Virtual Tables in Apache Cassandra® 4.0



Virtual Tables
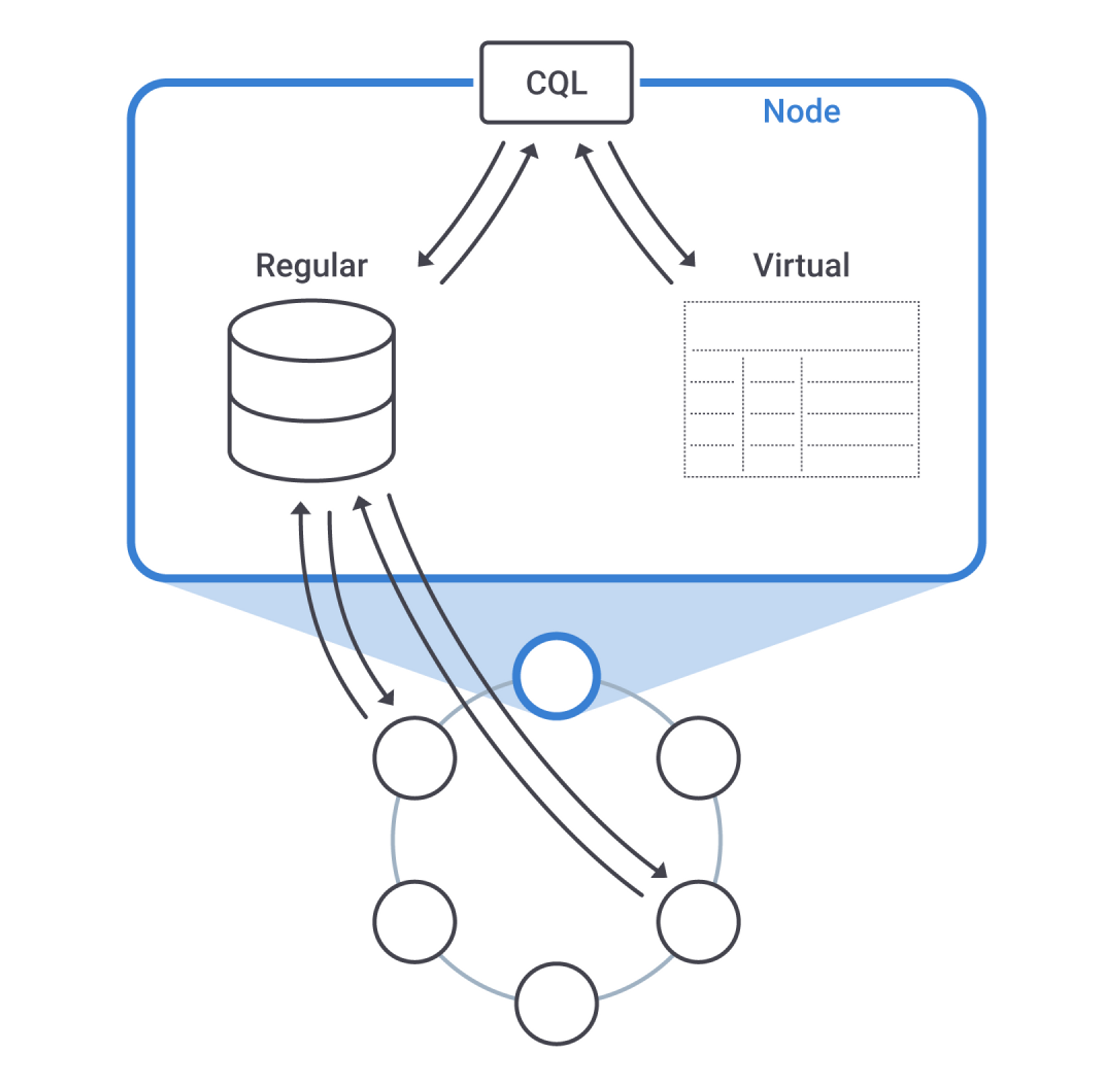
At first glance, virtual tables look like all other tables: CQL lets you read them with ordinary SELECT statements. But the results don't come from SSTables and are not distributed: indeed they may not even be written on disk at all, originating instead from live calculations.
