Automating Repair Operations in Cassandra with Reaper
Repairs are an essential part of managing Cassandra clusters in production. Repairs in small clusters may be done with nodetool at the command line. In large clusters or clusters that grow frequently it is very difficult to manage repairs with nodetool and cron. Kubernetes is a tool to manage complexity in large deployments. Reaper was made open source by Spotify and compliments Cassandra clusters running in Kubernetes because it simplifies the repair process at scale.

What Is A Repair
A repair, sometimes called an anti-entropy operation, is important for every Cassandra cluster. A repair synchronizes data between nodes.
Repairs compare data and the associated timestamps. As always in Cassandra, data with the latest timestamp wins.
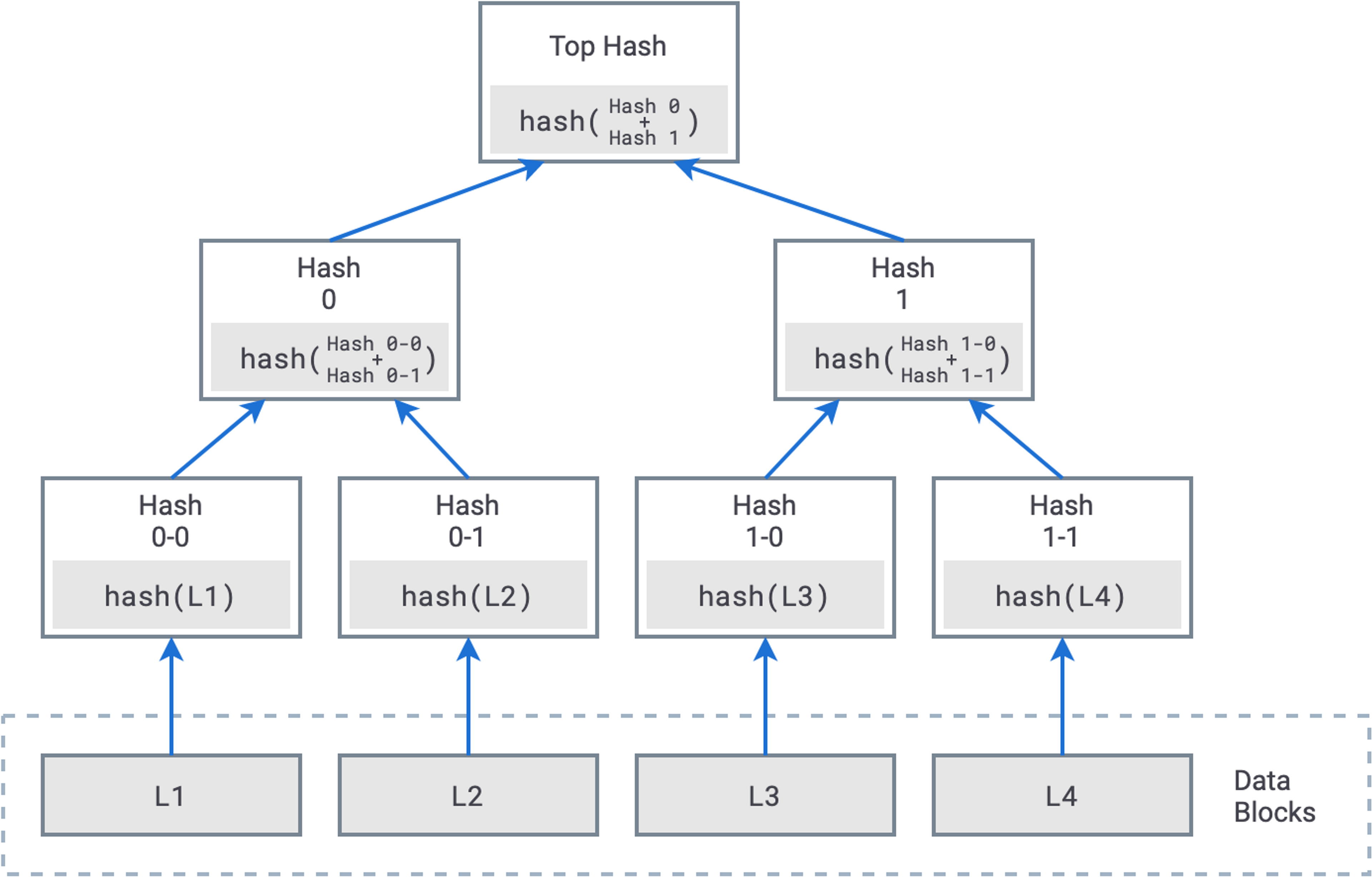
Cassandra uses Merkle Trees to allow for efficient data comparison. The leaf nodes of a Merkle Tree are hashes of the underlying data. The parent nodes are hashes of the concatenated child node hashes.
