Introducing DSE Graph Frames

Artem Aliev

The DseGraphFrame package provides the Spark base API for bulk operations and analytics on DSE Graph. It is inspired by Databricks’ GraphFrame library and supports a subset of Apache TinkerPop™ Gremlin graph traversal language. It supports reading of DSE Graph data into a GraphFrame and writing GraphFrames from any format supported by Spark into DSE Graph.
The package ties DSE Analytics and DSE Graph components together even stronger than it was before! Spark users will have direct access to the Graph and Graph users will be able to perform bulk deletes, updates and have an advanced API for faster scanning operations.
In this blog post I will cover the main DseGraphFrame advantages and operations:
- Importing DSE Graph data into Spark DataFrames and GraphFrames
- Updating or deleting Vertex and Edges in DSE Graph
- Inserting Edges
- Inserting Vertices with custom ids.
- Combining Graph and non-graph data
- Update graph element properties
- Spark Streaming
- Join with any Spark supported sources
- API support for graph manipulation and graph algorithms:
- Spark GraphFrames https://graphframes.github.io/graphframes/docs/_site/index.html
- A Subset of TinkerPop3 Gremlin http://tinkerpop.apache.org/docs/current/reference
- Data Loading from various sources including Apache Cassandra®, JDBC, DSEFS, S3
DseGraphFrame has both Java and Scala Spark APIs at this moment.
Table of contents:
DSE Graph
DSE Graph is built with Apache TinkerPop and fully supports the Apache TinkerPop Gremlin language. A Graph is a set of Vertices and Edges that connect them. Vertices have a mandatory unique id. Edges are identified by two ends inV() and outV(). Both Edges and Vertices have labels that define type of the element and a set of properties.
Create Example
Let’s create a toy "friends" graph in gremlin-console, that will be used in following examples:
Start DSE server with graph and spark enabled.
#> dse cassandra -g -k
Run gremlin console
#> dse gremlin-console
Create empty graph
system.graph("test").create()
Create a short alias ‘g’ for it and define schema
:remote config alias g test.g
//define properties
schema.propertyKey("age").Int().create()
schema.propertyKey("name").Text().create()
schema.propertyKey("id").Text().single().create()
//define vertex with id property as a custom ID
schema.vertexLabel("person").partitionKey("id").properties("name", "age").create()
// two type of edges without properties
schema.edgeLabel("friend").connection("person", "person").create()
schema.edgeLabel("follow").connection("person", "person").create()
Add some vertices and edges
Vertex marko = graph.addVertex(T.label, "person", "id", "1", "name", "marko", "age", 29)
Vertex vadas = graph.addVertex(T.label, "person", "id", "2", "name", "vadas", "age", 27)
Vertex josh = graph.addVertex(T.label, "person", "id", "3", "name", "josh", "age", 32)
marko.addEdge("friend", vadas)
marko.addEdge("friend", josh)
josh.addEdge("follow", marko)
josh.addEdge("friend", marko)
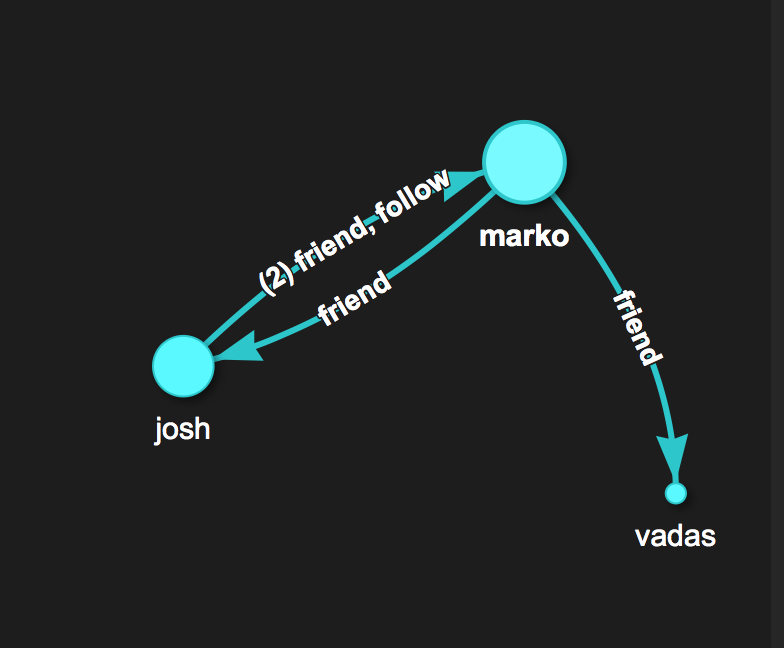
You can use DataStax Studio for visualizations and to run commands instead of gremlin-console.
