What is Cloud Native?
And what does it have to do with data? Developers worldwide are using cloud-native technologies such as containers, orchestration, and CI/CD automation. Let's look at how you can combine these approaches with flexible data access, through storage, streams, and APIs, so you can build powerful, cloud-native applications that are elastic, scalable, and resilient. The goal? Unlock delivery velocity for your business, while reducing risk and improving quality—particularly on large codebases, worked on by large teams.

Cloud native explained
Cloud native is a combination of technology, methodology, and organizational approaches. It describes a type of service or application targeted for a cloud environment, as well as the characteristics, organizational principles, practices, and technology used to create those services and applications.
Cloud-native technology is designed to take advantage of the cloud’s unique possibilities for scaling out and scaling in, and typically consists of collections of loosely coupled services running in containers. Cloud-native applications leverage cloud-computing technologies like containers (lightweight virtualization), service meshes, microservice architectures, immutable infrastructure, and declarative APIs.
However, as so often happens in our industry, we get lost in technology and forget that cloud native isn’t only about technology. It’s also about the methodology and organizational structure used to develop, test, release, deploy, operate, and maintain these systems. The goal? To increase speed, flexibility, and innovation in the development cycle, while providing predictable iterations toward delivering new digital user experiences. Cloud-native approaches particularly shine with large organizations working concurrently on large code bases, an area where traditionally-built monolithic applications have struggled.
A cloud-native maturity model
Cloud native is the ultimate expression of processes, designs, and techniques designed specifically to exploit distributed, service-oriented cloud architecture when creating applications. There are waypoints along the way in an application’s construction (or migration) journey where incremental value can be achieved—they are the stages of a cloud-native maturity model.
Cloud enabled
A cloud-enabled application is best summarized as a traditionally built monolithic application, minimally (re)designed to run on the cloud. A good way to illustrate their technical differences with cloud-native applications is to examine what would need to be done to redesign a traditional monolithic application. These applications are not intended for deployment on virtual machines and must be redesigned for ephemeral storage. A virtual machine may not have access to the same storage volume across restarts like a typical application running on top of an operating system that owns the specific hard drive and volume. The traditional monolith doesn’t always package all its dependencies in a single, easy-to-work-with file or image that is executable or deployable, and isn’t equipped to encounter dynamic, platform managed ports or networks.
Making these types of changes allows an application to live in a virtualized environment, which is significantly easier and faster to provision. Because many guest virtual machines can run inside a single host, a new application does not mean procuring a new computer and setting it up for that application alone. Bin packing of multiple guest virtual machines inside a single host also makes more efficient use of hardware resources. Cloud enablement is essentially picking up your physical machine and dropping it into a virtual one rented from an IaaS provider, and making the minimum necessary changes to the application code for it to actually function in a virtual environment (a.k.a lift and shift). Minimal usage of Heroku’s classic twelve-factor app-building methodology is made at this level.
Cloud based
Cloud-based applications incorporate more of the twelve-factor approach to application redesign, but still not all of it. Often, these applications don't merit the investment of being fully cloud native, but would benefit from leveraging more than just the typical IaaS-level virtualized hardware. Typically, this can mean shifting from vertical to horizontal scaling, employing techniques like test-driven development, continuous integration, continuous delivery (partially automated release management), and immutable infrastructure. Devops practices, where engineers and operations collaborate to automate ticket-based workflows and jointly create observable applications, are often used at this level of cloud maturity. Instances of your applications can be scaled to meet demand manually, yet much more easily than with traditional monolithic applications. Another major benefit at this level of maturity—the cloud platform manages the availability of virtual machine instances containing your applications. They can be restarted automatically in case of failure, providing higher availability with less manual intervention.
Cloud native
Cloud native is the ultimate expression of the processes, architecture, organizational structures, and techniques used in developing, deploying, operating, and maintaining applications built in a service-oriented, microservice architecture where APIs (interfaces) are a primary consideration. It implies that the application was either specifically designed, or has been rearchitected, to fully exploit the cloud as a target deployment environment. More complete usage of twelve-factor principles creates stateless applications and services. Lightweight, container-based virtualization and continuous deployment (fully automated release management) are the norm. DevOps and Agile methodologies are implied here as well. Benefits at this level of cloud maturity include availability, scalability, and performance—even autoscaling up and down dynamically based on usage. While these benefits may sound familiar, the difference is the level of scale (global) and the drastic reduction in manual effort to achieve these results.
