GigaOm: Astra DB smashes Pinecone in Four Key Vector Database Benchmarks

Joshua Norrid

Vector databases must deliver on four key metrics to successfully enable accurate generative AI and RAG (retrieval augmented generation) applications in production: throughput, latency, F1 relevancy, and total cost of ownership (TCO).
Since we introduced DataStax Astra DB vector search earlier this year, we’ve been working to make this critical functionality as developer-friendly as possible, focusing on high relevance and production readiness for GenAI and RAG applications.
We commissioned analyst firm GigaOm to benchmark Astra DB vector performance and TCO with several commonly-used vector benchmarking datasets that simulate production conditions. GigaOm then compared Astra DB performance to Pinecone, a widely used vector database.
The GigaOm "Vector Databases Compared" study finds that Astra DB performed significantly better than Pinecone; specifically, up to:
- 9x higher throughput than Pinecone when ingesting and indexing data
- 74x faster P99 query response time when ingesting and indexing data
- 20% higher F1 relevancy
- 80% lower total cost of ownership over a three-year period in three scenarios
You can read the report here. Before we dive into the results, let’s dive into the common vector database benchmarks used to gauge performance.
Understanding vector database benchmarks
One of the simplest ways to understand how a solution will stand up to real world deployment and use is through performance benchmarking. Benchmarking can be done to evaluate the general performance, scalability and overall operational thresholds of a given solution. When it comes to vector databases, there functionally five areas of performance that are relevant for doing a vector database comparison:
- Throughput
- Latency
- Query Execution Time
- Relevancy
- Scalability
Throughput
Throughput is the measurement of how much data can move through the system. When it comes to vector databases, throughput is important because it provides a clear picture of how the database will perform under load. One of the key observations from throughput testing is how the system operates under both read and write load. Many benchmarks try to isolate performance by looking at just read performance and/or just write performance, and while those metrics have relevance the real test is how the system operates while doing both reads and writes.
Latency
The second area of focus is latency. The challenge with latency is that it can be highly relative to the application. Low latency for a web application versus low latency for an algorithmic trading application are two completely different metrics. Because vector databases are typically at the core of generative AI systems and because they typically deal with applications that have been built around natural language processing and conversational human interaction, latency becomes extremely relevant. When an operation (read/write/index) is executed the end to end time to complete the operation needs to be executed in milliseconds, not seconds.
Query execution time
The query execution time plays a major role in the latency of the end-to-end system response time. One of the most important operations of a vector database is to search and retrieve information and the majority of the end-to-end system latency is encapsulated in the ability of the databases to efficiently find and retrieve the relevant information. Being able to quickly find and process the right information is key to a natural response for generative AI.
Accuracy/relevance
While latency and query execution time are extremely important, doing something fast but not accurately defeats the purpose. One of the biggest challenges in generative AI applications today is providing accurate results and reducing hallucinations. Unlike traditional database operations, vector databases enable semantic or similarity search, which is non-deterministic in nature. Because of this the results returned for the same query can be different depending on the context and how the search process is executed. This is where accuracy and relevance play a key role in how the vector database operates in real world applications, real world natural interaction requires that the results returned on a similarity search are first accurate and second relevant to the requested query. If I query what other flights are available from JFK to LGA for today, I don’t want a response with flights from JFK to ORD or flights for tomorrow or the day after.
Scalability
While throughput, latency, and relevance are extremely important, those all have impacts on near-term operations. The last metric that needs to be considered is scalability. Scalability provides the ability to the database to maintain predictable performance and operation as load increases and query complexity increases. The vector store has to have the ability to grow both horizontally and vertically as the applications requirements and demands increase.
Vector database comparison: Evaluating Astra DB vs Pinecone on key benchmarks
When you look at the vector database options available, there are a number of different approaches. Standalone, multi-functional, and traditional databases have been built or incorporated vector functionality. When evaluating a vector database there are a number of factors that come into play, how the database will support operational functionality beyond vector, how will the database incorporate contextual structured and unstructured data, and how it will perform. In this report we focused purely on the 4 most important vector database performance metrics.
Throughput
High throughput ensures rapid data ingestion and indexing, enabling real-time data processing and quick query responses that are crucial in GenAI and RAG applications.
GigaOm tested this capability by generating vectors and labels, inserting them into databases, and executing queries of various types, including nearest neighbor, range, KNN classification, KNN regression, and vector clustering.
The tests found that Astra DB indexes data up to 6x faster than Pinecone. Astra DB concurrently ingests and indexes data up to 9x faster than Pinecone.
Astra DB exhibits a lower relative variance, making the ingest workflow more predictable for applications that need to perform in production scenarios.
