Find Exactly What You're Looking For
Built for distributed, real-time applications that need to easily search data quickly and easily at cloud scale.


Integrated Graph And Analytics
DSE Search integrated with graph and real-time analytics allows you to explore relationships between records, write targeted queries, and reduce query response time to gain valuable insights about your users and applications within seconds instead of hours.

Automatic Query Routing
DSE Search automatically routes requests to the best-performing and most capable nodes, ensuring lightning-fast search response times and super-efficient search.

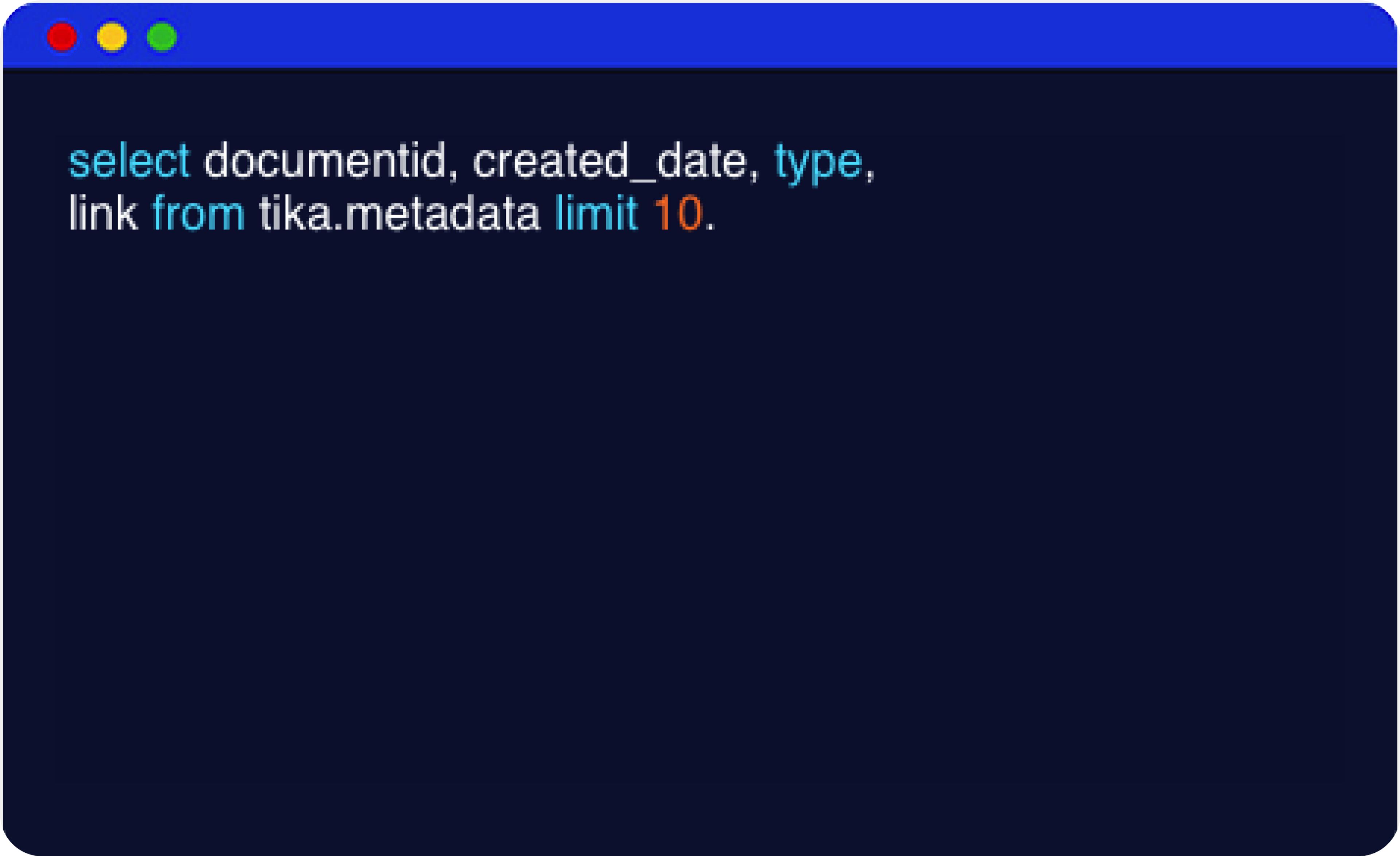
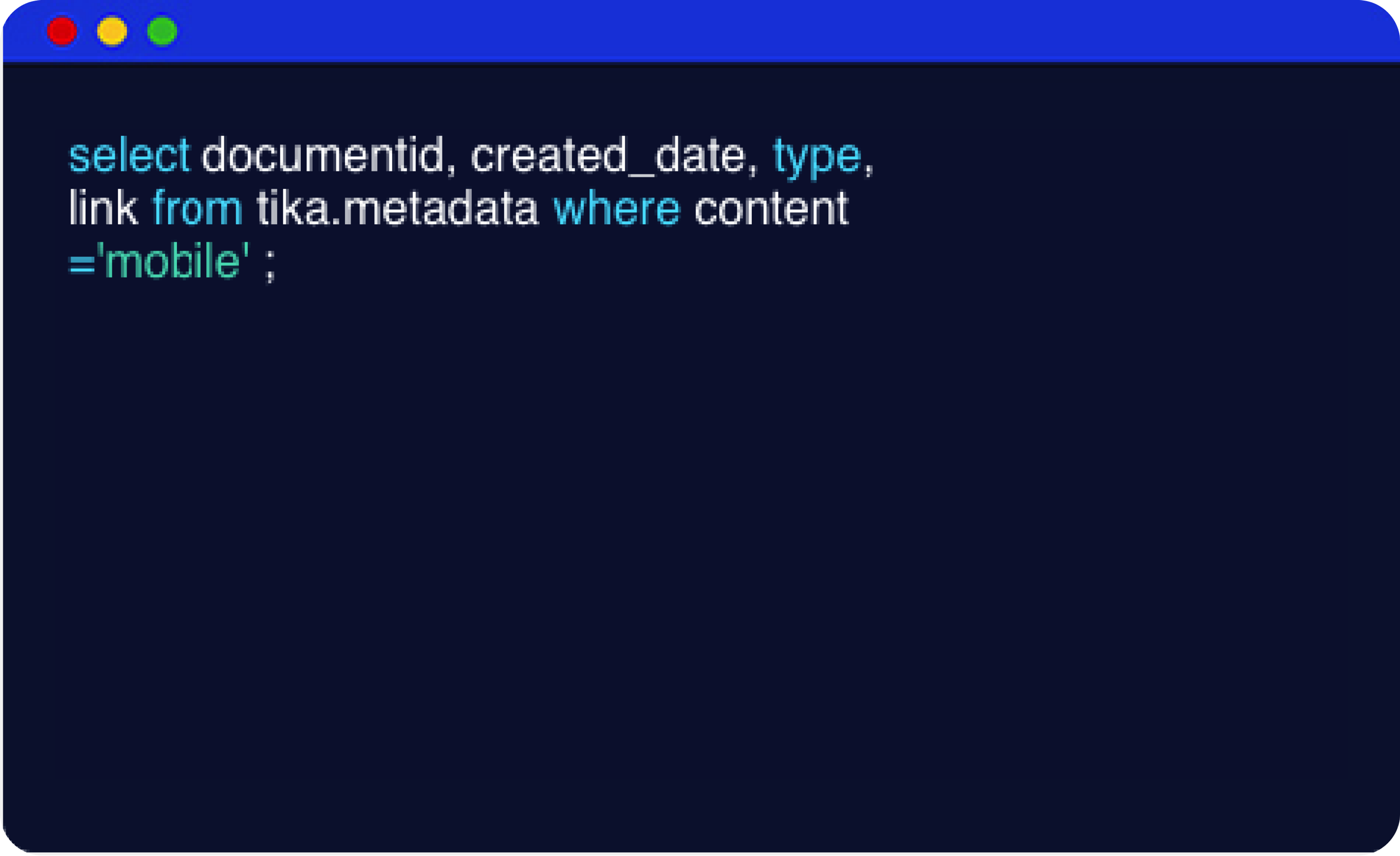
CQL-Based Search
The easy-to-use Cassandra Query Language (CQL) allows users to easily modify their index configuration and schema and utilize a single mechanism (CQL and DataStax Drivers) to interact with DSE Search, which reduces the application development time and accelerates time-to-market and data queries.