http://docs.datastax.com/en/dse/5.1/dse-dev/datastax_enterprise/studio/stdToc.html
DSE Graph OLAP
DSE Graph utilises the power of the Spark engine for deep analytical queries with Graph OLAP. It is easily accessed in gremlin console or Studio with ‘.a’ alias:
:remote config alias g test.a
DSE Graph OLAP has broader support for TinkerPop than the DseGraphFrame API. While Graph OLAP is the best for deep queries (those requiring several edge traversals), simple filtering and counts are much faster in the DseGraphFrame API
.gremlin> g.V().has("name", "josh").out("friend").out("friend").dedup()
==>v[{~label=person, id=2}]
==>v[{~label=person, id=3}]
DseGraphFrame
DseGraphFrame represents a Graph as two virtual tables: a Vertex DataFrame and an Edge DataFrame.
Let’s see how the graph looks in Spark:
#> dse spark
scala> val g = spark.dseGraph("test")
scala> g.V.show
+---------------+------+---+-----+---+ | id|~label|_id| name|age| +---------------+------+---+-----+---+ |person:AAAAAjEx|person| 1|marko| 29| |person:AAAAAjEz|person| 3| josh| 32| |person:AAAAAjEy|person| 2|vadas| 27| +---------------+------+---+-----+---+
scala>g.E.show
+---------------+---------------+------+--------------------+ | src| dst|~label| id| +---------------+---------------+------+--------------------+ |person:AAAAAjEx|person:AAAAAjEy|friend|29ea1ef0-139a-11e...| |person:AAAAAjEx|person:AAAAAjEz|friend|2d65b121-139a-11e...| |person:AAAAAjEz|person:AAAAAjEx|friend|33de7dc0-139a-11e...| |person:AAAAAjEz|person:AAAAAjEx|follow|33702b91-139a-11e...| +---------------+---------------+------+--------------------+
DseGraphFrame uses a GraphFrame-compatible format. This format requires the Vertex DataFrame to have only one ‘id’ column and the Edge DataFrame to have hardcoded ‘src’ and ‘dst’ columns. Since DSE Graph allows users to define any arbitrary set of columns as the Vertex id and since there is no concept of `labels` in GraphFrame, DseGraphFrame will serialize the entire DSE Graph id into one ‘id’ column. The label is represented as part of the id and also as ‘~label’ property column.
DseGraphFrame methods list:
| gf() | returns GraphFrame object for graph frame API usage |
| V() | returns DseGraphTraversal[Vertex] object to start TinkerPop vertex traversa |
| E() | returns DseGraphTraversal[Edge] object to start TinkerPop edge traversal |
| cache() persist() |
cache the graph data with Spark |
| deleteVertices() deleteEdges() |
delete vertices or edges |
| deleteVertexProperties() deleteEdgeProperties() |
delete properties from the DB. It doesn’t change schema. |
| updateVertices() updateEdges() |
change properties or insert new vertices and edges. |
DseGraphFrameBuilder
DseGraphFrameBuilder is a factory for DseGraphFrame.
Java API
is the same excluding graph initialization
//load a graph
DseGraphFrame graph = DseGraphFrameBuilder.dseGraph("test", spark);
//check some vertices
graph.V().df().show()
Scala API
A Scala implicit adds the factory dseGraph() method to a Spark session, so the Scala version is shorter:
// load a graph
val graph = spark.dseGraph("test_graph")
//check some vertices
graph.V.show
Spark GraphFrame
Java API
Use DseGraphFrame.gf() to get GraphFrame.
