Repair Improvements in Apache Cassandra® 4.0



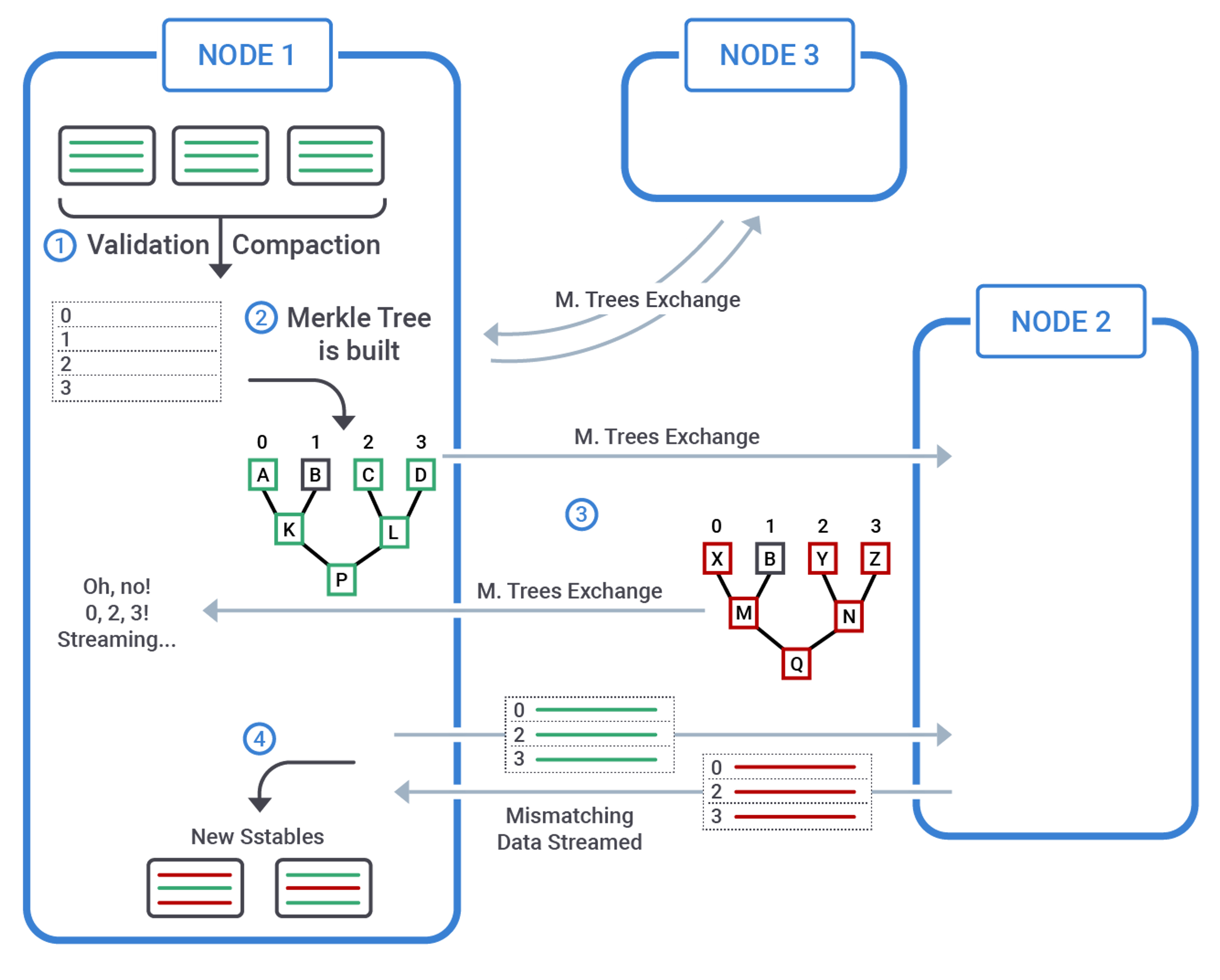
Repair Overview
Let's start by summarizing what happens when an incremental repair is started on a node - which then becomes the coordinator for that repair.
