Async Internode Messaging in Apache Cassandra® 4.0



Internode Communication
One performance enhancement of Apache Cassandra® 4.0 is internode communication optimizations and tuning. These adjustments consist of several changes; some of these changes are just good to know about, but others you can tune with parameters. Many of the internode communication changes are a result of retiring technical debt. We’ll go through each of the changes in this module.
Next: Protocol OptimizationProtocol Optimization
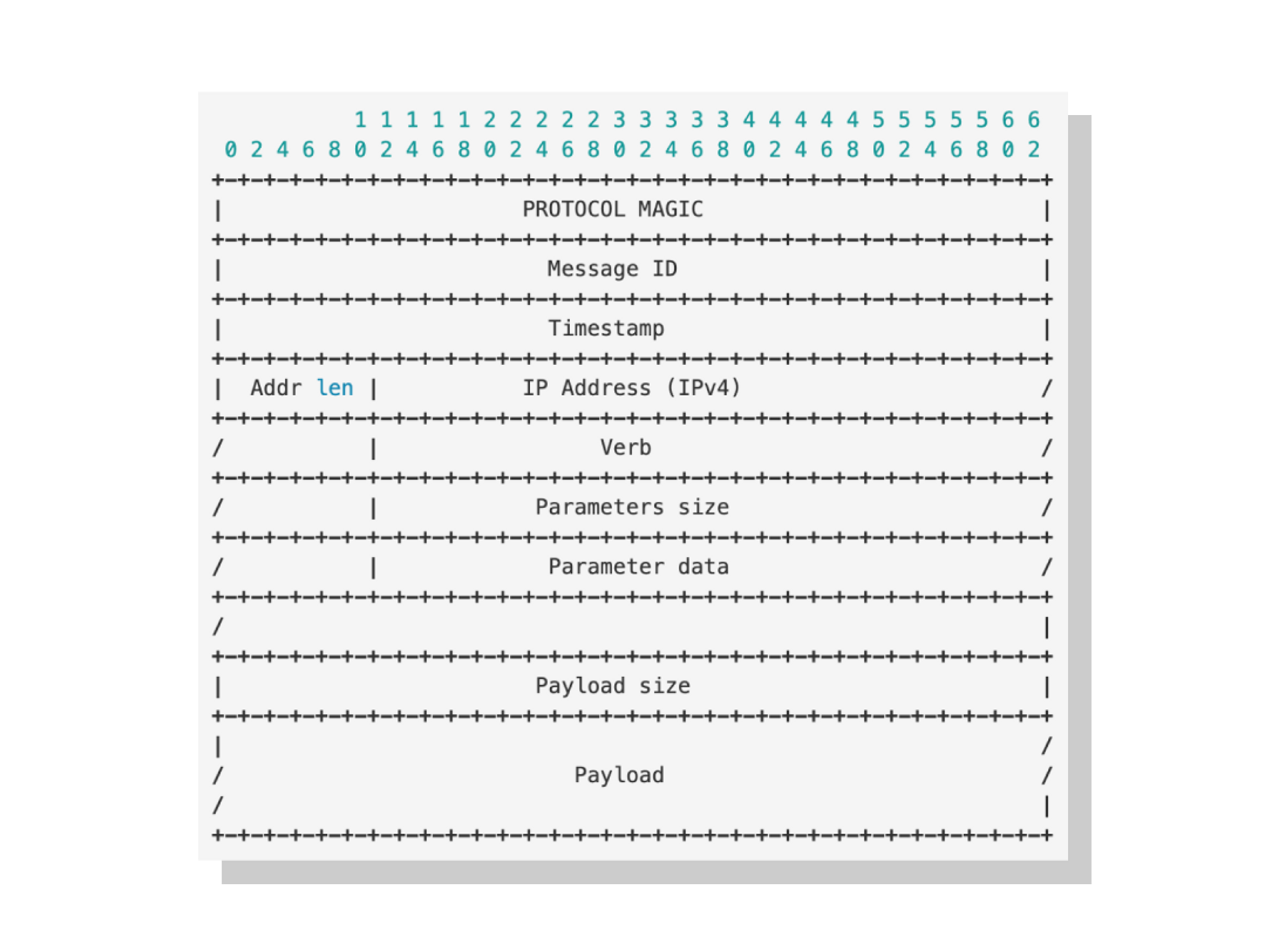
The 4.0 release introduces a couple of protocol optimizations (CASSANDRA-14485). The first removed a bit of redundant information (the IP address and port of the sender, which was included in each message and is now only included once). The second is the use of vint instead of a four-byte int for several values.
