-value databases
Key-value databases are some of the least complex NoSQL databases, as all their data consists of an indexed key and a value. They use a hashing mechanism such that given a key, the database can quickly retrieve an associated value. Hashing mechanisms provide constant time access, which means they maintain high performance even at large scale. The keys can be any type of object, but are typically a string. The values are generally opaque blobs (i.e., a sequence of bytes that the database does not interpret). They make it easy to store large amounts of data and quickly perform lookup queries.
Examples
Some tabular NoSQL databases, like Cassandra, can also service key-value needs.
Document databases
Document databases expand on the basic idea of key-value stores where “documents” are more complex, in that they contain data and each document is assigned a unique key, which is used to retrieve the document. These are designed for storing, retrieving, and managing document-oriented information, often stored as JSON. Each document can contain different types of data. Groups of documents are called collections. Each document in a collection can have a different structure.
Since the document database can inspect the document contents, the database can perform some additional retrieval processing. Unlike RDBMSs which require a static schema, Document databases have a flexible schema as defined by the document contents.
Examples
Note that some RDBMS and NoSQL databases outside of pure document stores are able to store and query JSON documents, including Cassandra.
Tabular databases
Tabular databases organize data in rows and columns, but with a twist from the traditional RDBMS. Also known as wide-column stores or partitioned row stores, they provide the option to organize related rows in partitions that are stored together on the same replicas to allow fast queries.
Unlike RDBMSs, the tabular format is not necessarily strict. For example, Apache Cassandra™ does not require all rows to contain values for all columns in the table. Like key-value and document databases, tabular databases use hashing to retrieve rows from the table.
Examples
Graph databases
Graph databases store their data using a graph metaphor to exploit the relationships between data. Nodes in the graph represent data items, and edges represent the relationships between the data items. Graph databases are designed for highly complex and connected data, which outpaces the relationship and join capabilities of an RDBMS. Graph databases are often exceptionally good at finding commonalities and anomalies among large data sets.
Examples
Multi-model databases
Multi-model databases are an emerging trend in both the NoSQL and RDBMS markets. They are designed to support multiple data models against a single, integrated backend. Most database management systems are organized around a single data model that determines how data can be organized, stored, and manipulated. By contrast, a multi-model database allows an enterprise to store parts of the system’s data in different data models, simplifying application development.
NoSQL databases are primarily designed for supporting decentralized systems that target cloud applications. A NoSQL database like Cassandra typically offers the following benefits over other database management systems:
Doesn’t require a predefined schema. New data types and fields can be added on the fly.
A database that stays online even in the face of the most devastating infrastructure outages.
Fully active data, everywhere you need it.
Response times fast enough for your most intense operational cloud applications.
Predictably scale out and scale in to meet the current and future data needs of cloud applications.
Coherent integration and interoperability of mixed workloads and multiple data models.
Enterprise-ready data management for cloud applications.
No requirements for specialized hardware or ancillary software.
There are a variety of different NoSQL databases on the market with the key differentiators between them being the following:
We can classify NoSQL databases by the data model they support. Some support a wide-row tabular store, while others sport a model that is either document-oriented, key-value, or graph. More on this below.
NoSQL is popular with developers because of its flexibility and ease-of-use. One example of that is its approach to application programming interfaces (APIs). NoSQL provides developers with a wide range of APIs, making it easy to interact with and modify data. Each NoSQL data model— key-value, document, tabular, and graph—has its own set of APIs. And there’s even more choice, with the various NoSQL databases offering different development APIs. Cassandra supports the Cassandra Query Language, an SQL-like language, and other APIs such as REST and GraphQL are under development.
NoSQL databases ensure that data is always available by replicating copies of it across multiple servers. This provides protection against data loss, if one of the database servers fails. Two different replication architectures are used with NoSQL databases: primary/secondary and peer-to-peer.
With the primary/secondary approach, most notably used by MongoDB, a replica set is created that contains one primary replica node and multiple secondary copies. Only the primary replica can handle data updates and write requests. Changes to the primary are then duplicated in the secondaries. The primary can hold-up the process, since it must handle and pass on all updates. If something goes wrong with the primary, one of the secondaries can take its place. However, that process can take more than 10 seconds.
Cassandra, Couchbase, and others use peer-to-peer replication architecture. With this approach, all nodes in a database cluster have equal weight. They all read and write data. The loss of any one of them doesn’t cause any downtime because requests can be handled by any of the nodes. And performance can be improved by simply adding more nodes. Inconsistency is the major downside to peer-to-peer replication. As changes are spread to all the nodes, there could be inconsistent data on those not yet updated. Also, a conflict can be created if the same record receives a write update, at the same time, on two or more different nodes.
Because of their architecture differences, NoSQL databases differ in their support for reading, writing, and distributing data. NoSQL platforms like Cassandra support writes and reads on every node in a cluster and can replicate or synchronize data between many data centers and cloud providers.
It’s also worth noting that a set of databases known as “NewSQL” databases have emerged, adopting many of the distributed system architecture principles introduced by NoSQL databases while attempting to provide the full relational semantics of traditional RDBMS. These databases include Google Cloud Spanner and Cockroach DB and offer a different set of tradeoffs to Cassandra and other NoSQL databases.
Learn About Benchmarking NoSQL DatabasesFrom a practical perspective, how do you go about actually moving to NoSQL and implementing your first application? In general, there are three ways to approach your adoption of a NoSQL database:
Many begin with NoSQL by applying it in new cloud applications and starting from the ground up. This approach avoids the pain of application rewrites and data migrations.
Some choose to augment an existing system by adding a NoSQL component to it. This often happens with applications that have outgrown an RDBMS due to scale problems or the need for better availability.
For systems that exhibit growing costs, or are breaking in major ways due to increased user concurrency, data velocity, or data volume, a full replacement is done with a NoSQL database.
Cost-effective, horizontal scaling. Zero downtime. The flexibility to handle all data types and to make changes on the fly. Several database types to handle a variety of use cases. NoSQL databases have a lot to offer. Are they a good fit for your data environment and organizational goals?