What is vector search?
Vector search is a technique used in information retrieval and machine learning to find similar items in a dataset based on vector representations. It's commonly used for similarity search tasks
Vector search assists organizations in discovering linked concepts in search responses, rather than solely focusing on keywords. But how exactly does it work?

Vector search is a method in artificial intelligence and data retrieval that uses mathematical vectors to represent and efficiently search through complex, unstructured data.
The tech industry is buzzing right now with all of the potential and opportunities Predictive AI and Generative AI will bring with regards to how we interact with information. The way we engage, find, and search information is fundamentally going to change and it all is because AI/ML models have the ability to access extremely large datasets and use those datasets to make decisions and correlations.
At the center of this AI revolution is the concept of Vector Search, also known as nearest neighbor search, which powers AI models with the ability to find specific sets of information in a collection that are the most closely related to a prescribed query. Unlike traditional searching models that look to find exact matches of information like keyword matches, vector search represents data points as vectors, which have direction and magnitude, in a highly-dimensional space. With vector search, the individual dimensions define a specific attribute or feature and the search compares the similarity of the query vector to the possible vector paths that can and do traverse all of the dimensions. The implementation of a vector search engine in this domain marks a significant advancement, enabling more sophisticated and accurate searches through large and complex datasets.
Needless to say, the complexity of this can become quite daunting to try and comprehend. However, at the core of vector search is the ability to mathematically calculate the distance or similarity between vectors, and this is done with a number of mathematical formulas like cosine similarity or Euclidean distance.
Vector search works by associating similar mathematical representations of data, and vector representations, together and converting queries into the same vector representation. With both query and data represented as vectors, finding related data becomes a function of searching for any data representations that are the closest to your query representation, known as nearest neighbors. Unlike traditional search algorithms that use things like keywords, word frequency, or word similarity, vector search uses the distance representation embedded into the vectorization of the dataset to find similarity and semantic relationships.
As applications have gathered more and more information, how we categorize that information and how we access the value that information provides has been changing over time. Vector search is the latest evolution of how information is categorized and accessed. Like many transformative changes, vector search brings a whole new approach to unlocking power from the data we gather.
Vector search taps into the intrinsic value of categorizing data into high-dimensional vector spaces and captures the semantic value of that data, allowing for generative AI solutions the ability to extract the contextual relevance and create new relevant content based on that context. The usage of this contextual relevance that vector search brings can be applied across many different applications:
Vector search has changed the way we interact with data and ultimately has changed the value applications can extract from the datasets they use and gather. But with anything new there is always change and complexity that is introduced.
This concept of nearest neighbor is at the core of how vector search works and there are a number of different algorithms that can be used for finding nearest neighbors depending on how much compute resources you want to allocate and/or how accurate you are looking for your result to be. K-nearest neighbor algorithms (kNN) provide the most accurate results but also require the highest amount of computational resources and execution time to execute. For most use cases Approximate Nearest Neighbor (ANN) is preferred as it provides significantly better execution efficiency in high dimensional spaces at the cost of perfect accuracy of the results. This allows for vector search operations for things like Large Language Models or models that require extremely large datasets to operate at scale. With larger datasets, the sacrifice of result accuracy becomes less of an issue because more data yields better results especially if concepts like Hierarchical Navigable Small Worlds (HNSW) are used versus proximity graphs.
The way vector search calculates and uses nearest neighbor algorithms is by transforming all data into Vector Embeddings. A vector embedding in its most basic form is a mathematical representation of an object as a list of numbers. The complexity here is of course a little bit more involved because any object can be reduced to a list of numbers from a single word, a number, entire paragraphs, or entire books and documents. The purpose of this translation is that once in this numerical representation semantic similarity of objects now becomes a function of proximity in a vector space. This numerical translation is known as 'vector representation', which is crucial in defining how objects are positioned and compared within the multidimensional vector space. It's this vector representation that enables the precise calculation of similarity and difference between various data points.
A way to think about this is that once real-world objects are represented as a list of numbers they can be plotted on a multidimensional graph and depending on how close one object is to another determines how similar a given object is to another.