Using a Merkle Tree, Cassandra can quickly compare the high-level hashes. If they match there is no need to traverse down to the leaf nodes. If they do not match, Cassandra only needs to traverse until a match is found.
Cassandra can run different types of repairs:
- incremental (default)
- full
- keyspace
- table(s)
In general, repair should be run more frequently than the tombstone expiry period (gc_grace_seconds in cassandra.yaml.
Next: Why Repair?Why Repair?
Cassandra is designed to be highly available. Users can access a Cassandra cluster even if nodes fail. When a node fails, users can still read, write, update and delete data.
When a failed node returns to the cluster, it will be out of sync with any of the changes that occured while it was offline. Hinted Hand-off may help because it keeps hints on disk to inform failed nodes of changes. Read-Repair also helps. Likewise deletes are marked in the cluster with tombstones.
The problem is that both hints and tombstones expire. If a node is offline long enough neither hints nor tombstones will be available when it re-joins the cluster.
Repairs are important for every Cassandra cluster in production.
Next: Walking Dead Data


Walking Dead Data
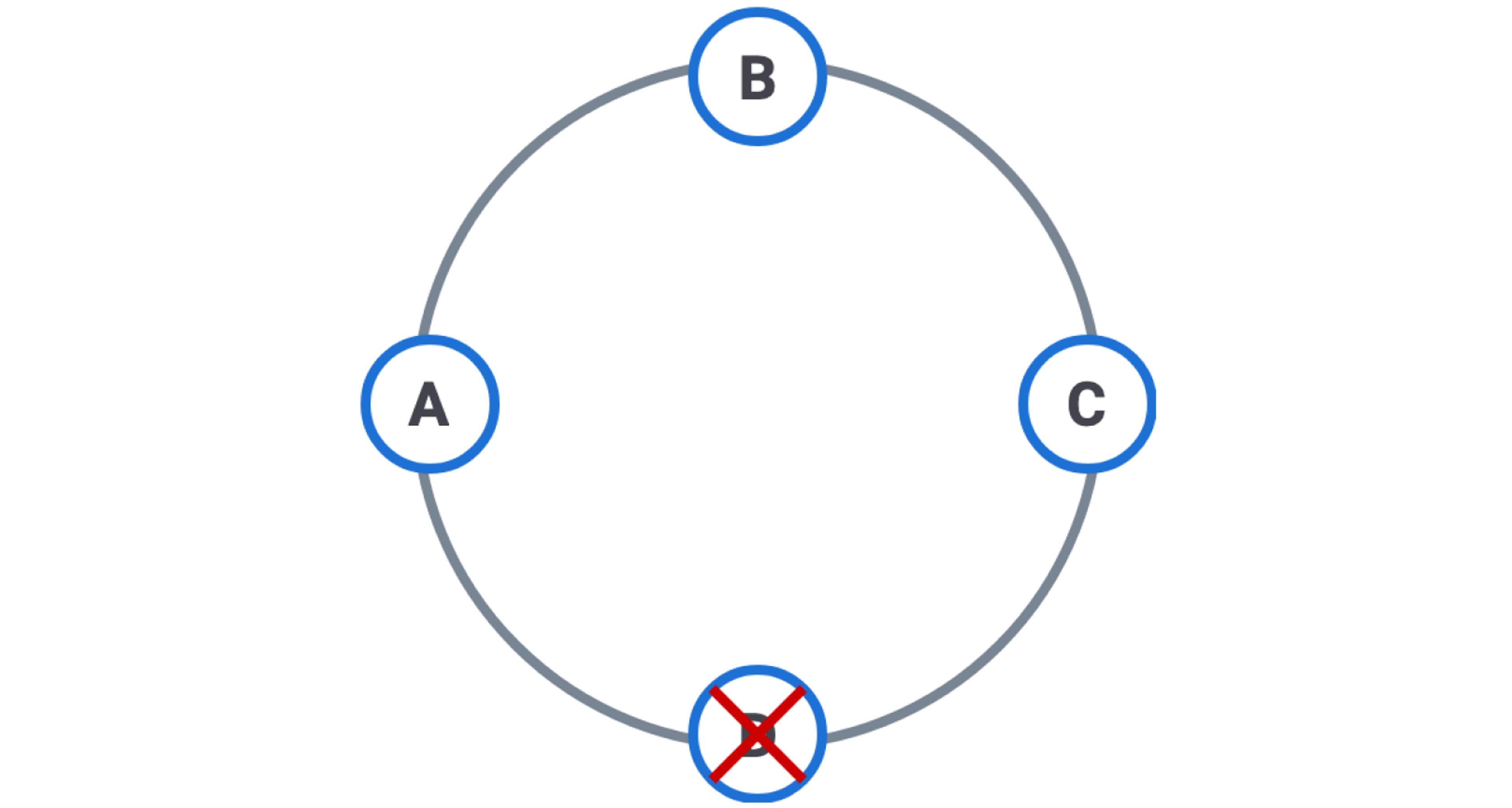
Zombies! If you do not perform repairs in a timely manner, you may end up with zombies in your data. These zombies are not walking about looking for humans to eat, but they are just as damaging to your data.
A number of things have to happen to create a zombie.
- A request is made to delete a row
- A node with a replica of the row is offline
- A Tombstone is inserted into the online replicas
- A hint is stored for the delete
- The hint expires
- The tombstone is removed
- The replica node restarts
When the next repair operation occurs, Cassandra will see the row on the re-started replica node. Since there are no tombstones for the row, Cassandra will assume that the replica has the current data. Cassandra will copy the data to the other replica nodes. The data was deleted but now it is alive again in the cluster.
(Default expiry for hints is 3 hrs and for tombstones is 10 days.)
Next: Repair with nodetoolRepair With Nodetool
The primary tool for repairs in Cassandra is nodetool. Nodetool is a command line tool that can initiate all of the supported types of repairs.
Next: Why Reaper?

Why Reaper?
Reaper is more capable than nodetool alone. Reaper can:
- split repair jobs into smaller, tunable segments
- handle back-pressure (monitor repairs and compactions so as not to overload the cluster)
- pause, cancel, resume and monitor inlight repairs
Reaper comes with a web-based UI and REST API.