DseGraphFrameBuilder.dseGraph(String graphName, GraphFrame gf) method to return back to DseGraph
Scala API
Scala provides implicit conversions from GraphFrame to DseGraphFrame and back. It also converts GraphTraversals to DataFrames.So both GraphFrame filtering and TinkerPop traversal methods can be mixed.
TinkerPop3 Gremlin Support
The DseGraphFrame API supports a limited subset of the Gremlin language that covers basic traversal and update queries. TinkerPop traversals are generally more clear and intuitive compared to the GraphFrame motif search queries, so we recommend using Gremlin if possible.
See example of finding all Josh’s friends of friends:
//TinkerPop Gremlin in spark shell
scala>g.V.has("name", "josh").out("friend").out("friend").show
//GraphFrame motif finding is less readable
scala>g.find("(a)-[e]->(b); (b)-[e2]->(c)").filter(" a.name = 'josh' and e.`~label` = 'friend' and e2.`~label` = 'friend'").select("c.*").show
Both outputs are the same, but Gremlin looks much shorter and more readable.
+---------------+------+---+-----+---+ | id|~label|_id| name|age| +---------------+------+---+-----+---+ |person:AAAAAjEz|person| 3| josh| 32| |person:AAAAAjEy|person| 2|vadas| 27| +---------------+------+---+-----+---+
List of Gremlin query methods supported by DseGraphFrame:
| Step | Method |
| CountGlobalStep | count() |
| GroupCountStep | groupCount() |
| IdStep | id() |
| PropertyValuesStep | values() |
| PropertyMapStep | propertyMap() |
| HasStep | has(), hasLabel() |
| IsStep | is() |
| VertexStep | to(), out(), in(), both(), toE(), outE(), inE(), bothE() |
| EdgeVertexStep | toV(), inV(), outV(), bothV() |
| NotStep | not() |
| WhereStep | where() |
| AndStep | and(A,B) |
| PageRankVertexProgramStep | pageRank() |
Bulk Drop and Property Updates
DseGraphFrame is currently the only way to drop millions of vertices or edges at once. It is also much faster for bulk property updates than other methods. For example to drop all ‘person’ vertices and their associated edges:
scala>g.V().hasLabel("person").drop().iterate()
List of Gremlin update methods supported by DseGraphFrame:
| DropStep | V().drop(),E().drop(),properties().drop() |
| AddPropertyStep | property(name, value, ...) |
The Traverser concept and side effects are not supported.
Java API
The DseGraphFrame V() and E() methods returns a GraphTraversal, this is a java interface, so all methods exists but some of them throw UnsupportedOperationException. The GraphTraversal is a java iterator and also has toSet() and toList() methods to get query results:
//load a graph
DseGraphFrame graph = DseGraphFrameBuilder.dseGraph("test", spark);
//print names
for(String name: graph.V().values("name")) System.out.println(name);
To finish a traversal and return to the DataFrame API instead of list or iterator use the .df() method:
graph.V().df()
Scala API
DseGraphFrame supports implicit conversion of GraphTraversal to DataFrame in scala.The following example will traverse Vertices with TinkerPop and then show result as DataFrame
scala>g.V().out().show
In some cases the Java API is required to get correct TinkerPop objects.
