Zero Copy Streaming in Apache Cassandra® 4.0



The Purpose Of Zero Copy Streaming
One of the very important qualities of a distributed database is the ability to quickly transfer data from one node to another. There are many scenarios in which this becomes pivotal:
- Bootstrapping a new server to scale out the cluster and handle the increased workload
- Repairing a cross-node inconsistency
- Decommissioning a redundant server to reduce infrastructure costs
- Quickly rebuilding or replacing a failed machine to decrease Mean Time To Recover
The last case may need an additional explanation. While Cassandra’s replication feature allows losing one of the nodes, a single failed server creates a potentially dangerous situation; where the next failed server will lead to data unavailability on the higher consistency levels. The longer this issue stays unresolved, the higher the chance of potential downtime!
To help build a dynamic infrastructure and decrease a potentially dangerous time span, Dinesh Joshi, Senior Engineering Manager at Apple, reworked the streaming mechanism of Apache Cassandra resulting in a whole new level of performance.
Next: How Streaming Worked BeforeHow Streaming Worked Before
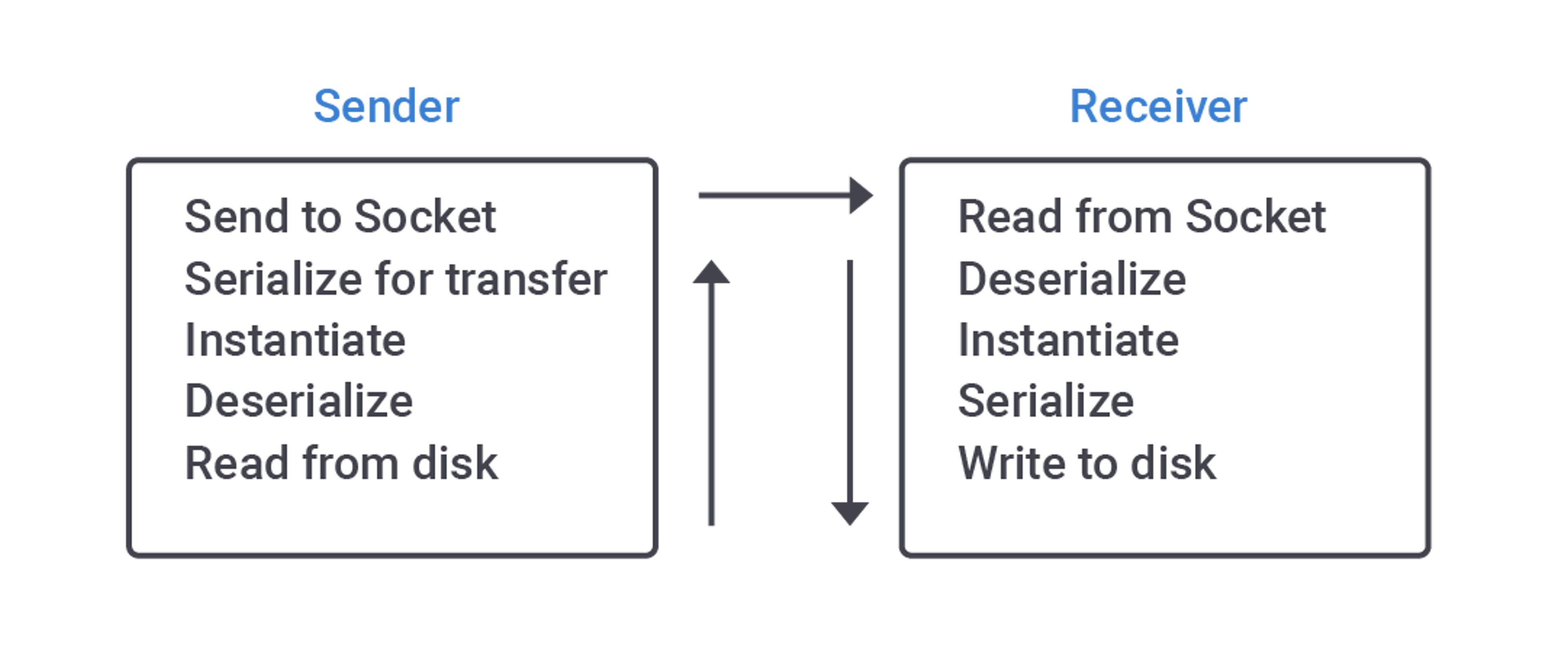
To understand the new implementation of streaming, we need to understand how it was performing in prior versions. In short, the process wasn’t simple. In order to send partitions to the proper node, the data had to be loaded in memory, instantiated to objects, serialized for network transfer, and then, finally, sent to the receiving node. The receiving node follows the same pattern in the opposite direction. It will deserialize data, load the data into objects, and then store it on disk. This process was quite a heavy workload for both source and destination, requiring many operations consuming RAM memory and CPU cycles.