Often, the implication for data and databases in a cloud-native system is a shift to eventually consistent architectures, and making extensive use of messaging and streaming to coordinate data as it moves within the system.
What are the benefits of using cloud-native technologies?
According to the Cloud Native Computing Foundation (CNCF), “Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservice architecture, immutable infrastructure, and declarative APIs exemplify this approach.” The benefits include, “loosely coupled systems that are resilient, manageable, and observable. Combined with robust automation, they allow engineers to make high-impact changes frequently and predictably with minimal toil.”
Resilient
Applications can survive hardware, network and software flaws. Container management systems, like Kubernetes, ensure the availability of applications or services inside of these lightweight virtual instances.
Manageable
Applications are easy to configure and quickly adapt to changing operating conditions and environments. Scalability is provided by the system automatically in response to changing operating conditions, or pre-defined rules.
Observable
Applications are instrumented to collect traces, metrics, logs, and APM data to provide actionable insight. Root cause analysis can be determined quickly, without an operator directly logging into a specific instance and/or making instance-specific changes.
Frequent changes
Applications are modular, allowing rapid incremental changes to individual units. The unit of work for a team is defined by a domain-driven design and the boundaries of a given microservice. Small teams can own and iterate on their implementation as long as they adhere to the API contract. Compare that to traditional monolithic design where interdependencies in the code base make it quite difficult for teams to work independently in parallel. Making changes requires large meetings, painstaking change management processes, and/or impact analysis for any given modification.
Predictable changes
Applications and configurations are source controlled to ensure auditability and repeatability of deployments and configuration changes. Immutable infrastructure is used to ensure that development, staging, QA, test, and production environments are exactly the same. This avoids the configuration drift that is so often responsible for system outages or unexplainable behavior.
Minimal toil
Application deployment and management is automated, reducing busywork and enabling operators to manage systems holistically. Pipelines for continuous integration, continuous delivery, and continuous deployment are used to codify tribal release management knowledge into an automated and repeatable process.
Building cloud-native applications requires a mindset shift that reaches into the culture, processes, and structure of organizations. Whether you're delivering that first app for your startup or modernizing a traditional monolith, adopting cloud-native applications enables you to delight your customers with tailored, personalized experiences, while empowering them to leverage their data in ways they may not have even considered.
Building cloud native applications requires a mindset shift that reaches into the culture and processes of organizations, architecture of the system as a whole, and technology choices throughout the stack. Whether you're delivering that first app for your startup or modernizing a traditional monolith, adopting cloud-native applications enables you to bring tailored, personalized experiences to delight and empower your consumer and enterprise customers to leverage their data in ways they may not have even considered.
Take our DBaaS for a spin and launch your database in 5 minutes or lessThe major components of cloud-native architecture
There is debate if serverless must be a component for an application to be considered cloud native. At DataStax we believe the autoscaling aspect of serverless (vs. functions-as-a-service or FaaS) should indeed be part of a cloud-native application's design. However, it’s clear that both applications and functions can be designed to be cloud native. Let’s review key elements commonly found in cloud-native applications:

Microservice architecture
Small, loosely coupled services which promote agility and independence in the development lifecycle. Multiple instances of stateless microservices support resilience and elastic scalability, and low-risk system evolution. Aligning autoscaling models between the application and data tier ensures smooth autoscaling, preventing bottlenecks and resource starvation.

Programming languages and frameworks
Development teams have the freedom to choose the technologies that best fit the functionality of their application—the implementation matters less than the API contract. When accessing data sources, options range from low-level drivers, to frameworks that abstract drivers and query languages, to higher level data APIs. There are obvious economies of scale when development teams use the same tooling, frameworks and platforms, but not all teams have the luxury of being homogenous in their skills.

Serverless and Functions-as-a-Service
Business logic can be expressed as simple functions that don’t require a full operating system. They can be deployed and scaled with greater ease than microservices using serverless frameworks and FaaS cloud providers. Providing a zero configuration, turnkey, autoscaling (up and down) service where you are basically freed from configuring servers is the core concept for serverless. In general, cloud-native systems avoid singleton, non-autoscaled data repositories if autoscaling is desired at the application tier.