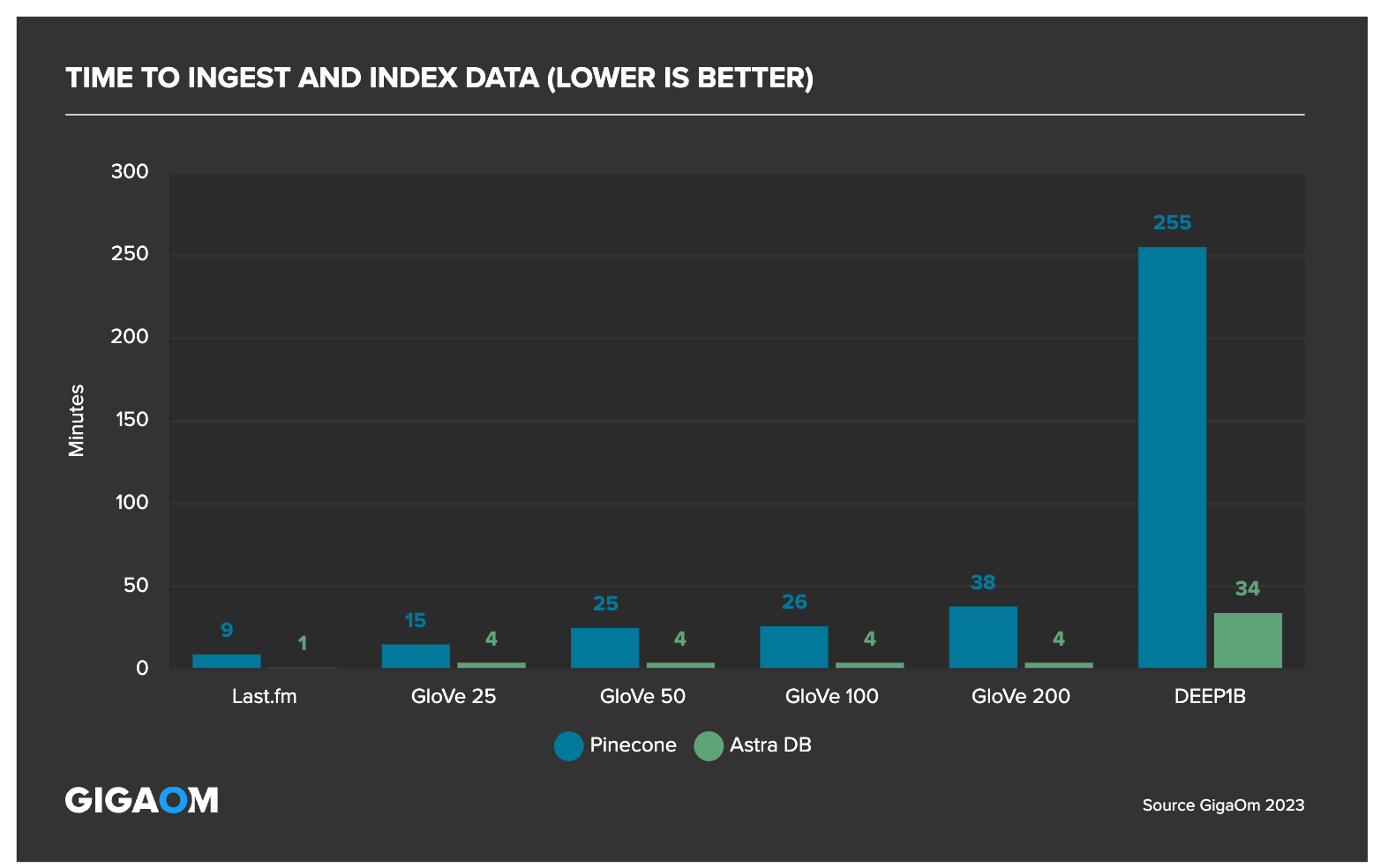
GigaOm also found that Astra DB ingests and indexes data (particularly large sets) for immediate availability, while with Pinecone, it “took some time” before data was searchable.
Latency
Lower latency means faster retrieval of information, which is vital for applications that require immediate data processing and real-time decision-making. This is different from throughput, which measures how much data can be processed over a time period.
During active indexing, Astra DB delivered up to 6x faster query responses versus Pinecone during indexing and 7.4x faster query responses while ingesting and indexing concurrently.