Next: How Zero Copy Streaming Works Now

How Zero Copy Streaming Works Now
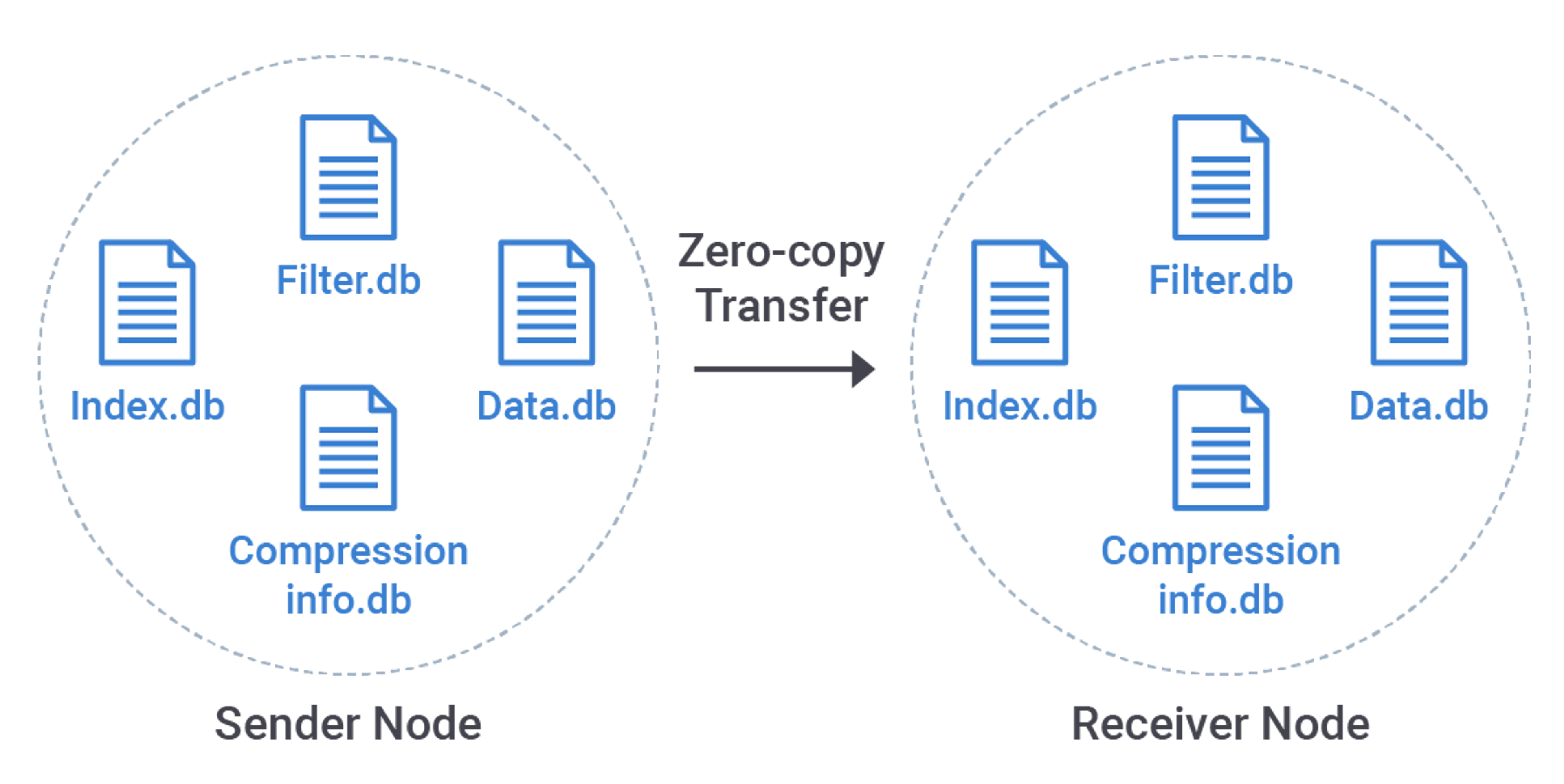
The intention of the new approach is very simple: why should we do all these steps if the result will be the same: partitions in the form of an SSTable file on a disk? Wouldn’t it be easier to simply transfer the whole file via the network? Every SSTable file contains one or more partitions. When all of these partitions must be transferred to the target node, this file is considered eligible for Zero Copy Streaming and moved as it is, with no extra steps!