For example, to extract the DSE Graph Id object the Traversal java iterator can be converted to a scala iterator which allows direct access to the TinkerPop representation of the Id. This method allows using the original Id instead of DataFrame methods which return the DataFrame String representation of the Id, you can also use toList() and toSet() methods to get appropriate id set
.scala> import scala.collection.JavaConverters._
scala> for(i <-g.V().id().asScala) println (i)
{~label=person, id=1}
{~label=person, id=3}
{~label=person, id=2}scala> g.V.id.toSet
res12: java.util.Set[Object] = [{~label=person, id=2}, {~label=person, id=3}, {~label=person, id=1}]
Logical operations are supported with TinkerPop P predicates class
g.V().has("age", P.gt(30)).show
T.label constant could be used to point label
g.E().groupCount().by(T.label).show
Note: Scala is not always able to infer return types, especially in the spark-shell. Thus to get property values, the type should be provided explicitly:
g.V().values[Any]("name").next()
//or
val n: String = g.V().values("name").next()
The same approach is needed to drop a property from the spark-shell. To query property before drop you should pass the type of the property ‘[Any]’:
g.V().properties[Any]("age", "name").drop().iterate()
The Dataframe method looks more user friendly in this case:
scala> g.V().properties("age", "name").drop().show()
++
||
++
++
scala> g.V().values("age").show()
+---+
|age|
+---+
| 29|
DseGraphFrame updates
Spark has various sources. As far as you can get this data as DataFrame that has ‘id’, ‘~label’ and one or more properties column you can load this date into the graph. Format the DataFrame to proper format and call one of the update methods:
val v = new_data.vertices.select ($"id" as "_id", lit("person") as "~label", $"age")
g.updateVertices (v)
val e = new_data.edges.select (g.idColumn(lit("person"), $"src") as "src", g.idColumn(lit("person"), $"dst") as "dst", $"relationship" as "~label")
g.updateEdges (e)
Spark Streaming Example
DataFrame could come from any sources even from Spark streaming. You just need to get DataFrame in an appropriate format and call updateVertices or updateEdges:
dstream.foreachRDD(rdd => {
val updateDF = rdd.toDF("_id", "messages").withColumn("~label", lit("person"))
graph.updateVertices(updateDF)
})
Full source code of the streaming application could be found here
GraphX, GraphFrame and DataFrame
DseGraphFrame can return a GraphFrame representation of the graph with the DseGraphFrame.gf() methods. That give you access to all GraphFrame and GraphX advanced algorithms. It also allows you to build sophisticated queries that are not yet supported by the DseGraphFrame subset of the TinkerPop API.A DseGraphTraversal can return its result as a DataFrame with the df() method. In the Scala API an implicit conversion is provided for conversion from traversal to DataFrame, so all DataFrame methods are available on the DseGraphTraversal.
scala> g.V.select(col("name")).show
+-----+
| name|
+-----+
|marko|
| josh|
|vadas|
+-----+
GraphFrame Reserved Column Names
GraphFrame uses the following set of columns internally:"id", "src", "dst", "new_id", "new_src", "new_dst", "graphx_attr"TinkerPop properties with these names will be prepended with "_" when represented inside a GraphFrame/DataFrame.
Querying DSE Graph with SparkSQL
Spark data sources allow one to query graph data with SQL. There are com.datastax.bdp.graph.spark.sql.vertex and com.datastax.bdp.graph.spark.sql.edge for vertices and edges.The result tables are in Spark GraphFrame compatible format. To permanently register tables for Spark SQL or JDBC access (via the Spark SQL Thriftserver), run the following commands in a `dse spark-sql` session:
spark-sql> CREATE DATABASE graph_test;
spark-sql> USE graph_test;
spark-sql> CREATE TABLE vertices USING com.datastax.bdp.graph.spark.sql.vertex OPTIONS (graph 'test');
spark-sql> CREATE TABLE edges USING com.datastax.bdp.graph.spark.sql.edge OPTIONS (graph 'test');
In addition to operating on the graph from Spark via Scala, Java, and SQL, that method allows you to query and modify the graph from Spark Python or R:
Scala
#>dse spark
scala> val df = spark.read.format("com.datastax.bdp.graph.spark.sql.vertex").option("graph", "test").load()
scala> df.show
PySpark
#>dse pyspark
>>> df = spark.read.format("com.datastax.bdp.graph.spark.sql.vertex").load(graph = "test")
>>> df.show()
SparkR
#>dse sparkR
> v <- read.df("", "com.datastax.bdp.graph.spark.sql.vertex", graph="test")
>head(v)
Export Graph
A DseGraphFrame is represented as two DataFrames, so it is easy to export DSE Graph data to any format supported by Spark.
scala> g.V.write.json("dsefs:///tmp/v_json")
scala> g.E.write.json("dsefs:///tmp/e_json")
This will create two directories in the DSEFS file system with vertex and edge data in JSON formatted in text files.