Next: QueryingQuerying
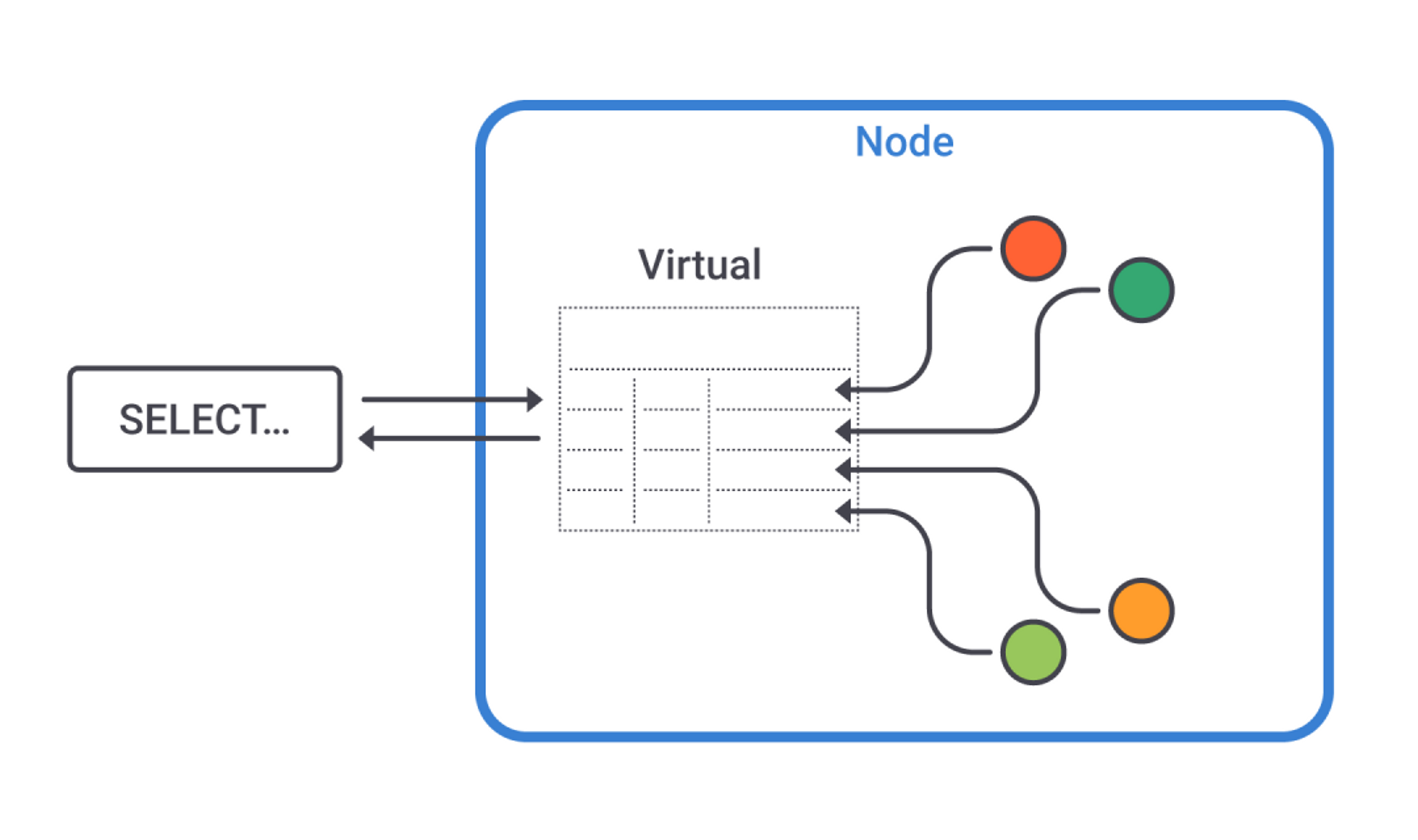
When you query a virtual table, you do so on a specific node and it is that node that answers. Concepts such as replication, distribution, consistency level do not apply (the latter is simply ignored in queries). If you read the same table on another node, you may well obtain different results—hardly surprising, given that virtual tables are conceived for node-specific information.