Next: The OutcomeThe Outcome
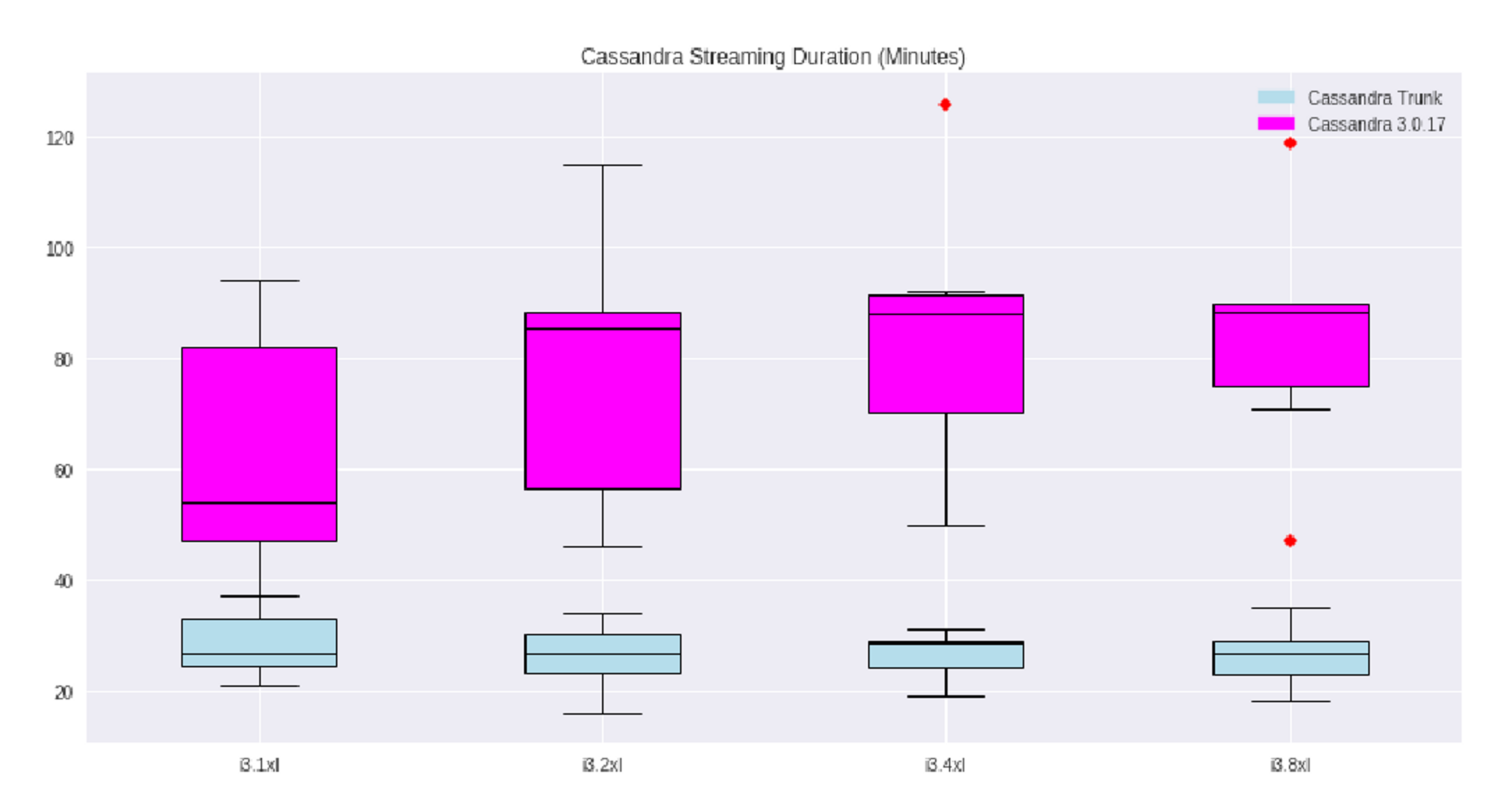
While it sounds simple, did it make any significant change? Yes, definitely! The Netflix team did extensive research, investigating different scenarios and hardware setups, and discovered an incredible time boost, such as streaming time being reduced from 70-90 minutes to approximately 25 minutes (scenario: failed node replacement, 500 GB per node, 6-node cluster of i3.4xl AWS instances).
The conclusions of their research were:
- In version 3.0, streaming times are inconsistent (high variability) and highly affected by the instance type (more powerful servers perform better)
- With Cassandra 4.0, streaming is approximately 5x faster and shows little variability in its performance
- Cassandra 4.0 streaming performance is not CPU-bound and remains consistent across different instance types (so even cheaper servers perform better)


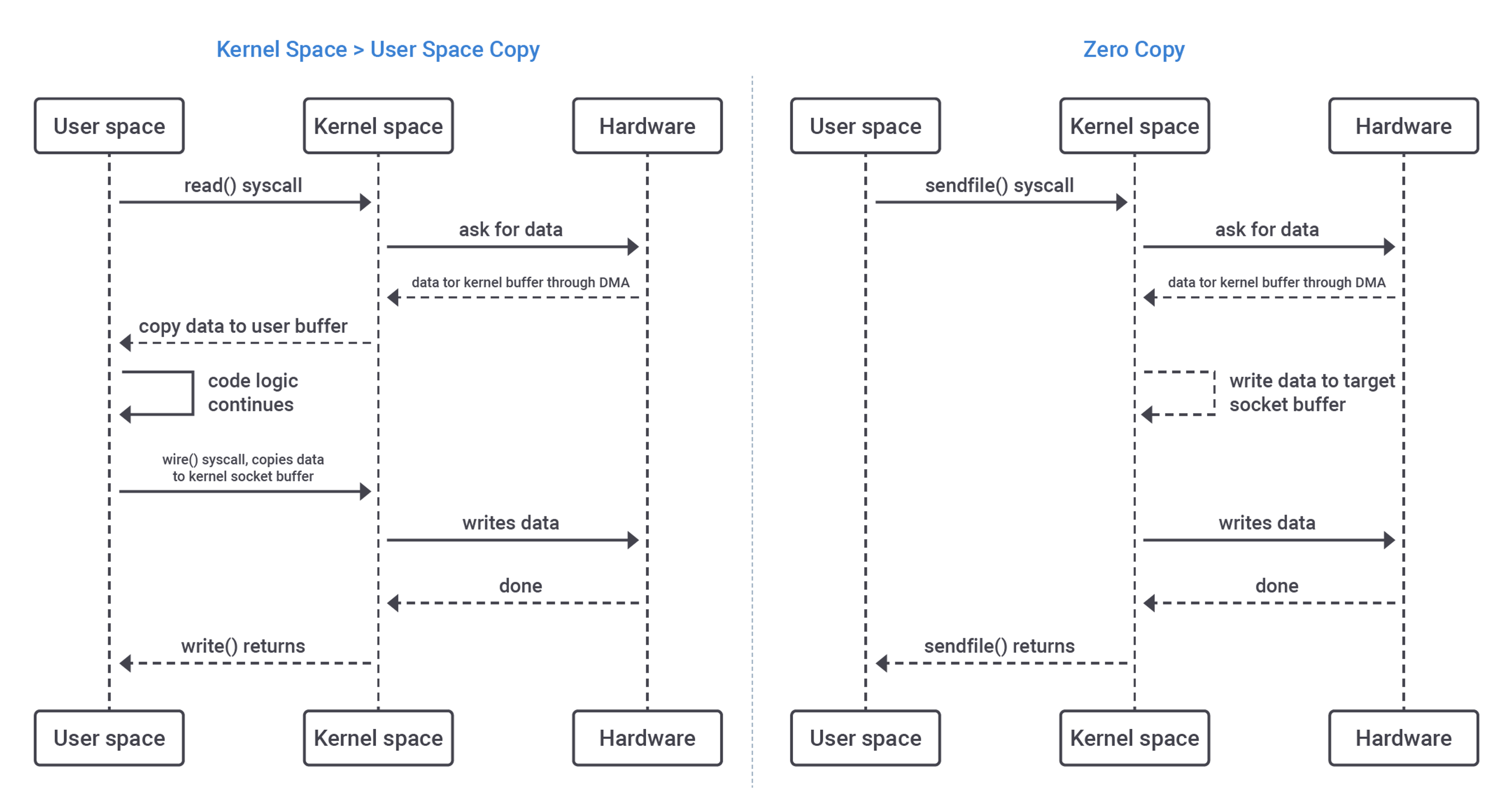
Why Zero Copy?