Next: Reaper ConfigurationReaper Configuration
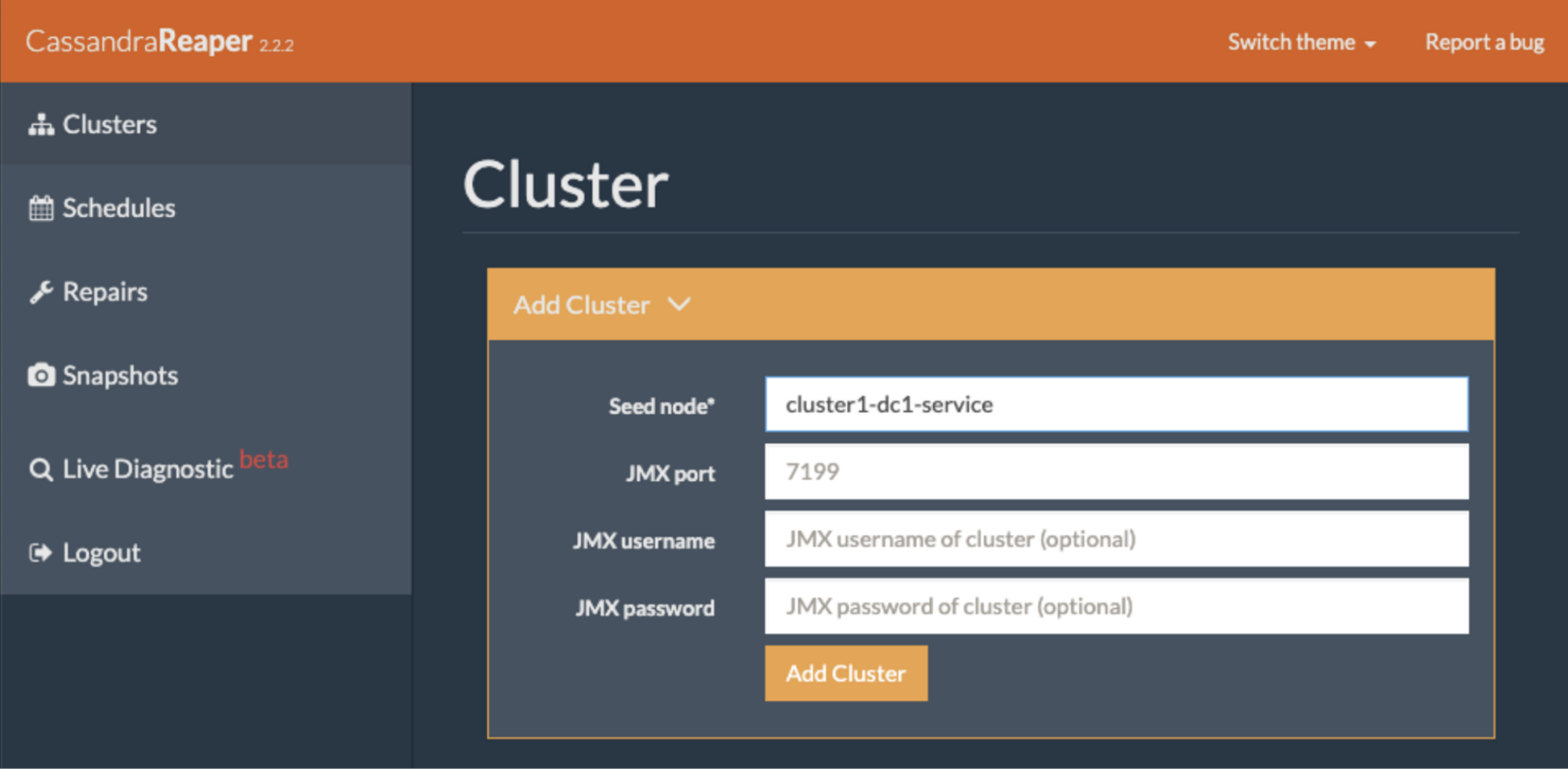
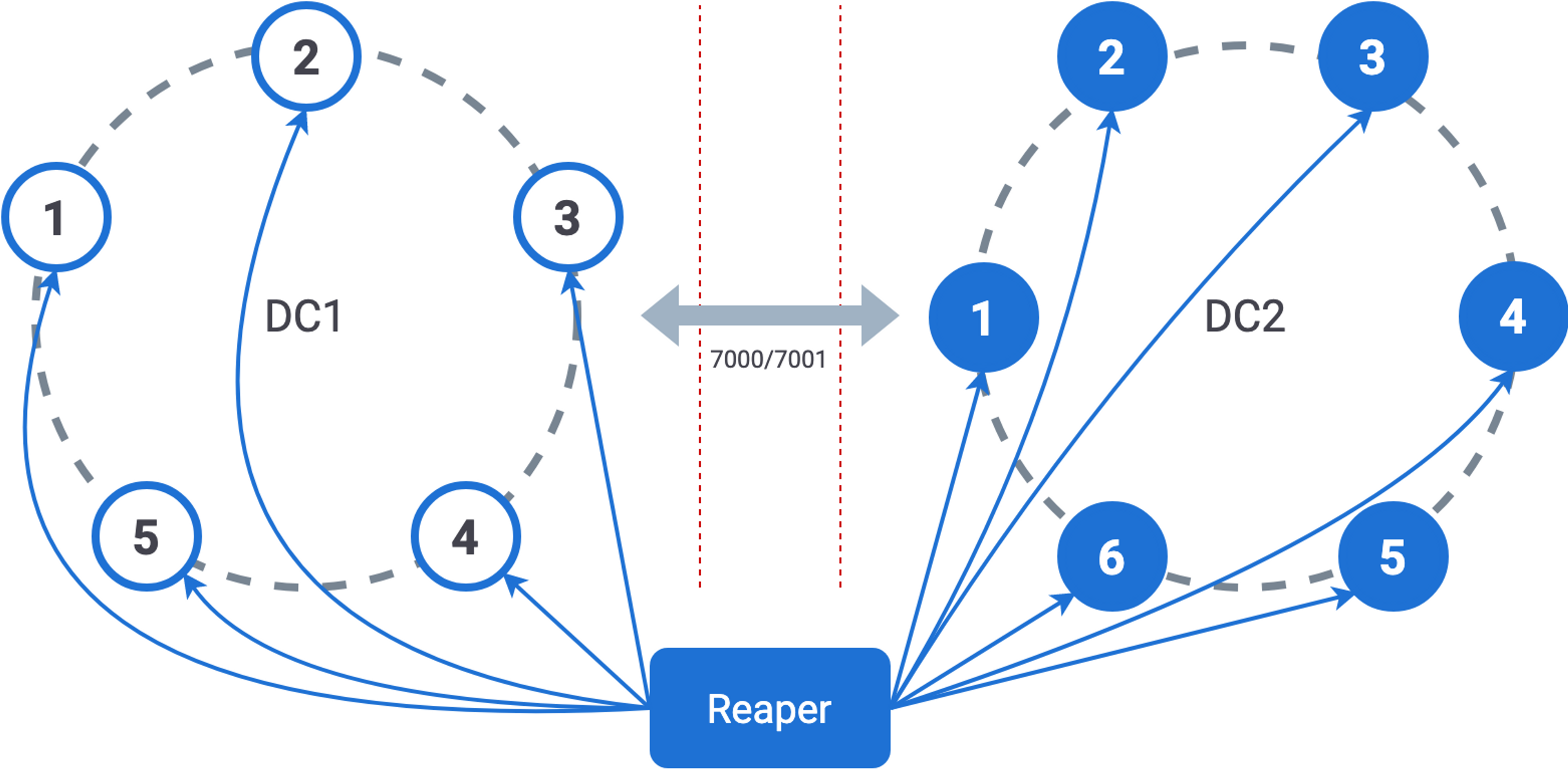
Reaper connects to Cassandra using Java Management Extensions (JMX). Reaper connects to a cluster and can view cluster health and initiate repairs.
Reaper can also schedule repairs in a cluster. A single Reaper instance can handle multiple datacenters. Reaper instances can also be deployed one per cluster.
Sidecar mode deploys a Reaper instance per Cassandra node. Reaper instances running in sidecar mode only require local JMX access from Reaper to Cassandra.

More Resources
Items related to Kubernetes