In version 4.0, virtual tables are read-only. Write operations, as well as DDL statements, are not permitted. In future versions, row updates may be allowed, which will come handy for changing node settings on the fly or triggering certain actions, something still requiring nodetool/JMX at the moment.
Next: system_virtual_schema keyspace


System_virtual_schema Keyspace
Virtual tables are confined to dedicated system keyspaces. One such keyspace, system_virtual_schema, contains tables encoding the schema information for all virtual tables—just what you would get with a DESCRIBE TABLE statement on a virtual table, but in machine-readable form.
Next: system_views keyspaceSystem_views Keyspace
The interesting data is in keyspace system_views. DESCRIBE TABLES shows that it contains about twenty tables, each exposing a specific type of information. Some are:
- clients: currently active connections, their driver version, ports used and so on;
- sstable_tasks: status and progress of currently-running operations such as compactions;
- system_properties: OS and JVM versions, Cassandra path definitions and other settings;
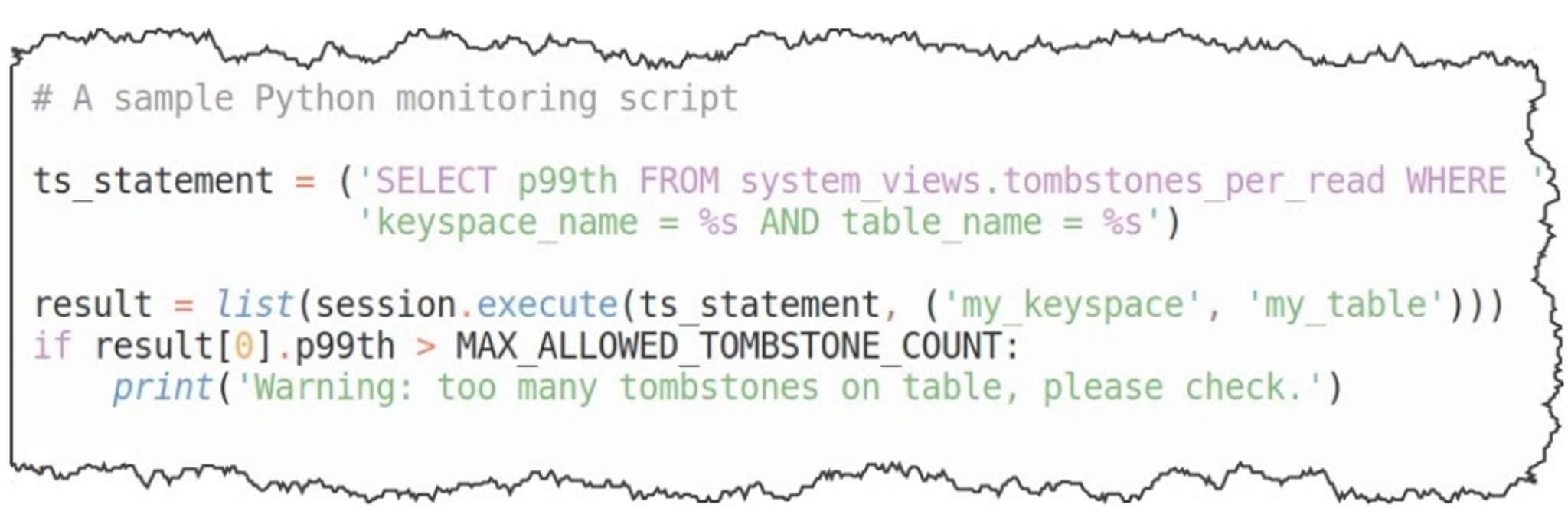
- tombstones_per_read: statistics on the efficiency of read operations;
- disk_usage: how much space each table occupies on the hard drive;
- settings: the many, many settings one would find in cassandra.yaml.