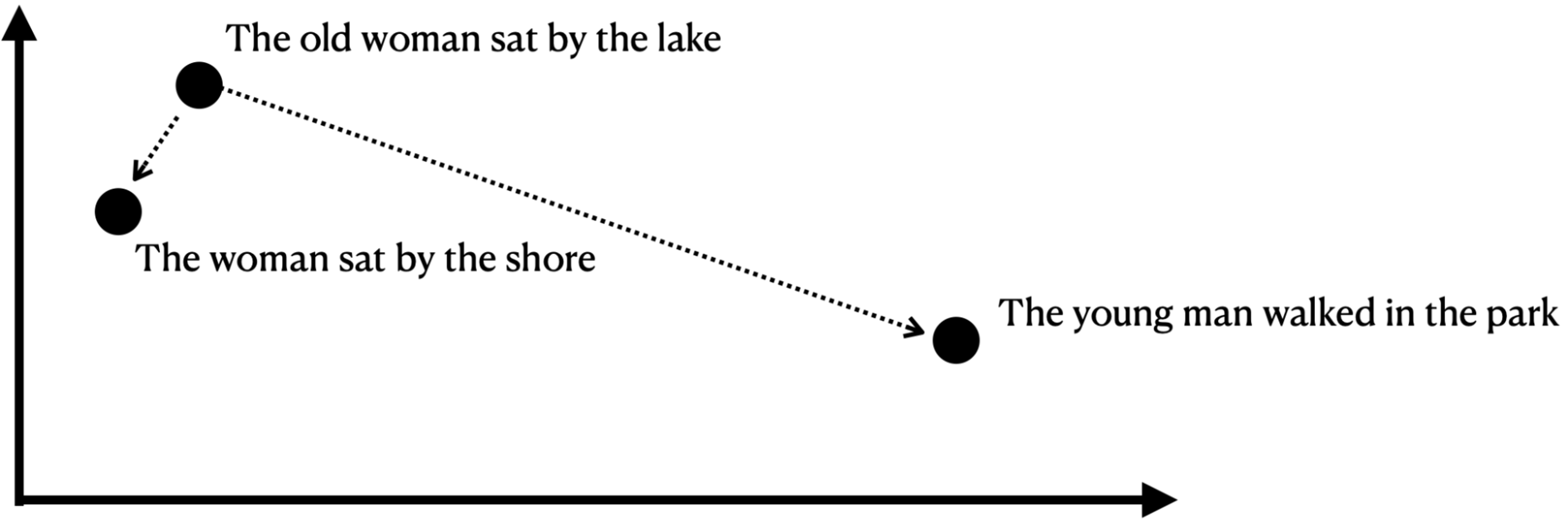
Vector embeddings provide the mathematical representation of objects and are what allow vector search the ability to determine semantic similarity. Once objects are stored as vectors they can be stored in a Vector Database which is purpose-built and designed to provide efficient storage and retrieval of large datasets of vector embeddings so that vector search operations can be used over extremely large datasets.
This is where the true power of vector search comes into play. Unlike traditional search that compares keywords or indexes, vector search provides the ability to compare the entirety of the query against the entirety of the data being searched and represent how closely each result is to the given query with context. This distinction highlights the superiority of how a vector search engine works in managing complex search queries, transcending the limitations of keyword-based traditional search systems. But what does this actually mean and what is its impact?
Where traditional keyword search has thrived is when exact results are requested. So if I know the specific details of what I am looking for then it is very easy for me to find it. This is why traditional relational databases create indexes for data access because it allows for a fast and efficient way to label data for easy look up. Take for example all the information for a given account, name, phone number, address, preferences, etc… Traditional search can yield a good result if you have one of these pieces of information readily available. But what if I knew of an upcoming service outage in a specific area and I wanted to do a more broadly scoped query like all accounts that are on a given street? Well, that type of search becomes more difficult with a traditional search because I don’t have an exact match. This is where the concept of similarity search becomes crucial, as vector search excels in identifying and retrieving information that is not just identical but semantically similar to the query
With vector search this type of query becomes a function of searching based on the street and finding all the data representations that are nearest to that query's vector embedding, yielding highly accurate results, quickly and efficiently. It is this ability to elastically compare and search these large data types that vector search is specifically designed for.
Efficiently finding and managing information lies at the core of our daily operations. With the rapid adoption of AI and machine learning, the utilization of Vector Databases, as well as the retrieval and search capabilities of Vector Search using Vector Embeddings, introduces novel possibilities for not just searching but also effectively handling and utilizing information.
The integration of vector search within machine learning models opens up a myriad of applications across various industries, enhancing the precision and efficiency of these models in processing large datasets. While vector search is ideally suited for obvious use cases like semantic search, it also enables a variety of applications with the potential to transform the industry as a whole. Probably the most talked about use case today is the ability to leverage vector databases and vector search for natural language processing (NLP) with the use of Large Language Models (LLMs). The ability to convert large volumes of documents to vector embeddings that can be searched using natural language enables customer interactions that are faster, more efficient, and more satisfying for end users because answers to questions can be serviced based on the closest match (neighbors) to the question asked. No longer does a developer have to search length documentation to understand how a function works, no longer does an end user have to search a FAQ to find how to use a specific feature of your product. Users can interact directly by asking questions that are vectorized and matched to their nearest neighbors providing detailed answers with immediate feedback.
Things like chatbots, recommendation engines, searching large volumes of unstructured data like audio, video, or IoT sensor data, and telemetry have all become a function of vector search, vector databases, and vector embeddings.