APIs
Strong API contracts and an API-first design are typically employed alongside domain-driven design at the application tier. At the data tier, well known, documented, and defined interfaces provided by microservices and third-party “as-a-service” offerings promote faster development and collaboration between teams, as well as the ability to leverage each API’s unique competence. Examples include schemaless JSON documents, REST, GraphQL, websockets, and gRPC.
Data
Databases, data services, streaming, and messaging platforms enable the flow of data between microservices and persistence in systems of record. Eventual consistency is used widely here, enabled by a unified event streaming and messaging system. Also, the cloud-native application design may disrupt existing data models, requiring data transformation tools. Maintaining backward compatibility with the old data models may also be required for auditing and compliance. Consider the volume, velocity, variety, and value of your data to inform when to employ a relational, columnar, document-oriented, key-value, graph model, or schema-driven vs. schemaless approach.

Containers
Microservices are frequently packaged and deployed as Docker images for portability and optimized resource consumption. Containers employ lightweight virtualization, package multiple dependencies into a single deployment unit, and can be more tightly bin-packed.

Orchestration
Containers are then managed by an orchestration framework such as Kubernetes for automated deployment, operation, scaling, and resilience of applications at scale. Open-source collections of operators like K8ssandra enable Kubernetes to run more than just the stateless application tier, or isolate a singleton pod set to run a database process that is essentially not orchestrated. As an example, K8ssandra integrates and packages together many things into a convenient helm chart:
- Apache Cassandra
- Stargate, the open-source data gateway
- Cass-operator, the Kubernetes Operator for Apache Cassandra
- Reaper for Apache Cassandra, an anti-entropy repair feature (plus reaper-operator)
- Medusa for Apache Cassandra for backup and restore (plus medusa-operator)
- Metrics Collector for Apache Cassandra, with Prometheus integration, and visualization via pre-configured Grafana dashboards
Monitoring
Distributed applications expose new fault domains. This mandates observable systems that emit the required metrics, logs, traces, and APM data needed to determine root error causes, locate slowly executing code, and trigger remediation processes. As distributed system complexity continues to increase, operations teams certainly do continue to employ manual solutions. However, machine learning and other automated means of detection, analysis and remediation are in demand as a way to provide respite to overwhelmed operations teams.

Security
(m)TLS, OAuth, OIDC, JWTs, identity providers, API gateways, and automatic container patching provide new mechanisms to cover attack surface areas. Currency with patches and updates for containers (as well as their contents) is essential. New security attack surfaces require encryption both at rest and in transit, credential repositories and much more. New tooling and automation is often required to meet these requirements as cloud-native systems have many, many more moving parts compared to traditionally architected systems.

Continuous Integration, Continuous Delivery / Deployment Tooling
Risky, infrequent releases are a symptom of ITIL-driven, ticket-based processes. The ability to release code to production at any time can only come from focusing on codifying and automating release management processes. This ability is a key tenet and enabler of cloud-native applications, enabled by Agile practices like test-driven development (and many others). Application code and required infrastructure expressed as “infrastructure as code” are checked into source control systems such as Git, enabling rapid iteration through automated dev, test, and prod pipelines. Continuous integration refers to the practice of merging work from individual developers into a single, shared repository, resolving conflicts and documenting changes along the way. This shared repository is then built by automated processes and their associated test suites run, multiple times a day. Continuous delivery is the practice of then promoting those builds to a running production system, often with a manual last step to release it to production. Continuous deployment removes the penultimate manual approval and any merged change is pushed right to production without human intervention.
Cloud-native applications
Given the variety of design options and data stores available, there are any number of ways to approach data. We’ve observed several common patterns.
“Cloud native is structuring teams, culture, and technology to utilize automation and architectures to manage complexity and unlock velocity.”
Joe Beda, Co-Founder, Kubernetes and Principal Engineer, VMware
Design principles and architectural approaches like API-first design, twelve-factor (stateless) applications, and domain-driven design can be used to make microservices, modular monoliths, and even (gasp!) monoliths themselves into cloud-native applications. But cloud native is more than application architecture and technology like Iaas, PaaS and SaaS. A cloud-native application rests on a foundation of human practices and methodologies as well as an organizational structure.