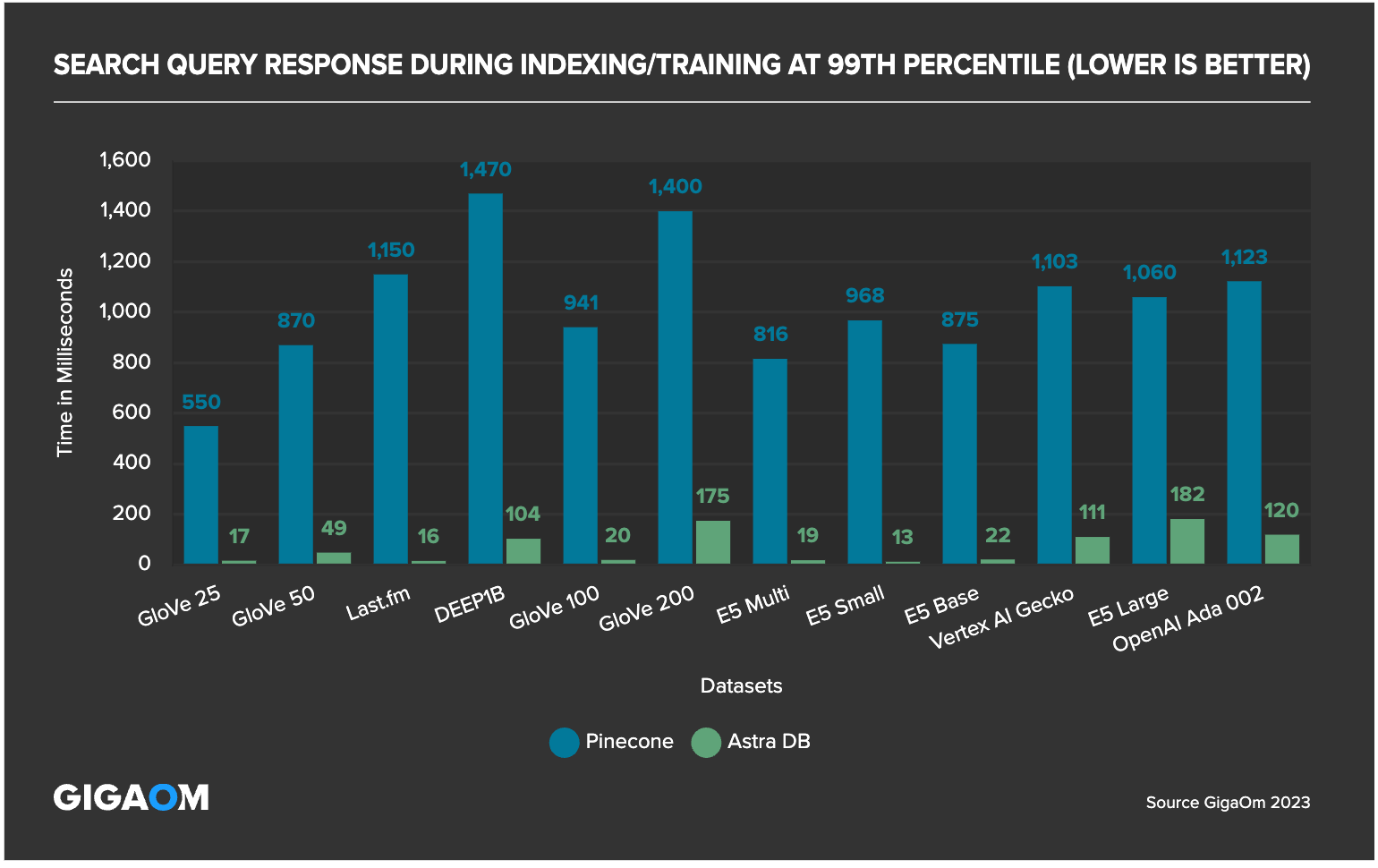
Low latency and high throughput are especially important with emerging new RAG techniques such as FLARE and ReAct that synthesize multiple queries per end-user response to reduce hallucinations.
Relevance
F1 relevancy is described as the harmonic mean between both precision and recall.
GigaOm found that during active indexing, Pinecone's recall ranged between 75% to 87%. It noted that Pinecone had instances of recall as low as 23% in certain tests, particularly with larger datasets. Astra DB never scored below 90% and demonstrated a recall range from 90% to 94% during active indexing. More details and charts can be found in the report.
Total cost of ownership (TCO)
GigaOm found that Astra DB had up to an 80% lower total cost of ownership compared to Pinecone based on three scenarios of updating production data either monthly, weekly, or in real-time. This was calculated over a three-year period, factoring in elements like administrative burden, staffing needs, and operational efficiency.