Note that Cassandra 4.0 can use these optimizations when communicating between 4.0 nodes, however, 4.0 nodes can also use the old protocol for compatibility with older nodes.
Next: NIO & Netty


NIO & Netty
In Cassandra 4.0, peer-to-peer (internode) messaging has been switched to non-blocking I/O (NIO) via Netty (CASSANDRA-8457). Prior to this change, Cassandra expended a lot of processing to perform context switching. Non-blocking means the CPU can perform useful work which makes the entire node run more smoothly. You don’t need to do anything to take advantage of this improvement, except sit back and listen to your nodes pur.
Next: Resource Limits on Queued MessagesResource Limits On Queued Messages
(CASSANDRA-15066) This feature simply puts bounds on the number of unsent or unprocessed messages that can be in the messaging queues. Without this, a node's memory usage can grow unbounded and run out of memory. In general, the defaults can be used as currently set. Advanced users have the option to tune these settings based on the specific environment.
Next: Virtual Tables for Messaging Metrics

Virtual Tables For Messaging Metrics
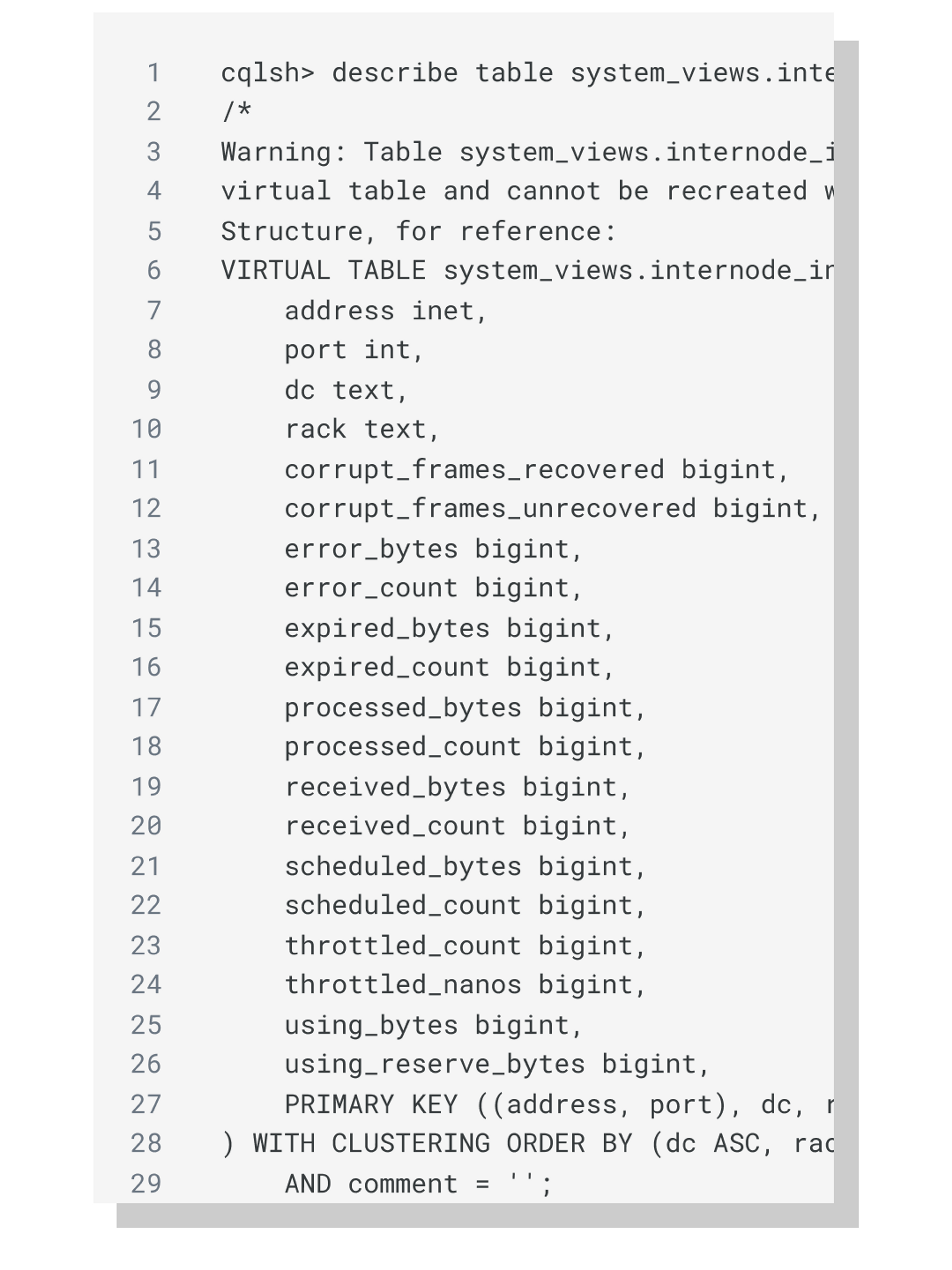
With the introduction of virtual tables in 4.0, it’s easy to get access to messaging metrics. Within the system_views keyspace, there are two new virtual tables named internode_inbound and inernode_outbound. The internode_inbound table contains these metrics:
- Bytes and count of messages that could not be serialized or flushed due to an error
- Bytes and count of messages scheduled
- Bytes and count of messages successfully processed
- Bytes and count of messages successfully received
- Nanoseconds and count of messages throttled
- Bytes and count of messages expired
- Corrupt frames recovered and unrecovered
The inernode_outbound table contains these metrics:
- Bytes and count of messages pending
- Bytes and count of messages sent
- Bytes and count of messages expired
- Bytes and count of messages that could not be sent due to an error
- Bytes and count of messages overloaded
- Active connection count
- Connection attempts
- Successful connection attempts
Hint Messaging
Hint messaging has been improved in Apache Cassandra® 4.0. As background, hints allow Cassandra’s coordinator nodes to save writes in the case where a replica-owning node is temporarily down. When the replica-owning node comes back up, the coordinator can catch the replica-owning node up by sending hints.
In comparison, when nodes running 4.x need to send hints to other 4.x nodes, they can now use an optimized hint-passing message. This message reduces buffer allocations and eliminates some redundancy.
Next: Internode Application Timeout


Internode Application Timeout
There is a new entry in the cassandra.yaml file named internode_application_timeout_in_ms. It controls the amount of time unacknowledged data is allowed on a streaming connection before the node closes the connection. The default value is five minutes.