Database management in a cloud-native environment
Given the variety of design options and data stores available, there are any number of ways to approach data. We’ve observed several common patterns.

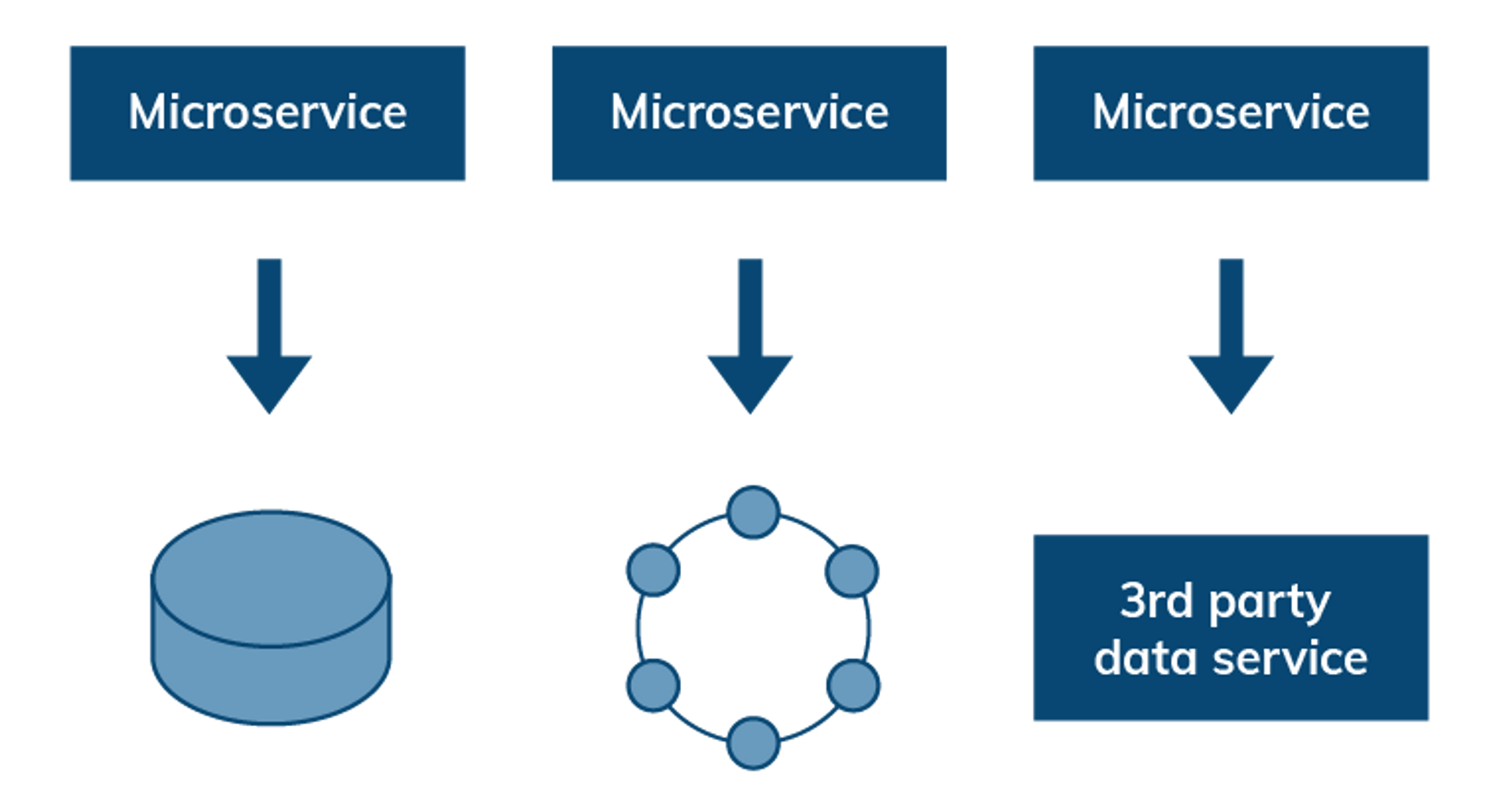
Stateless microservices with delegated data persistence
Microservices typically delegate responsibility for storing state to a persistence mechanism such as a dedicated block storage volume, a distributed database cluster, or a data service. Regardless of the store used, each service should control access to its own data. Saga patterns, compensating transactions, event-driven architecture, streaming, messaging, and eventual consistency are other concepts that become very important in wrangling distributed data. Aligning the operating model of the data tier and application tier ensures smooth scaling / autoscaling.