On each of the involved nodes:
- All SSTables are read: this validation compaction does not result in new SSTables and has the sole purpose of …
- … building a Merkle tree, a hierarchical structure (made of hashes of blocks of data) ready for fast, bandwidth-sparing comparison between nodes.
- Merkle trees are exchanged between nodes and discrepancies in data are identified.
- Blocks of data are streamed from node to node and persisted as new SSTables: consistency is now restored.
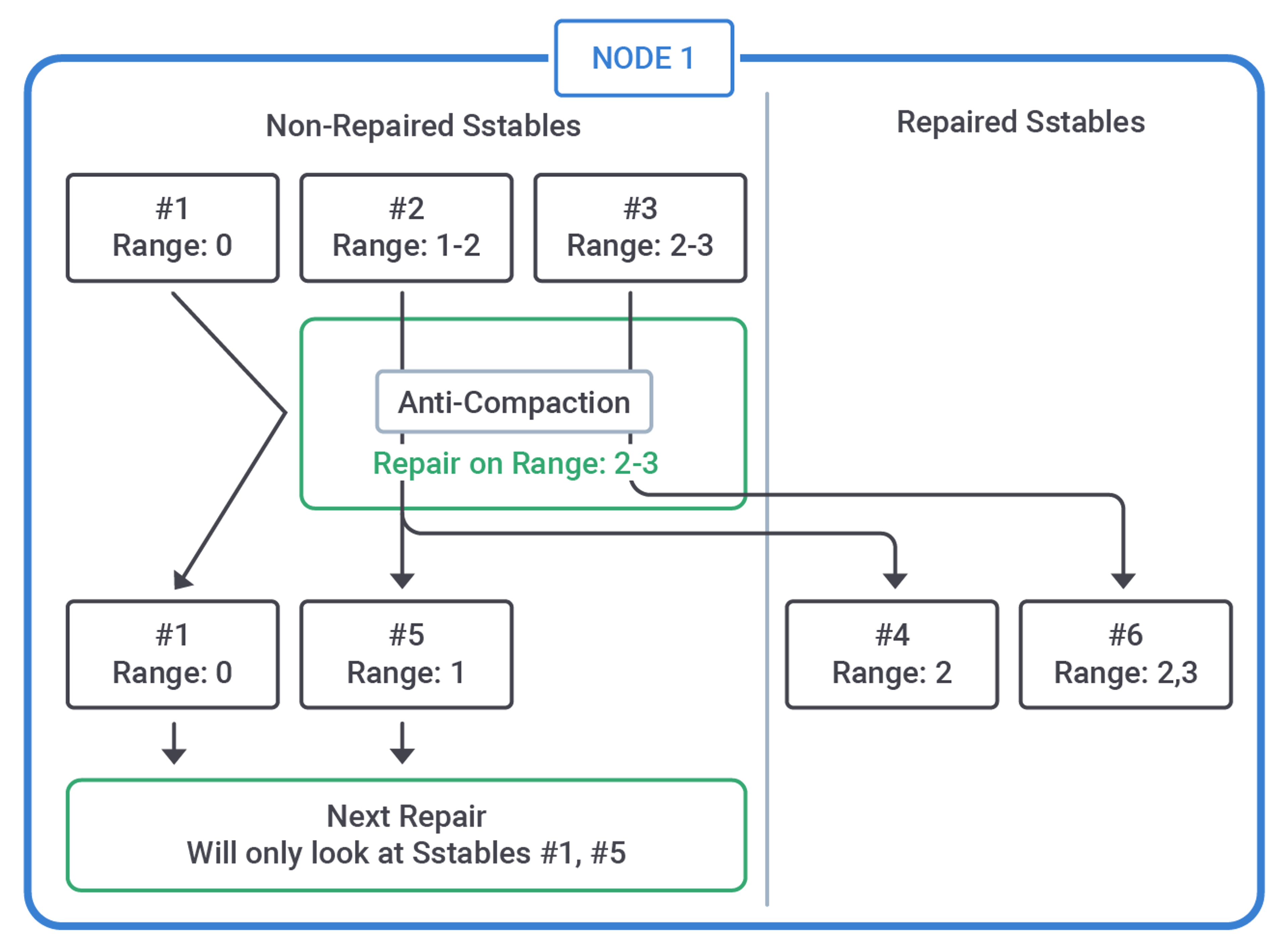
Anti-Compaction
Incremental repair works by grouping SSTables in two pools, repaired and non-repaired (in practice, a timestamp "repairedAt" is attached to SSTables in the first pool).
