Top 10 Things Apache Cassandra Users Need to Know About DataStax Enterprise (Part 2)

Jeffrey CarpenterSoftware Engineer - Stargate

Jeff Carpenter finishes his top ten list with five things you should know if you’re an Apache Cassandra user just starting out with DataStax Enterprise.
In the previous blog post, I began to share my "Letterman" style Top 10 list of things that you should know about DataStax Enterprise if you are familiar Apache Cassandra but are just getting started with DSE. Items 10-6 included things like certified releases, performance enhancements, flexible deployment options, enterprise-grade security, and operational simplicity. Without any further ado, its time to proceed to the final five!

#5 Get fast, complex searches with DSE Search
If you’ve built a production application using Apache Cassandra, you’re familiar with the importance of having a good data model. The best practice of designing tables that support your desired access patterns is something you’ve probably heard frequently if you’ve been around the Cassandra community and used resources like our free data modeling course DS220, available here at DataStax Academy.
However, even if you do follow best practices, there are some queries that Cassandra is just not built to handle. One challenge that I encountered was doing geospatial queries to find business locations close to a point of interest. Even if you include columns for latitude and longitude in your partition key, Cassandra doesn’t support range queries on multiple columns, which is what you would need for a simple bounding box search.
Another challenge arises when you identify additional attributes on which you want to search after your original design is in production. Continuing to add additional denormalized copies of data to support new searches isn’t practical. Users familiar with relational databases will suggest say “just add a secondary index”. You can try to use secondary indexes, but the default implementation is known to scale poorly. The SSTable Attached Index (SASI) implementation is better and provides some text search options.
However, I’ve found DSE Search to be the most full featured search capability on top of Cassandra. Because it indexes data on each node as it is inserted, no separate search cluster or synchronization is required. DSE Search supports text search including substring and fuzzy searches, aggregation, faceting, and filtering.
#4 Get Real-time and operational insight with DSE Analytics
Oftentimes when we’re building a new system, we’re not thinking very much about downstream analysis of the business data our systems or storing, or operational data such as logs and metrics. Or perhaps we’re conscious of the downstream consumers, but don’t know the specific data attributes and reports that will be required. If we’re planning ahead, we may design mechanisms into our systems that allow the easy extraction of data for analytic purposes, such as using messaging or streaming technologies to capture a record of data changes. If we haven’t planned ahead, we may need to rely on ETL tools and processes that run at off-peak hours to minimize impact to operational systems.
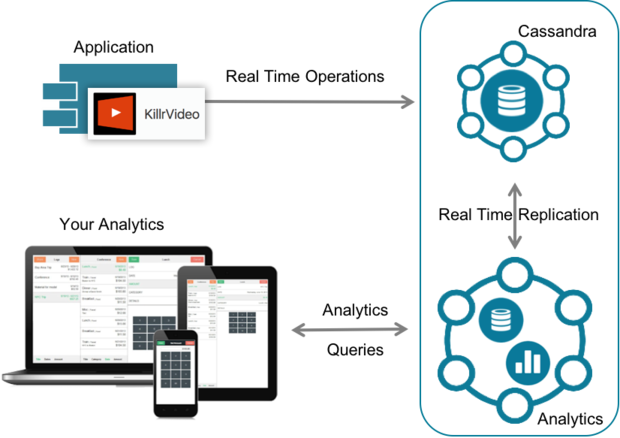
Using DSE Analytics powered by Apache Spark™, you can support a variety of analytics use cases including near-real time and offline processing. A common configuration is shown below, in which a separate analytics data center runs with Spark workers co-located on each Cassandra node to optimize processing. This allows the analytic workloads to be separated from your primary application workload, relying on Cassandra’s cross-DC replication instead of ETL.
#3 Explore new horizons with DSE Graph
If you follow data technology, you’ve been hearing a lot of noise lately about graph databases, and with good reason. One of the key indicators that you might benefit from a graph database is if your data consists of many-to-many relationships, whether it be social networks reflecting relationships between people, or a map or network of roads, rail lines, or other routes. While these relationships can be straightforward to model in relational stores, as the scale of your data grows, the work required to navigate multiple hops through these networks via joins or search indexes becomes a huge drag on performance.
DSE Graph is a scalable, distributed graph capability that is optimized for storing, traversing and querying complex graph data in real time. DSE Graph is built on top of the DataStax Enterprise distribution of Apache Cassandra and takes advantage of the capabilities of DataStax Enterprise Search and DataStax Enterprise Analytics to provide an integrated, multi-model and mixed workload solution.
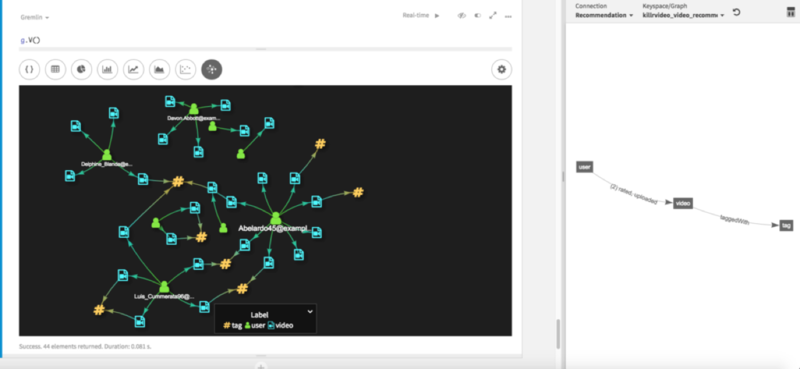
You access and manipulate data in DSE Graph via the popular Gremlin traversal language, as defined by the Apache Tinkerpop project. Gremlin traversals can select elements (vertices or edges) from the graph, navigate to related elements, calculate or project values which are then aggregated (or reduced) and produce results. There many use cases for which DSE Graph is a great fit; I’ll highlight a few:
- Recommendation engines - Graphs simplify building several different types of recommendation engines, which can product recommendations to customers based on their own behavior and some assessment of their similarity to other users, the relationships between products, and so on. My colleague David Gilardi has recently extended our KillrVideo reference application to include a graph-based recommendation engine, so stay tuned for more updates.
-
Social Network Analysis - for example, a shortest path traversal of your social network could help discovering which of your work colleagues could introduce you to a specific contact.
-
Fraud Detection - graphs can be especially useful in identifying patterns of abnormal or suspicious behavior based on relationships we might not normally examine in our data.
#2 Let your data tell its own story with DataStax Studio
Many Cassandra developers will be familiar with DataStax DevCenter, a development tool based on the Eclipse IDE that works with DSE and Apache Cassandra. DevCenter allowed users to create and visualize schema, run queries, and analyze the performance characteristics of those queries. In environments where I have worked, DevCenter was the “go to” tool that I saw on everyone’s desktop, from developers to testers. After a while I stopped being surprised at how many people I saw running DevCenter.
DataStax Studio is the next generation developer tool for DSE. It supports those same capabilities that developers loved from DevCenter, but takes things to a whole new level with its integration of DSE Graph and the visualizations it provides for both Cassandra (CQL) and graph data. Studio uses the notebook style format that has become so popular in the data science world with tools like Jupyter and Zeppelin.