We talk a lot about zero-copy streaming, but what does it actually mean? What exactly do we copy and why is it somehow zero? The answer requires some understanding of how memory works in modern computers. For security reasons, there are two different regions known as Kernel Space and User Space. When you retrieve data from a device or a disk, you first pass it to the Kernel Space and then it has to be copied to the User Space where it can be accessed by an application. The previous approach to streaming partitions followed this same path in order to serialize data and prepare it for transfer. This led to unnecessary operations and overhead costs, drastically raising memory usage and keeping the Garbage Collector busy as the object in memory wasn’t reused after the transmission. In version 4.0, the data is streamed directly from the Kernel Space without copying it to the User Space, which greatly decreases workloads on both writer and reader.
Next: Throttling!Throttling!
This improvement was so efficient that it led to an unforeseen consequence. Previously, streaming was limited by CPU and RAM performance, causing a bottleneck. Since the disks normally used with Cassandra are lightning-fast, simultaneous Zero Copy Streaming of multiple nodes could have saturated the entire network throughput. This would interfere with the normal data queries; in other words, the new streaming feature is too good! To address this issue, throttling was introduced and it is enabled by default limiting outbound streams to 200 Mbps or 25 MB/s.
Note: Throttling should be adjusted carefully as it may be potentially harmful if disabled.
Next: Configuration Considerations


Configuration Considerations
Zero copy streaming is enabled by default but can be disabled in cassandra.yaml using the stream_entire_sstables configuration option.
Other important options are:
- stream_throughput_outbound_megabits_per_sec used to throttle the overall outbound streaming; the default value is 200 Mbps
- inter_dc_stream_throughput_outbound_megabits_per_sec used to throttle the outbound streaming traffic to non-local datacenters; the default value is 200 Mbps
It is also important to note that internode encryption, which may prevent Zero Copy Streaming from working, is configured via the server_encryption_options option.