You can copy the data to the local filesystem (if there is capacity):
#>dse hadoop fs -cat /tmp/v_json/* > local.jsonor use the data for offline analytics, by loading it back from DSEFS:val g = DseGraphFrameBuilder.dseGraph("test", spark.read.json("/tmp/v.json"), spark.read.json("/tmp/e.json"))
Export to CSV
Spark CSV does not support arrays or structs. This means that multi-properties and properties with metadata must be converted before exporting.
For example: let "nicknames" column be a multi property with metadata, it will be represented as array(struct(value, metadata*)))
To save it and id you will need following code:
val plain = g.V.select (col("id"), col("~label"), concat_ws (" ", col("nicknames.value")) as "nicknames")
plain.write.csv("/tmp/csv_v")
Importing Graph Data into DSE Graph
DseGraphFrame is able to insert data back to DSE Graph. The parallel nature of Spark makes the inserting process faster than single-client approaches. The current DseGraphFrame API supports inserting only to Graphs with a Custom ID and the process is experimental in DSE 5.1.
Limitations: Custom ID only! Graph schema should first be created manually in gremlin-console.
Import previously exported graph
- Export schema:
In the gremlin-console:
gremlin> :remote config alias g gods.g
gremlin> schema.describe()
Copy the schema and apply it to new graph:
system.graph('test_import’').create()
:remote config alias g test_import.g
// paste schema here
- Back to spark and import V and E
val g = spark.dseGraph("test_import")
g.updateVertices(spark.read.json("/tmp/v.json"))
g.updateEdges(spark.read.json("/tmp/e.json"))
Import custom graph
Let’s add data into our test graph. I will use a GraphFrame example graph which has a similar structure to to our graph schema. I will tune the schema to be compatible and then update our graph with new vertices and edges.
scala> val new_data = org.graphframes.examples.Graphs.friends
It consists of two DataFrames. Let’s check schemas:
scala> new_data.vertices.printSchema
root
|-- id: string (nullable = true)
|-- name: string (nullable = true)
|-- age: integer (nullable = false)
scala> new_data.edges.printSchema
root
|-- src: string (nullable = true)
|-- dst: string (nullable = true)
|-- relationship: string (nullable = true)
Open our graph and check the expected schema.
scala> val g = spark.dseGraph("test")
scala>g.V.printSchema
root
|-- id: string (nullable = false)
|-- ~label: string (nullable = false)
|-- _id: string (nullable = true)
|-- name: string (nullable = true)
|-- age: integer (nullable = true)
scala>g.E.printSchema
root
|-- src: string (nullable = false)
|-- dst: string (nullable = false)
|-- ~label: string (nullable = true)
|-- id: string (nullable = true)
The labels need to be defined for vertices and some id columns need to be renamed. Vertex serialized IDs will be calculated by DSE Graph, but an explicit mapping using the idColumn() function is required for Edge fields ‘src’ and ‘dst’.
val v = new_data.vertices.select ($"id" as "_id", lit("person") as "~label", $"name", $"age")
val e = new_data.edges.select (g.idColumn(lit("person"), $"src") as "src", g.idColumn(lit("person"), $"dst") as "dst", $"relationship" as "~label")
Append them in the graph:
g.updateVertices (v)
g.updateEdges (e)
This approach can be applied to data from any data source supported by Spark: JSON, JDBC, etc. Create a DataFrame, update schema with a select() statement (or other Spark transformations) and update the DSE Graph via updateVertices() and updateEdges().
TinkerPop and GraphFrame work together in DSE:
Table of contents:
DSE Graph
Create Example
DSE Graph OLAP
DseGraphFrame
DseGraphFrameBuilder
Java API
Scala API
Spark GraphFrame
Java API
Scala API
TinkerPop3 Gremlin Support
Bulk Drop and Property Updates
Java API
Scala API
DseGraphFrame updates
Spark Streaming Example
GraphX, GraphFrame and DataFrame
GraphFrame Reserved Column Names
Querying DSE Graph with SparkSQL
Scala
PySpark
SparkR
Export Graph
Export to CSV
Importing Graph Data into DSE Graph
Import previously exported graph
Import custom graph
More Company
View All


Introducing Tejas Kumar, Developer Relations Engineer
