A Beginner's Guide to Benchmarking with NoSQLBench

David Jones-GilardiDeveloper Relations Engineer

This is Part 3 of a six-part series on Apache Cassandra®. In the last post, we discussed advanced data modeling. Now, we’ll use our open-source benchmarking tool, NoSQLBench, to benchmark and stress test NoSQL databases.
Operators and developers benchmark and stress test their data models regularly. With mission-critical infrastructure like Apache Cassandra®, it’s standard practice, especially before going to production.
There are several benchmarking tools in the market but most of them require esoteric coding knowledge. NoSQLBench is simple to use while providing sophisticated benchmarking for Cassandra and other NoSQL databases. It provides results within minutes.
In this post, you’ll get hands-on experience with benchmarking and stress testing Cassandra using NoSQLBench. Rather than going in-depth, our tutorial will scratch the surface and cover:
- Understanding parameters and key metrics for benchmarking
- How cycles, bindings and statements work together
- Experimenting with stdout
- Scaling up a test and customizing your own scenarios
- Packaging a performance test with named scenarios
What is NoSQLBench?
NoSQLBench is an open-source, pluggable testing tool for the NoSQL ecosystem. It’s primarily designed to test Cassandra, but you can also use it for other NoSQL technology like Apache Kafka, MongoDB, and DataStax Astra DB.
NoSQLBench evolved from the internal testing tool at DataStax, dsbench. It made a quantum leap in testing abilities for the Cassandra community. Engineers and customers were using it for performance testing, data model design, sizing, and deployment of new clusters.
After we completed dsbench, we turned it into an open-source project, so the NoSQL community could improve it further. NoSQLBench now integrates with different kinds of workloads and protocols, including CQL support.
If you’d like to contribute to the project in any way, including mentoring and code reviews, let us know on Twitter.
Why should you benchmark your data models?
Companies handle massive traffic everyday on their sites as consumers spend more time online. Benchmarking ensures your data models can handle unexpected spikes without breaking down.
It’s critical to test your data model before going into production. It lets you understand how your system behaves and performs as it scales, before you release it into the world.
Highly experienced data operators learn to gauge signals and metrics without performing a benchmark. For everyone else however, testing your data models is imperative – especially if you like to play it safe.
NoSQLBench with Cassandra exercises
The benchmarking exercises take roughly two hours to complete. They contain preconfigured scenarios on Katacoda, resources on GitHub, and step-by-step instructions in this YouTube video. We handled the Cassandra backend so you can focus entirely on NoSQLbench.
In the hands-on exercises, you will:
- Run your first NoSQLBench benchmark against Cassandra with pre-packaged data models
- Investigate NoSQLBench metrics from Cassandra using Grafana and Prometheus
- Create your custom workloads to benchmark with NoSQLBench
Exercise 1: Executing NoSQLBench commands against Cassandra
The first exercise shows you how to execute NoSQLBench commands against Cassandra with pre-packaged data models. You can follow this exercise manually using GitHub or to run this Katacoda scenario.
If you’re doing this manually, set up Docker through this 0-setup readme first. Docker is an open-source virtualization software that automates deployment of software applications inside containers. Once your Docker is running, start a Cassandra database and download NoSQLBench as a jar file.
We strongly recommend that you create a directory to use with NoSQLBench and download it there. This will make it easier for you to organize the many files that you’ll generate during these exercises. Follow along our video tutorial or this GitHub link to complete the exercises below:
- Execute an initial run of your NoSQLBench commands
- Create a test schema
- Write initial ramp-up data
- Perform a benchmark test
- Analyze the results
Exercise 2: Investigate NoSQLBench metrics from Cassandra with Grafana
In this exercise, you’ll view and analyze the metrics in charts and graphs on Grafana. Grafana is an open-source analytics and interactive visualization application. You can also run this Katacoda scenario or get the code for this section on GitHub. Follow the instructions in this video.
Here’s what you need to do for this exercise:
- Export metrics to Grafana
- Launch Grafana
- View various metrics
- Launch Prometheus and view metrics in more detail
When you’ve completed these steps, we can look at four types of metrics on Grafana and what they represent:
- Ops and successful ops: this graph indicates the operation rate (reads/writes per second) of the benchmark. There should be no discrepancies between ops and success metrics
- Error Counts: if there are discrepancies between ops and success metrics, you will see errors here. Ideally, there shouldn’t be any
- Service Time distribution: service time measures how quickly your NoSQL database responds to requests coming in from the client’s application server
- Op tries distribution: this graph shows the tries or retries it took to execute your operation. If there are too many retries, your database is overloaded, which warrants an investigation immediately
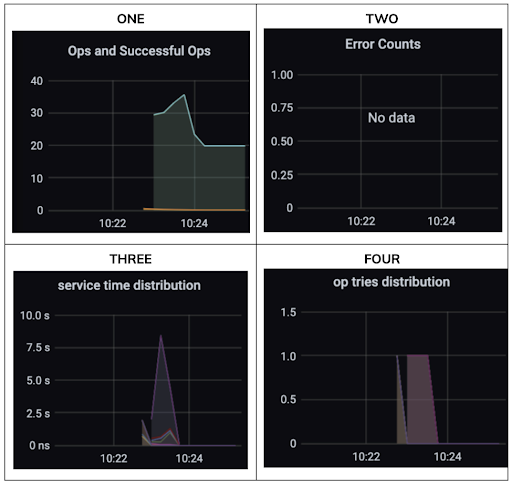
Figure 1. Four types of metrics on Grafana.
Exercise 3: Customizing workloads in NoSQLBench
In the previous exercises, you used pre-packaged workloads to run the NoSQLBench commands. Now, we’ll guide you to create custom workloads for your own application or database. This section is optional but recommended.
To get started, run this Katacoda scenario or use the code on GitHub. Find detailed instructions in this video and complete these steps:
- List workloads and named scenarios
- Copy workloads
- Build your own workload
- Combine everything into a single workload file
Conclusion
You’re already halfway through our Cassandra series. If you want to keep learning, be on the lookout for our upcoming Part 4 where we'll dive into Storage-Attached Indexes. Then to finish off strong, in Part 5 and Part 6 we'll show you how to migrate your SQL applications to NoSQL and give you a hands-on exercise.
Our Definitive Cassandra Guide will also be incredibly useful to learn everything that you need to know about Cassandra.
Check out our YouTube channel for tutorials and DataStax Developers on Twitter for the latest news about our developer community.
Resources
- DataStax NoSQLBench
- YouTube Tutorial: Benchmark your NoSQL Database
- Astra DB: Multi-cloud DBaaS built on Apache Cassandra
- NoSQLBench Learning Series for Apache Cassandra by DataStax
- NoSQL Bench Workshop Online GitHub
- DataStax Academy
- DataStax Community
- Definitive Cassandra Guide by DataStax
- Apache Pulsar Performance Testing with NoSQLBench
What is NoSQLBench?
Why should you benchmark your data models?
NoSQLBench with Cassandra exercises
Exercise 1: Executing NoSQLBench commands against Cassandra
Exercise 2: Investigate NoSQLBench metrics from Cassandra with Grafana
Exercise 3: Customizing workloads in NoSQLBench
Conclusion
Resources
More Technology
View All
Introducing the DataStax AI Terraform Module