Next: ZstdZstd
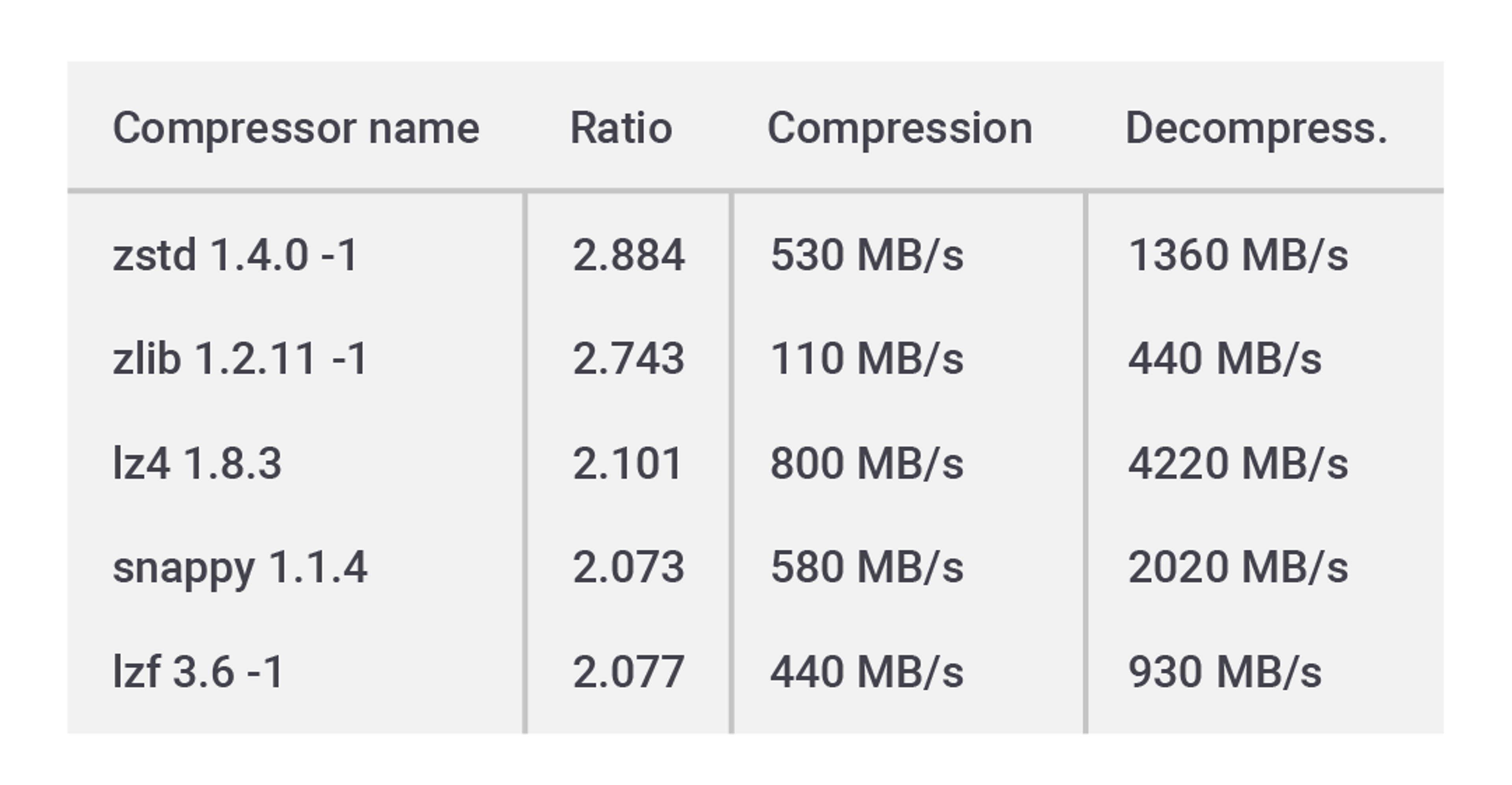
One of the very important components of this improvement was a transition from a traditional Deflate compression algorithm to the new Zstd. Zstd (pronounced as Zet-standard) and was developed by Yann Collet at Facebook in 2015. The algorithm features an improved compression rate while working significantly faster, motivating the community to pull it into the streaming mechanism. Because of the 4.0 feature-freeze announced earlier, one of the Zstd features wasn’t implemented: the so-called Dictionaries (planned for future releases). When this feature is implemented we expect to see even better compression performance!
More Resources
Learn more about Zero Copy Streaming