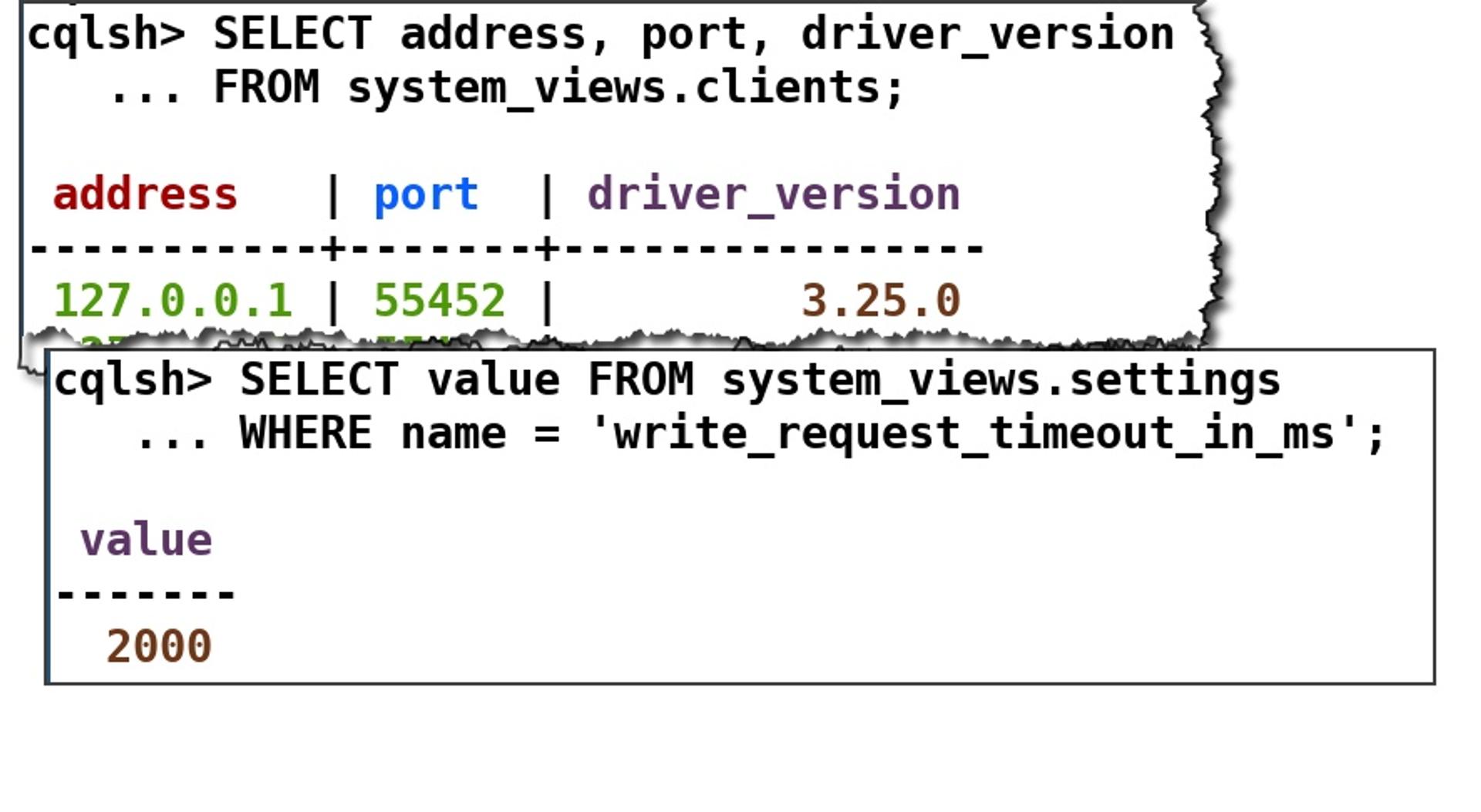


Table Structure
You can run a DESCRIBE KEYSPACE or DESCRIBE TABLE statement on a virtual table: however, CQL duly informs you that the results are for your convenience only, and that the corresponding CREATE commands would not work - indeed, the entire output of the DESCRIBE statements is given as a CQL comment!
Next: SummarySummary
Virtual tables help make a node observable from within CQL. This opens the way for new, more integrated tools and automation, especially related to performance monitoring. More metrics and internal information will be added in future releases, together with the ability to change some settings by writing directly to the tables: feature equivalence with the JMX approach is indeed on the roadmap.
Next: Skill Building
Skill Building
Want to get some hands-on experience? Give our interactive lab a try! You can do it all from your browser, it only takes a few minutes and you don’t have to install anything.
More Resources
Items related to Virtual Tables