Thanks to the immutable nature of SSTables, and the prescription to never mix the pools through (ordinary) compaction, each repair can safely take care of just what has not been repaired yet, saving substantial time compared to the previous "full repair".
An important operation called anti-compaction is also involved, whereby an SSTable is split into a repaired and a non-repaired part. That's because in general it may contain a set of tokens wider than the specific token range currently being repaired.
Prior to Cassandra 4.0, anti-compaction was performed right after the data streaming, while finalizing the repair session.
Next: Overstreaming

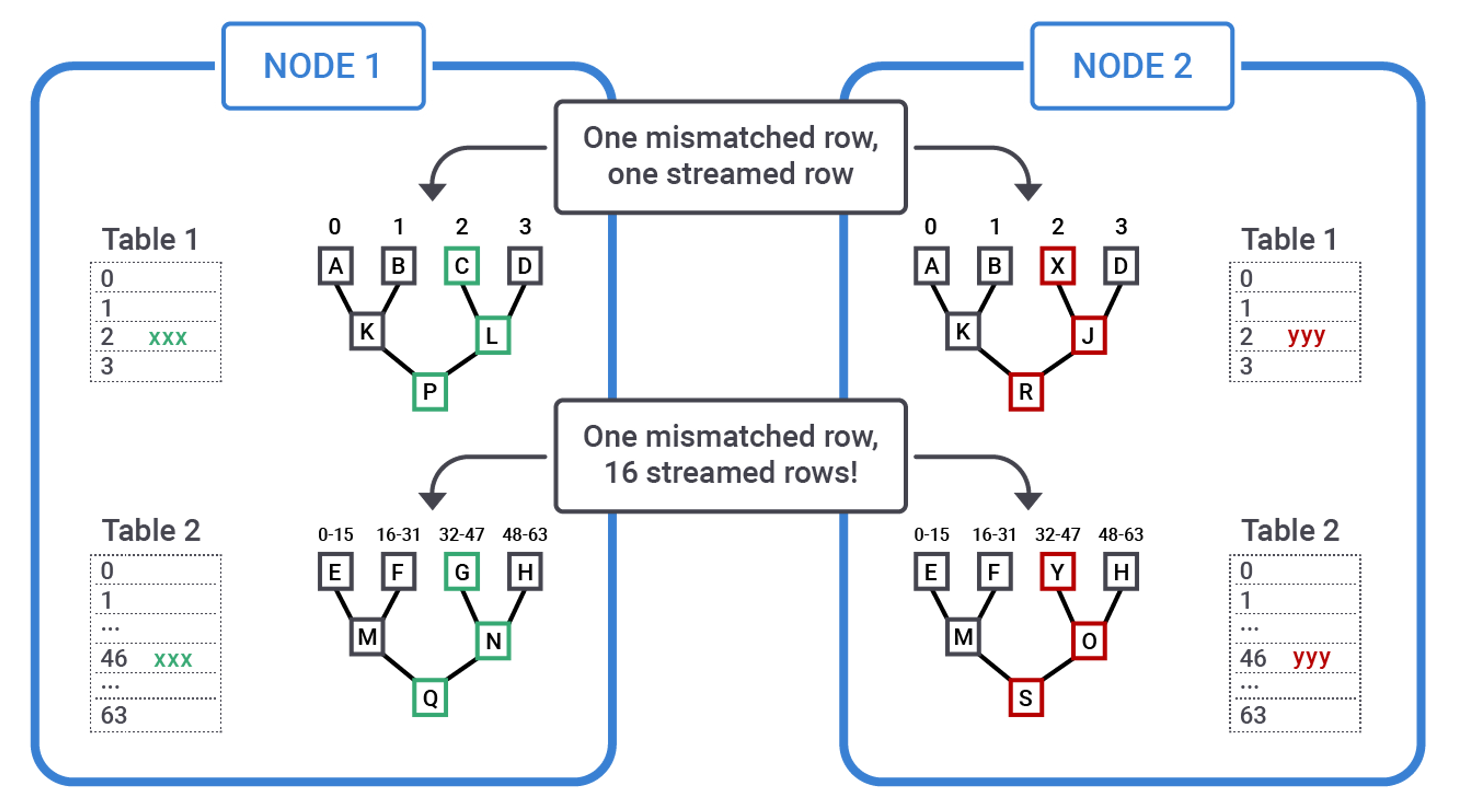
Overstreaming
Nobody likes to waste bandwidth by streaming unnecessary data between nodes. On the other hand, due to memory constraints, a Merkle tree has limited resolution - each of its "leaves" maps to a whole set of tokens.