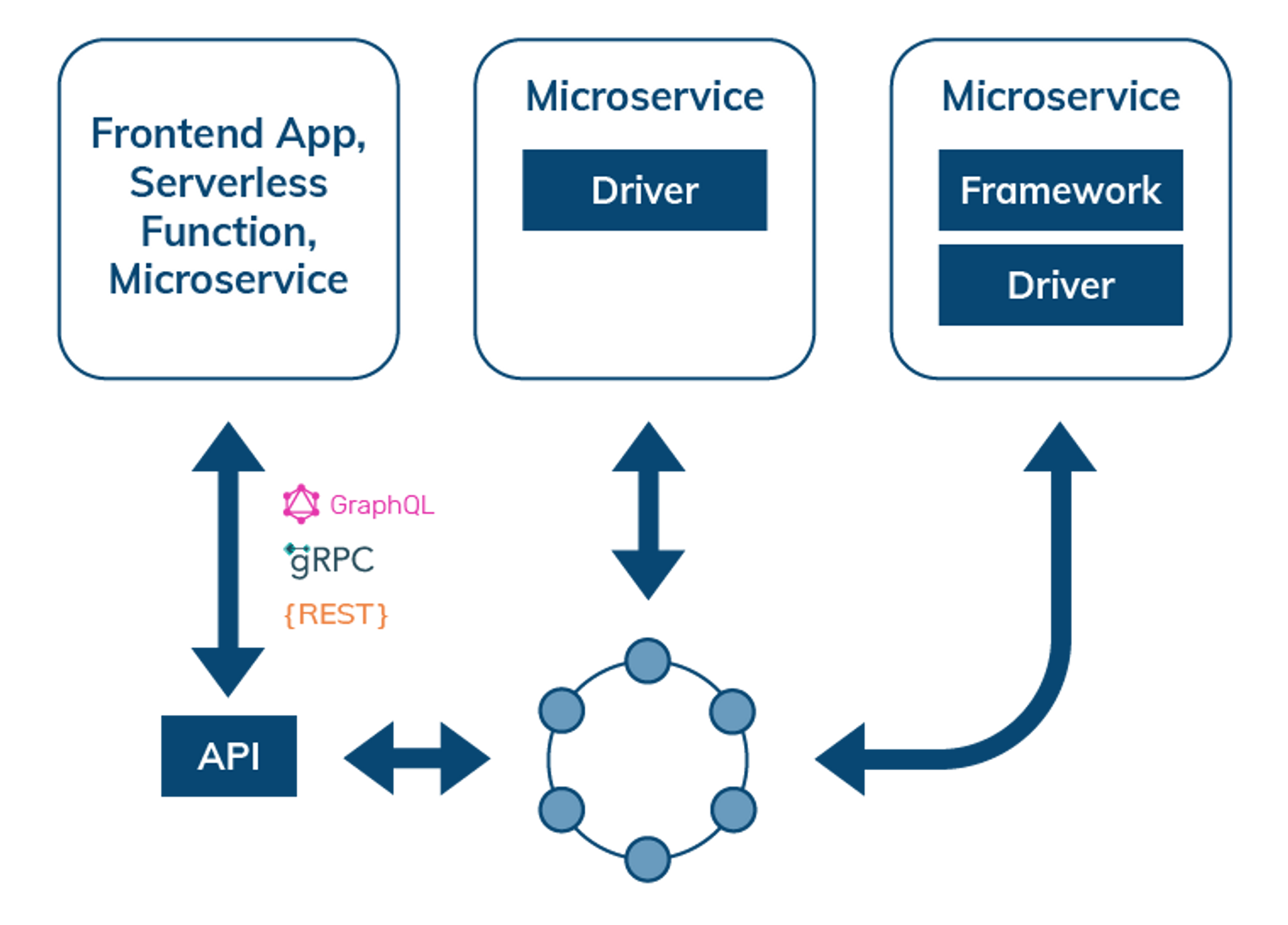
Data Access through APIs, data API gateways, drivers, and frameworks
When interacting with a distributed database, such as Cassandra, the simplest way to access data is through data-service APIs described in GraphQL, REST, or gRPC. This mode of interaction is useful for frontend applications, serverless functions, or microservice architecture. Microservices that need more control over their interactions with the backend database can be coded directly using a driver, or use a language SDK and/or integration for frameworks such as Spring Boot, Quarkus, Node.js, Express.js, Django, or Flask. APIs also enable Jamstack and frontend developers using React.js, Angular, JS, Vue.js to provide persistent storage for their applications.