Next: Paxos OptimizationPaxos Optimization
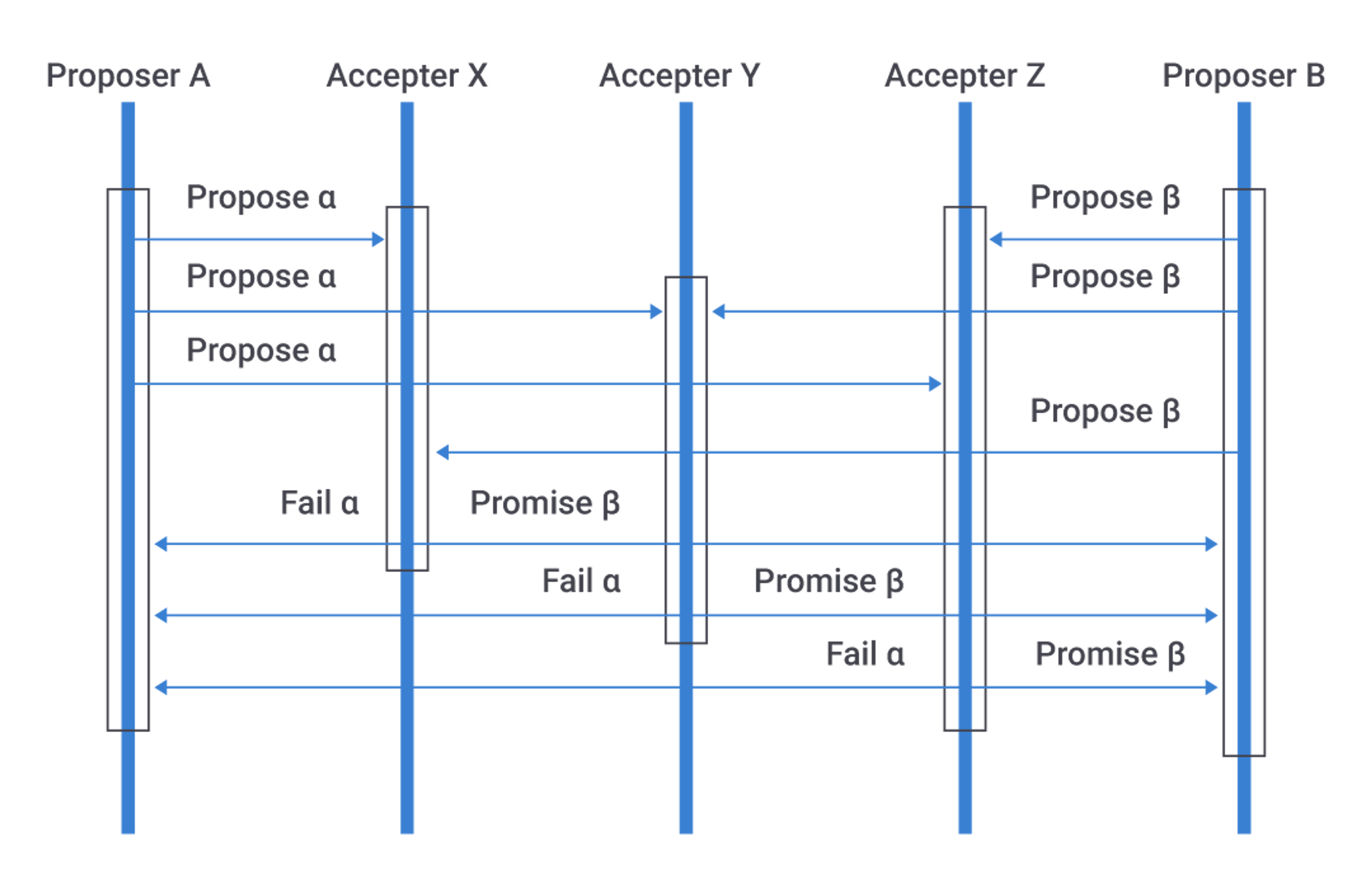
Paxos refers to an algorithm for establishing consensus within a distributed system. The algorithm has two phases. In the first phase, nodes prepare to accept the most recent state. During the second phase, they propose to commit to that state.
Prior to 4.0, the Paxos prepare and propose messages used the MessagingService stack, even if the message was to the local node. This 4.0 optimization bypasses the MessagingService stack for local messages (CASSANDRA-13862). At first blush, this may not seem like a big deal, but at high-transaction rates, this optimization reduces the P99 latency.
Next: Graceful Unknown Table Recovery


Graceful Unknown Table Recovery
Prior to Cassandra 4.0, if a node received a message about an unknown table, the node would close and then re-open the connection. This caused other queries to fail. This change causes the node to ignore the message with the unknown table, but to maintain the connection so no queries fail.
Next: Skill BuildingSkill Building
Want to get some hands-on experience? Give our interactive lab a try! You can do it all from your browser, it only takes a few minutes and you don’t have to install anything.
More Resources
Items related to Virtual Tables