As a result, for large tables, a tiny discrepancy can potentially command a very large chunk of data transmission.
Prior to Cassandra 4.0, to mitigate this problem, smaller token ranges were repaired at a time - in practice, trading network load for repair duration.
Next: A Serious Case of OverstreamingA Serious Case Of Overstreaming
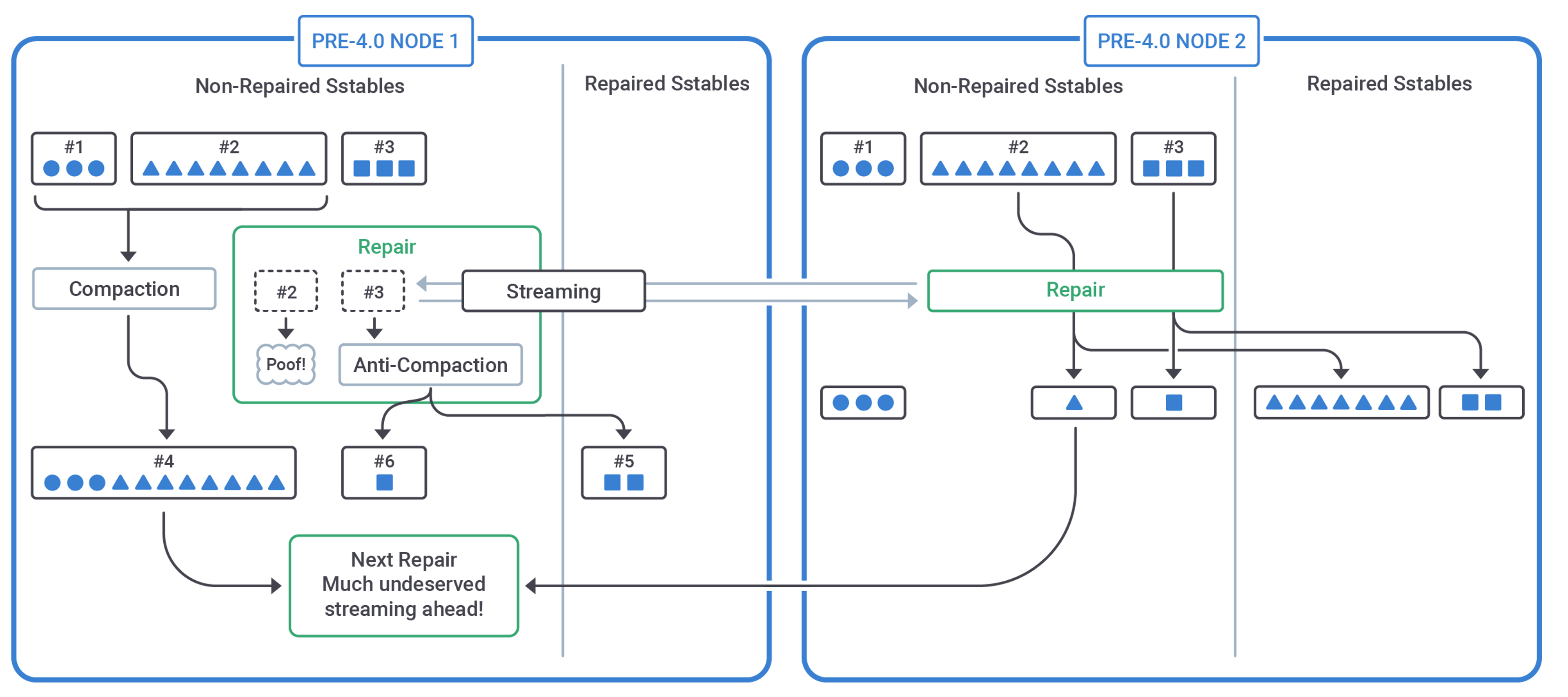
Before version 4, a Cassandra cluster had a chance to experience a condition with the potential to cause massive overstreaming, to the point of crippling the datacenter altogether.
