Want to move to no ops Astra DB with no downtime? No problem!

Alice LottiniVanguard Architect, DataStax

Sundar Balasubramanian

Jeff DiNoto

If you are an enterprise that has been undergoing digital transformation, today you are entering a critical step: data modernization. Whether building new modern applications or moving existing workloads to the cloud, you don’t want to leave data behind and continue using legacy databases that compromise performance and business agility. You want to take advantage of a new breed of database-as-a-service that offers your development teams zero operational headaches and the agility to bring new applications faster to market.
If you are wise enough to already be running Apache Cassandra® workloads on prem, you may want to consider DataStax Astra DB, a Database-as-a-Service (DbaaS) built around Cassandra that offers many additional benefits. You don’t have to worry about operations or maintenance; you can choose which cloud vendor you want to work with without the worry of getting locked in; it autoscales out or in with your demand; and most importantly you pay only for what you use. In fact, according to a GigaOm study, you can save up to 75% in TCO using Astra DB compared to running Cassandra on your own.
Eliminating operational overhead and saving costs are all great reasons for moving workloads. However, it is a serious undertaking that often gives people pause before making the big step. Many hesitate to pull the trigger because workload migration typically involves some downtime, which is very disruptive to the business. Fear no more. DataStax’s Zero Downtime Migration product can help you move any existing Cassandra workloads to Astra DB without any business interruptions.
In fact, while this tool fully addresses the needs of those interested in adopting Astra DB, its flexible design enables it to be deployed outside Astra DB to help workload migration between any Cassandra compatible origin and target clusters, such as:
Cassandra ⇄ Cassandra
Cassandra ⇄ DataStax Enterprise
DataStax Enterprise ⇄ DataStax Enterprise
Now let’s explore how it works.
How it works
At a high level, we use a proxy that provides dual-write capabilities between two clusters. In the scenario discussed here, a self-managed (origin) cluster and Astra DB (target). The proxy ensures that all write requests are executed against both clusters and that reads are executed against the origin. This way, while in operation, the client application continues to operate as if it’s only interacting with the origin cluster. Later in the process, reads can be switched over to the target cluster, so that this becomes the primary source of truth while the origin is still kept up-to-date for easy rollback purposes.
While it functioned in much the same way as this next generation of the tool does, the initial version was too attached to Astra DB. As Astra DB has evolved to better suit the needs of our users, so too has the proxy. We thought long and hard, and changed the deployment model of the proxy so that it can now support migrations to serverless Astra DB as well as other potential use-cases.
Here is a high-level diagram of the proxy deployment reference architecture for migration, highlighting the proxy at the center of the system.
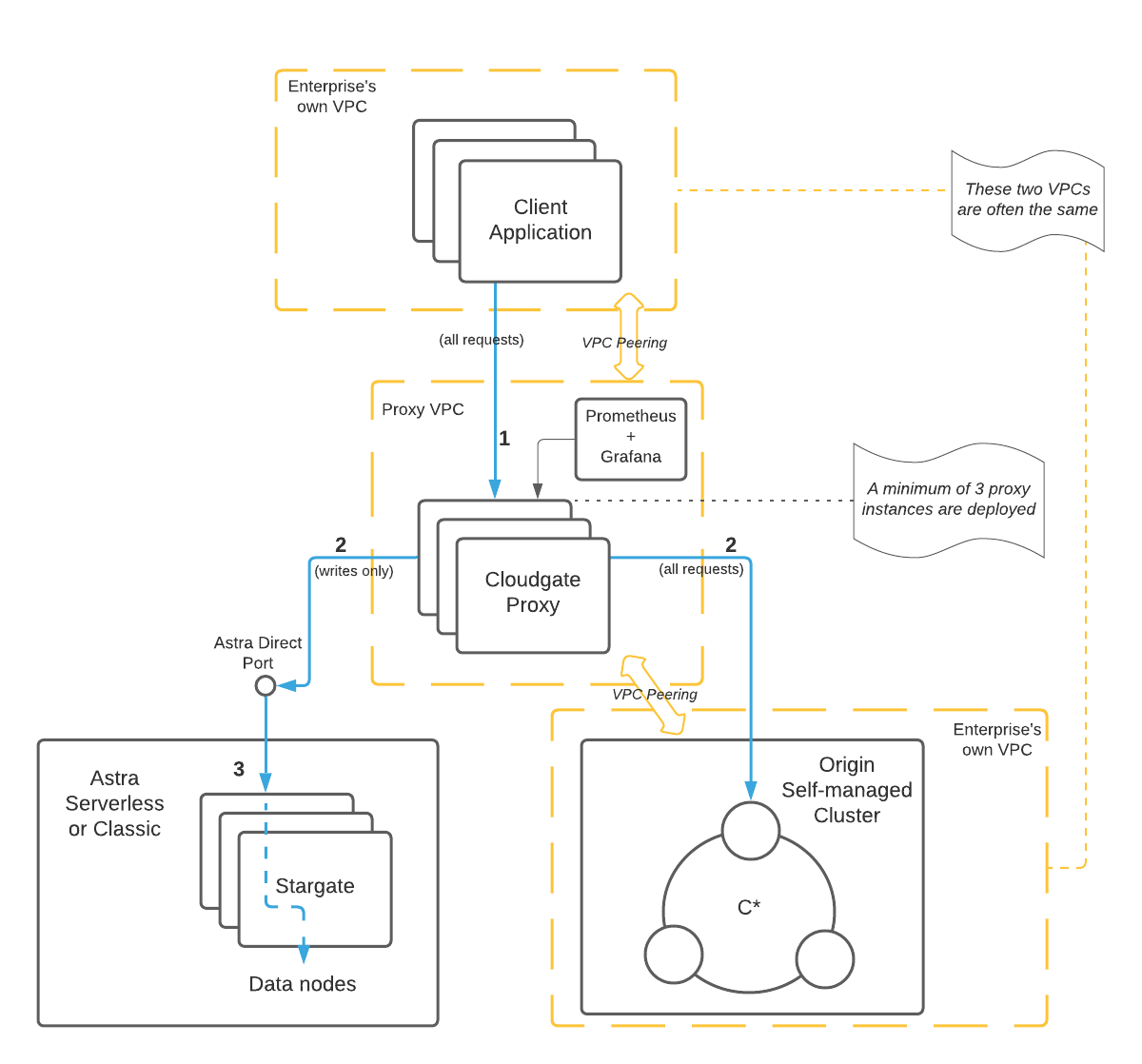
One of the key changes with this generation of the proxy is its ability to be deployed outside of the Astra infrastructure—closer to the client application. This is important for a few reasons:
- It makes the proxy more flexible; the proxy can be deployed in multiple types of environments and support different types of migrations.
- It puts users in control, as they can make decisions about deployment that are effective and efficient for their application to improve security and performance.
- It simplifies and standardizes the interaction with Astra, because the proxy now connects to Astra just like any other application client would, using a Secure Connect Bundle.
It’s also worth noting that the proxy has been designed as a stateless service that can be scaled horizontally to provide several benefits:
- High availability - multiple instances of the proxy should be deployed to provide redundancy for a now critical piece of the application infrastructure.
- Consistent performance - additional instances of the proxy can be deployed in situations where an increased number of connections must be handled, providing for more consistent performance under heavy load.
Easy deployment
While a major goal of this generation of the proxy is deployment flexibility, we also want to make the developer and operator experience as positive as possible. To that end, along with the proxy itself, we are also delivering some automation that will help not only with the deployment of the proxy itself, but also the infrastructure and networking used to deploy it within.
Specifically in this release, the following automation tools are made available:
- Terraform modules for AWS infrastructure deployment
- Ansible playbooks for infrastructure-agnostic proxy deployment and configuration
We chose Terraform and Ansible because they are best-of-breed tools which are well-known, simple to install, and can be run anywhere.
It’s important to note that while we believe this automation can help set the stage for a successful migration experience, it’s totally optional, and there’s nothing about the proxy implementation that prevents a completely bespoke deployment approach.
The modular design incorporated into the automation tooling allows the operator to pick and choose from the tooling that best suits their environment. For example, if infrastructure and connectivity are already established, the Ansible playbooks can be used on their own to target that existing infrastructure. This can leave the operator in total control of their infrastructure while still getting a turnkey proxy deployment experience. The Ansible playbooks can also be used to change the configuration of the proxy deployment, another key feature that the automation provides.
Deploy with best practices built-in
One of the benefits of taking advantage of the automation we’ve built is that it creates a best-practices-driven infrastructure environment that can make management easier over time.
The infrastructure automation provided via Terraform lays out a foundation for deployment that includes a number of noteworthy features:
- Monitoring capabilities - resources are deployed that provide metric collection and dashboarding visualization of the deployed proxy instances.
- Network segmentation - resources are deployed into their own VPC that can only be accessed through peering configurations, limiting network access and making the system more secure. Peering is performed automatically, making the experience simple and quick.
- Resource isolation - because resources are deployed in an isolated environment, once the migration process is complete those resources can be torn down without a risk to other existing infrastructure.
Conclusion
The Zero Downtime Migration tool is proof of DataStax‘s continued investment in making it frictionless for enterprises and users to adopt and upgrade to Astra DB in their quest to become more agile and develop innovative applications with a no-ops modern data platform, while at the same time reducing TCO. The tool is capable of helping you move any Cassandra workloads to Astra DB; indeed, between any Cassandra-compatible source and target.
Consistent with DataStax’s open data stack philosophy, we are planning to open source the proxy codebase later this year to make it available to anyone looking to improve their ability to migrate applications between clusters and infrastructure while still delivering a consistent application experience for their users. As the project evolves, we hope that through collaboration with the community we can expand these capabilities and add a needed tool to the belt for operators of C* clusters of many flavors.
For now, get a move on and contact us to schedule a free initial consultation about Zero Downtime Migration with our professional services group. We will help you develop a comprehensive strategy and assist with migrating your Cassandra workloads.
More Company
View All


Introducing Tejas Kumar, Developer Relations Engineer