Take for example e-commerce where product recommendations can be tailored to specific requests over time. Context is important, history is important and with traditional search methods deriving that context can be difficult. With vector search, user preferences, interests, hobbies, and information can be built into the data representation that represents them and recommendations can be made based on close in similarity the result from their query matches their profile.
Take for example somebody searching for tennis balls. On the surface they are probably a tennis player but what if their profile says they don’t like playing sports? Maybe recommending tennis racquets isn’t exactly what they are looking for, but their profile does state they have 3 dogs. Ah…. So instead of recommending tennis racquets maybe recommending dog fetch toys is the more accurate result and by having objects represented as vectors this similarity-based matching becomes easy and customers get the results they want and intend quickly leading to higher satisfaction and user engagement.
Or what about finding information that is broader in scope than a specific query? Streaming services like Netflix and Youtube have popularized this concept with media consumption with the ability to discover new shows or content based on similar qualities to things you have watched in the past.
Take for example you are shopping for a new car to replace your existing SUV and you want to see all the options like a specific brand and model. With traditional search, you would get articles comparing that brand and model to other brands and models based on keywords but you have to do the leg work in trying to see how they compare. What if you are looking for a specific feature like a power liftgate or heated seats? With vector search, your query can be vectorized quickly compared against all the brand and model features and a recommendation for what brands and models have that feature can be returned quickly due to how near they are to your request. You get a fast response with accurate results without having to know the specific brands and models you might be interested in. The application of semantic search in content discovery platforms, powered by vector search, allows for a more personalized and intuitive user experience, as the system can better comprehend user interests and preferences.
Probably the most prominent use case today, however, is in Natural Language Processing. Solutions like ChatGPT have revolutionized how we interact with information and data and how that data is presented for use.
Prior to the ability to leverage vector search chatbots, virtual assistants and language translators all had to leverage keyword relations to provide information. But with vector search interactions can be conversational in nature because questions can be responded to with information that is semantically similar to what the query is asking.
For example, with traditional search somebody might search for a template for a memo about a new building dedication, but with vector search AI can write the memo for you under the constraints you provide by using natural language processing to complete the next word in the memo based on nearest neighbor vectors from similar documents process in an AI Large Language Model. Additionally, the use of similarity search in NLP applications allows for a more nuanced understanding and response to user queries, going beyond mere keyword matching to comprehend the intent and context of the query. It is this ability to relate like information in semantically similar searches that powers AI to complete and provide Natural Language Processing.
Leveraging vector search provides many benefits, such as:
While vector search has several benefits, there are also some limitations and challenges you should be aware of:
Like how vector databases provide the functional brain to AI, vector search provides the neural network for cognitive recall. Memories are stored as vectors in the brain, the vector database, and vector search provides the neural pathways to navigate, recall and associate those memories efficiently.
Whether you are looking to build natural semantic search into your application or build out a language processing engine to provide a more natural interaction with your users, vector search and a vector database provide the foundation for efficient data storage, access, and retrieval. Vector search provides the ability to access information quickly as it is needed in real-time so that the most relevant information that has been stored in the vector database can be serviced at the right time. Everyone has many memories buried deep in their brain of a time when something happened that caused us pain. Maybe it was that time we encountered a flying yellow and black bug with a stinger that we thought was friendly but learned was not. Being able to recall that memory quickly, efficiently and with context is what vector search provides to AI, it provides the contextual recall and retrieval of information as it is needed, in real-time and services that information to the right place at the right time. As we move forward, the refinement and enhancement of vector search technologies are expected to play a pivotal role in the evolution of machine learning models, enabling them to handle increasingly complex and diverse datasets with greater accuracy and efficiency.
With the rapid growth and acceleration of generative AI across all industries we need a purpose-built way to store the massive amount of data used to drive contextual decision-making. Vector databases have been purpose-built for this task and provide a specialized solution to the challenge of managing vector embeddings for AI usage. This is where the true power of a vector database coupled with vector search derives, the ability to enable contextual data both at rest and in motion to provide the core memory recall for AI processing.
While this may sound complex, Vector Search on AstraDB takes care of all of this for you with a fully integrated solution that provides all of the pieces you need for contextual data. From the nervous system built on data pipelines to embeddings all the way to core memory storage and retrieval, access, and processing in an easy-to-use cloud platform. Try for free today.
Vector search is a technique used in information retrieval and machine learning to find similar items in a dataset based on vector representations. It's commonly used for similarity search tasks
Vector search works by representing data items as vectors in a multi-dimensional space, where similarity is determined by the distance between these vectors. Items with closer vectors are considered more similar.
There are various applications of Vector search, including recommendation systems, image and text retrieval, natural language processing, and anomaly detection.
Vector search focuses on the similarity between items, while traditional keyword-based search relies on exact keyword matches. Vector search is more effective for tasks like finding similar images or documents.