The job of ordinary compaction is to replace a group of SSTables with a new one. If this happens during the streaming phase of a running repair, the new SSTable (marked as "unrepaired"), will not be subject to anti-compaction.
If this happens just on some of the nodes, huge differences will be detected the next time a repair is initiated. An incremental repair looks at and compares the "unrepaired" data only. This could lead to dramatic overstreaming, inflicting an undeserved performance damage to the whole cluster.
In general, severe overstreaming, with nodes disagreeing about repaired/non-repaired status and data otherwise "healthy", could originate in various ways.
Next: Three Pools for Cassandra 4

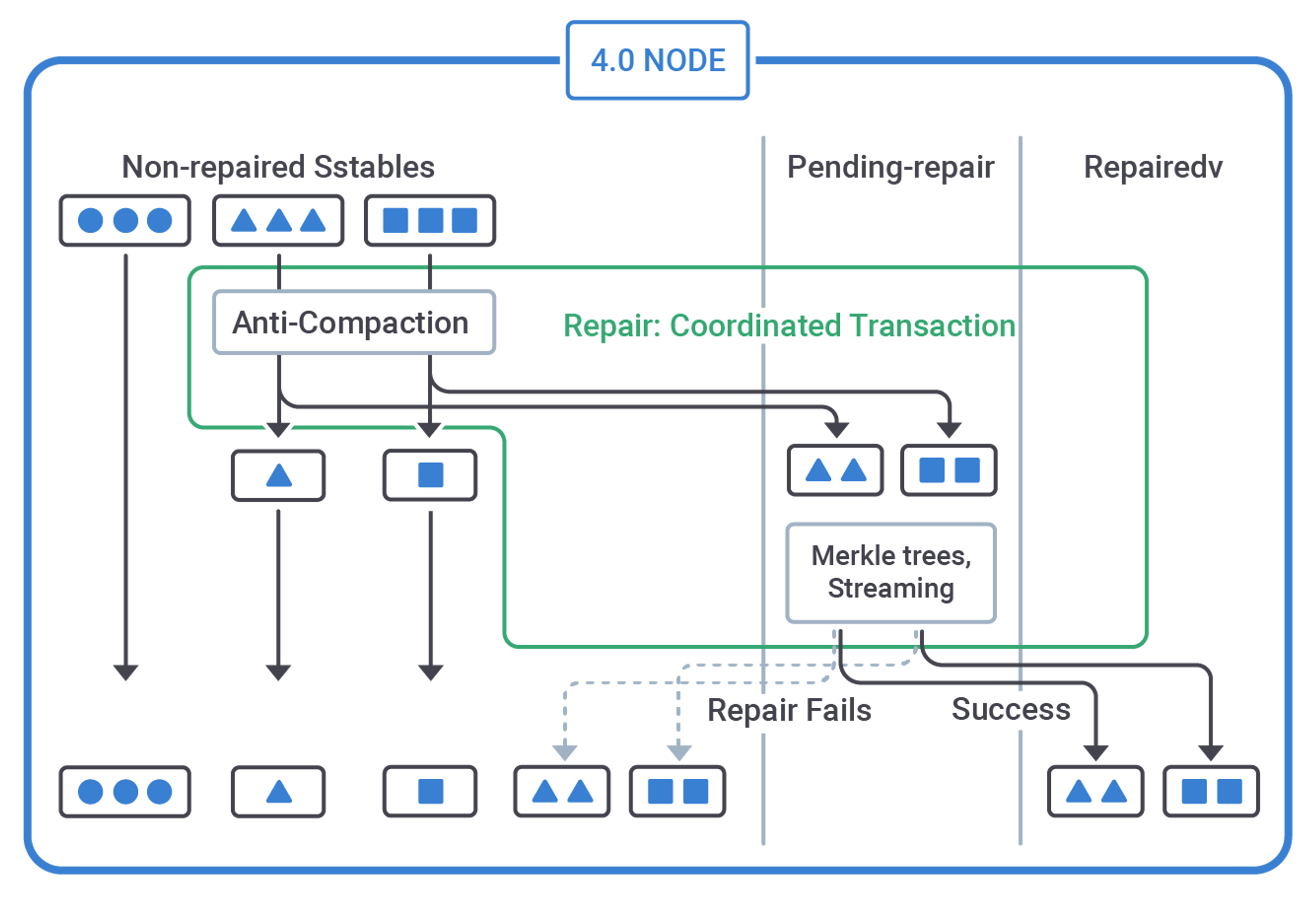
Three Pools For Cassandra 4
With Cassandra 4, the repair process has been improved to keep these potential problems at bay.
First, the whole operation is enclosed in a transaction, negotiated between nodes with a Paxos-type algorithm: in this way, should it ever fail in mid-execution, it is rolled back cleanly and consistently on all involved nodes.
Second, anti-compaction kicks in right at the start of the repair, before any streaming takes place. The resulting SSTables are placed either in the non-repaired pool or in a new pending-repair pool protected from compaction.