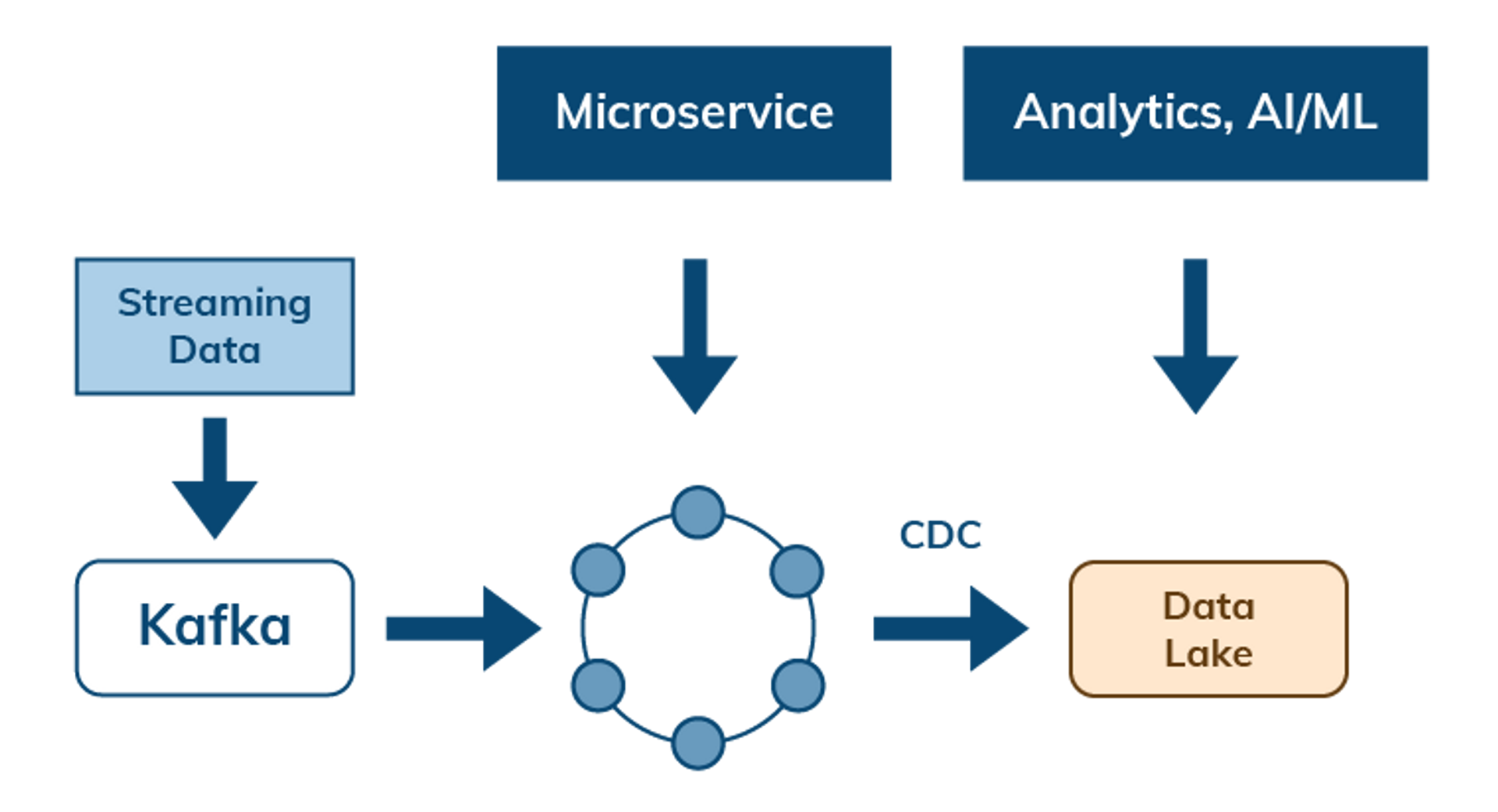
Manage data flow with streaming and change data capture
Cloud-native architectures also need to address the flow of data between services and APIs. Data can flow from streaming and messaging systems such as Apache Pulsar and Kafka into Cassandra as a system of record for access by microservices. Change data capture (CDC) enables data flows out of Cassandra to other services or to a data lake to enable further analysis.