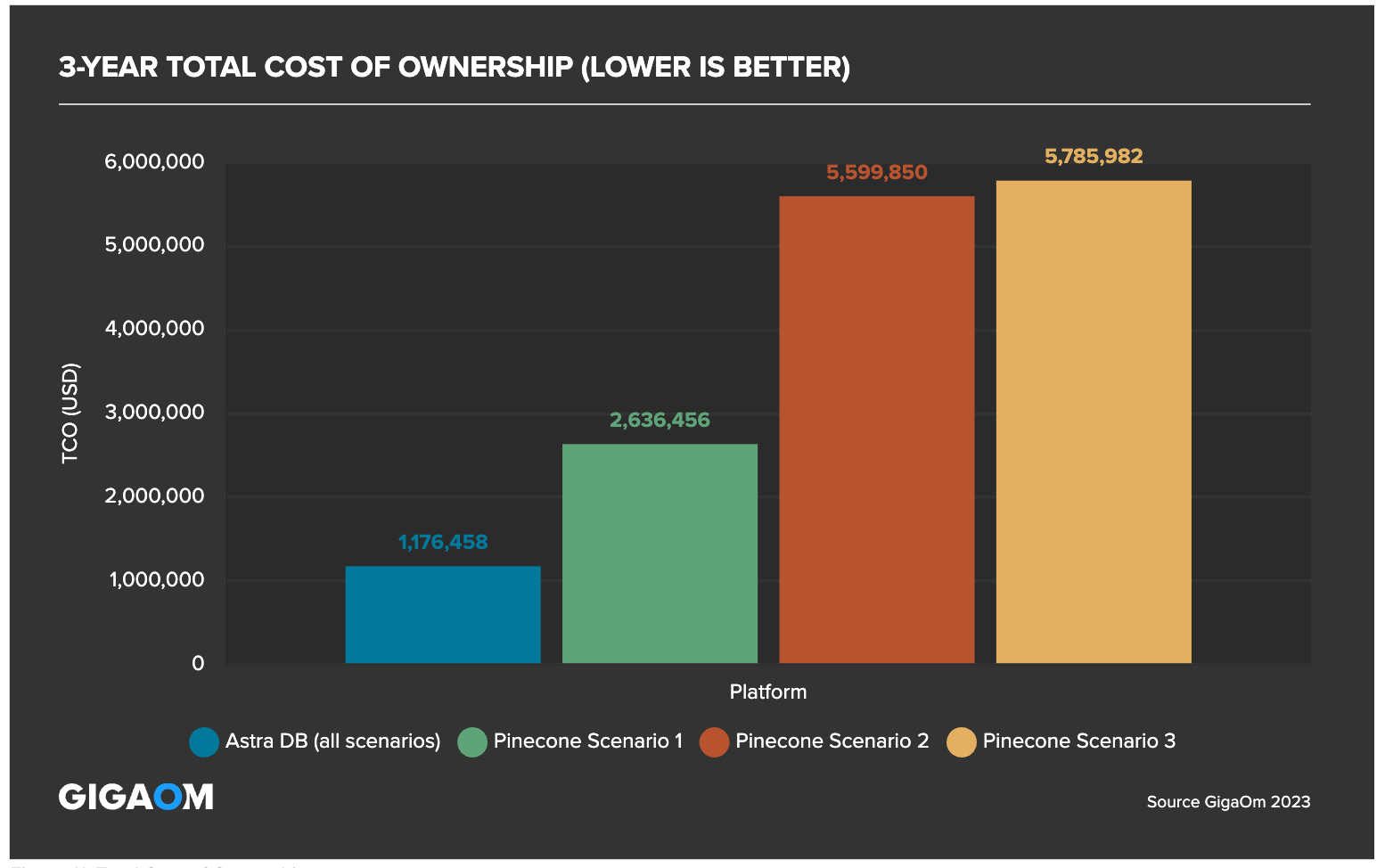
Why choose DataStax over Pinecone? The results speak for themselves
Benchmarks can be useful to assess performance, but every use case differs based on the unique characteristics of each production environment. We are completely focused on innovating vector search to help every developer use GenAI to impact the trajectory of their enterprise.
We encourage you to create a free Astra DB vector database and conduct your own assessment of its ease-of-use, relevancy, and production-readiness for your GenAI and RAG applications.
Read GigaOm’s report, "Vector Databases Compared."
Understanding vector database benchmarks
Throughput
Latency
Query execution time
Accuracy/relevance
Scalability
Vector database comparison: Evaluating Astra DB vs Pinecone on key benchmarks
Throughput
Latency
Relevance
Total cost of ownership (TCO)
Why choose DataStax over Pinecone? The results speak for themselves
More Technology
View All
Introducing the DataStax AI Terraform Module