The thing I love about the notebook style is that you can include all of those data definition and data manipulation statements that you would typically have stored in some kind of schema or script file, and now they are stored in a user-friendly format where you can save the results of queries on the data and visualize the results in a variety of ways including graph layout and various types of charts. You can include markdown documentation in these notebooks to add color commentary to the story that your data is telling. Your audience can then re-run your queries, create their own queries and visualizations right in their own copy of your notebook.
#1 DataStax Managed Cloud lets you focus on your applications instead of managing infrastructure
As I mentioned previously, teams can get a lot of operational simplicity from using OpsCenter and the automated services it provides. Even so, I’ve seen organizations struggle to maintain operational expertise on staff to keep their clusters in good working condition over time. The challenge only increases as you add other technologies to your data platform.
What if you could focus your efforts on building great applications on top of a Cassandra-based data platform rather than maintaining infrastructure? This is now a possibility with DataStax Managed Cloud. DataStax Managed Cloud provides DataStax Enterprise as a white glove managed service, including support in defining your data models and tuning your application. The initial roll-out of this is to customers on AWS, but we’ll be offering service on Microsoft Azure and Google Cloud Platform as well.
So, that's the list. I hope that this has inspired you to check out a feature of DataStax Enterprise that you didn't know about before, or always wanted to try.
#5 Get fast, complex searches with DSE Search
#4 Get Real-time and operational insight with DSE Analytics
#3 Explore new horizons with DSE Graph
#2 Let your data tell its own story with DataStax Studio
#1 DataStax Managed Cloud lets you focus on your applications instead of managing infrastructure
More Company
View All


Introducing Tejas Kumar, Developer Relations Engineer