Construction of the Merkle tree and the subsequent streaming of mismatching blocks, are limited to the pending-repair pool. Only at the end of the streaming phase are all SSTables moved to the repaired pool, consistently on all nodes.
With this three-pool procedure, enclosed in a transaction, the "apparent misalignment" problems outlined earlier cannot arise. Incremental repair has become a robust distributed mechanism to ensure data consistency, and is ready to supersede legacy, token-range-based repair solutions.
Next: Friendlier Support for RepairFriendlier Support For Repair
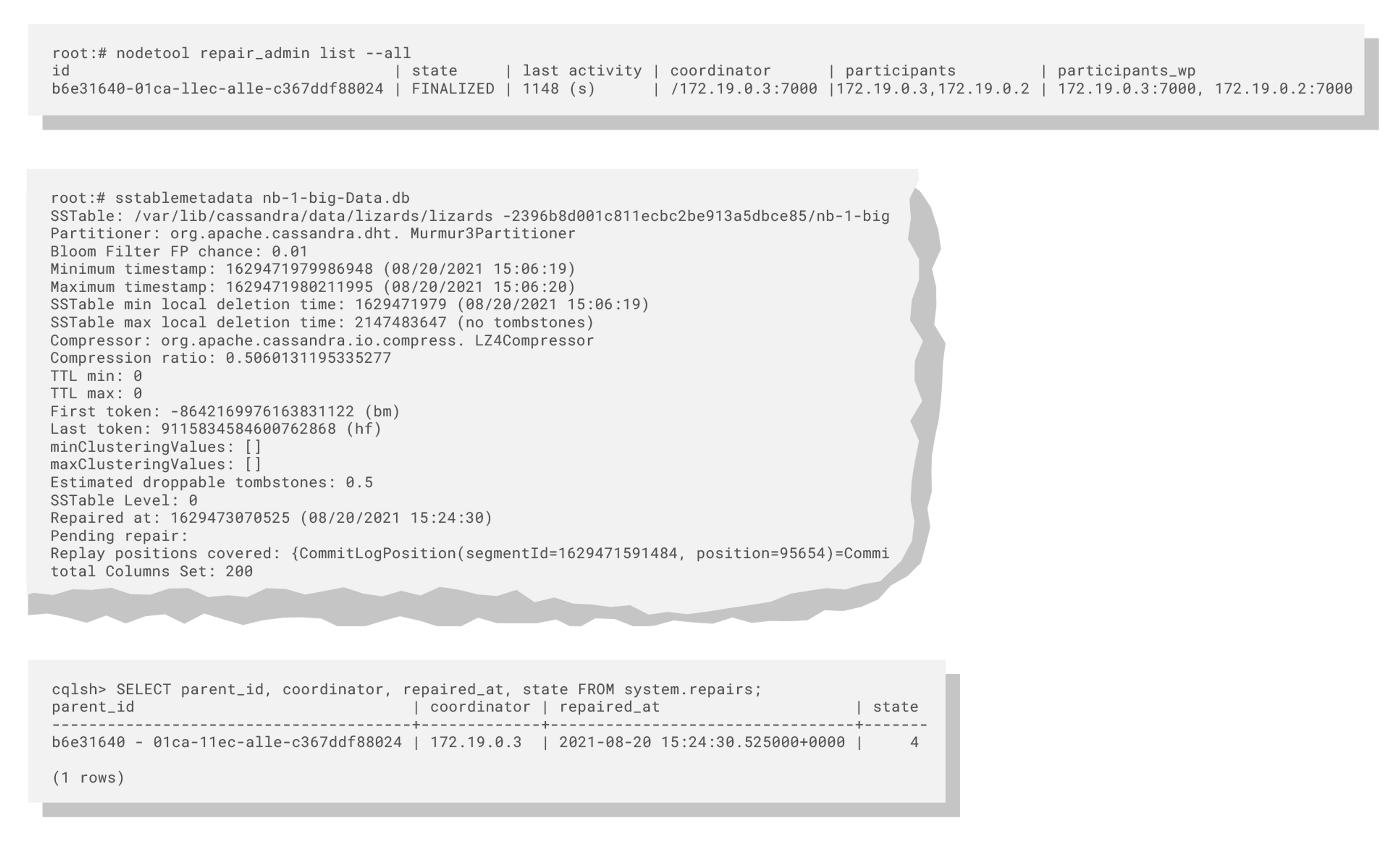
Along with the substantial reformulation of the repair process itself, Cassandra 4 ships with the new nodetool repair_admin command for better control over incremental repairs: it is now possible to track repair operations, and stop specific currently-running ones (even from a node other than the coordinator).
In addition, the output of sstablemetadata includes the unrepaired/repaired/pending status of an SSTable and gives date and time alongside the "repairedAt" timestamp for an easier reading.
Moreover, the new system table system.repairs has been introduced that holds the history and details of all repair operations performed on a cluster.
Next: Summary

Summary
Among the improvements introduced in Cassandra 4.0, incremental repair is a central feature in these improvements. Thanks to the introduction of a transaction around repairs, and a three-pool way of handling the status of individual SSTables - maintaining long-term consistency of the cluster has never been easier.
Repairs cannot be run simultaneously on several nodes for the same token ranges; they must take place on one node after another.
It is a good practice to automate scheduling and sequential execution of repairs; this can be done in a robust way using the open-source tool cassandra-reaper.
It must be noted, however, that incremental repair does not work for materialized views or CDC (change data capture) as these involve data transitioning back to the memtable (where rows from separate pools are mixed). In that case, one should stick to traditional full repair and devise an adequate token-range policy.
Next: Skill BuildingSkill Building
Want to get some hands-on experience? Give our interactive lab a try! You can do it all from your browser, it only takes a few minutes and you don’t have to install anything.
More Resources
Items related to Repair Improvements