Cloud based vs.
Cloud native vs.
Cloud enabled
Cloud-enabled databases
As with applications that are not fully cloud native, cloud-enabled databases are not specifically designed to run in distributed environments atop immutable infrastructure. A minimal cloud-enabled design will not depend on locally-attached storage, and therefore can run on virtualized hardware or an IaaS. However, they will have limited ability to shard data or run in a cluster, particularly in concert with a virtualization layer underneath the database that is controlled by a cloud or container platform. This prevents cloud-enabled databases from being deployed in a highly-available or fault-tolerant manner that is automated and self-healing. Compute, storage and other functions are all likely part of the same monolithic database server process. A cloud-enabled database still depends on vertical, not horizontal scalability.
Cloud-based databases
Similar to a cloud-based application, this represents a deeper (re)design for the cloud where you start to see the shift from vertical to horizontal scalability. A cloud-based database can shard and is cluster aware, and it’s most likely eventually consistent. It is still a monolithic database server process and is not auto-scaling. They are typically not priced by the database operation, and are likely tied to the specific gigabyte hour rates of particular cloud VM instance types or reserved instances.
Cloud native: Serverless, auto scaling data
To even approach becoming a fully serverless DBaaS, the monolithic database server must be broken apart. Let’s examine a database like Apache Cassandra, which enjoys a significant advantage, as it’s partition tolerant to begin with.
What are some technical challenges that potentially need to be accounted for?
- Separating database functions like coordination, reads, writes, compaction, and repair into independent processes
- Removing any dependency on locally attached storage
- Dealing with latency incurred by the above separation(s)
- Handling security at the disk, process, and network level boundaries for these newly separated processes
- Emitting, collecting, monitoring and storing the right telemetry for billing, by the operation
- Re-engineering to leverage K8s—native structures and subsystems (e.g etcd)
- Leveraging other K8s–native structures for workload orchestration, automated remediation, and leader delegation
You can imagine how a database not already inherently partition-tolerant would have significantly bigger challenges, or simply would be unable to affect this architecture change at all. For a cloud-native database, these serverless transition challenges are difficult, but not insurmountable.
With microservices architecture and multi-tenancy in place, the final missing piece of the serverless puzzle is auto scaling. Auto scaling is a hard optimization problem that looks to minimize the total cost of computational resources while meeting the continuously changing demand of every tenant. This is definitely about scaling up the services when demand is high. But, when demand decreases, scaling back down is just as important for cost effectiveness. Auto scaling enables database service elasticity, which boils down to how many operations per second a tenant currently needs.
There are numerous considerations and dimensions that a cloud-native database has to take into account for auto scaling purposes:
- Different component services have unique characteristics and requirements for healthy operation
- Horizontal scaling is always the primary scaling mechanism. In addition, different services can have different default operations-per-second rate limits that can be dynamically tuned for each tenant.
- Some workloads may seem to be fluctuating and unpredictable. Others may exhibit well-defined periodic patterns that can help predict future demand.
- Scaling of services for individual tenants is needed, while the system also has to scale its total operational capacity across all tenants.
- Different scaling measures are required under abnormal circumstances, such as huge demand spikes or large-scale cloud outages.
- Decisions to scale and scaling actions should be very fast to support real-time applications.
At DataStax, we built Astra DB to have a serverless design of elasticity and auto scaling. This required our team to develop a suite of auto scaling policies, strategies, heuristics, and predictive models to support it.