What is a vector database?
A vector database is a database designed to store and query high-dimensional vectors, aiding in AI processes by enabling vector search capabilities.
Vector databases offer a specialized solution for managing high-dimensional data, essential for AI's contextual decision-making. But how exactly do they accomplish this?
A vector database is a specialized storage system designed to efficiently handle and query high-dimensional vector data, commonly used in AI and machine learning applications for fast and accurate data retrieval.
With the rapid adoption of AI and the innovation that is happening around Large Language Models we need, at the center of all of it all, the ability to take large amounts of data, contextualize it, process it, and enable it to be searched with meaning. Generative AI processes and applications that are being built to natively incorporate Generative AI functionality all rely on the ability to access Vector Embeddings, a data type that provides the semantics necessary for AI to have a similar long-term memory processing to what we have, allowing it to draw on and recall information for complex task execution.
Vector embeddings are the data representation that AI models (such as Large Language Models) use and generate to make complex decisions. Like memories in the human brain there is complexity, dimension, patterns, and relationships that all need to be stored and represented as part of the underlying structures which makes all of this difficult to manage. That is why, for AI workloads, we need a purpose-built database (or brain), designed for highly scalable access and specifically built for storing and accessing these vector embeddings.
Vector databases like Datastax Astra DB (built on Apache Cassandra) are designed to provide optimized storage and data access capabilities specifically for embeddings. A vector database is a type of database that is specifically designed to store and query high-dimensional vectors. Vectors are mathematical representations of objects or data points in a multi-dimensional space, where each dimension corresponds to a specific feature or attribute.
This is ultimately where the strength and power of a vector database lies. It is the ability to store and retrieve large volumes of data as vectors, in a multi-dimensional space that ultimately enables vector search which is what AI processes use to provide the correlation of data by comparing the mathematical embedding, or encoding, of the data with the search parameters and returning a result that is on the same path with the same trajectory as the query. This allows for a much broader scope result compared to traditional keyword searches and can take into account significantly more data as new data is added or learned.
Probably the most well known example of this is a recommendation engine that takes the users query and provides a recommendation to them of other content they are likely to be interested in. Let’s say I am watching my favorite streaming service and I am watching a show that is themed around Scifi Westerns. With Vector search I can easily and quickly recommend other shows or movies that are nearest neighbor matches using vector search on the entire media library without having to label every piece of media with a theme, in addition I will likely get other nearest neighbor results for other themes I may not have been specifically querying but have relevance to the my viewing patterns based on the show I am interested in.
Unlike a Vector Index, that only improves search and retrieval of vector embeddings, a vector database offers a well-known approach to managing large volumes of data at scale while being built specifically to handle the complexity of vector embeddings. Vector databases bring all the power of a traditional database with the specific optimizations for storing vector embeddings while providing the specialization needed for high-performance access to those embeddings that traditional scalar and relational databases lack, ultimately vector databases natively enable that ability to store and retrieve large volumes of data for vector search capabilities.
One of the primary values a database brings to application development is the ability to organize and categorize data efficiently for us by those applications. As stated above, vector databases are at the foundation of building generative AI applications because they enable vector search capabilities. When machine learning was in its infancy the data used by LLMs was typically small and finite, but as generative AI has become mainstream, the amount of data used to train and augment learning has grown exponentially. This is why vector databases are so important, they simplify fundamental operations for generative AI apps by storing large volumes of data in the structure that generative AI applications need for optimized operations.
There are many other applications benefits vector databases provide, but the key benefits are that vector databases provide the ability to store, retrieve and interact with the large datasets generative AI applications need in a natural way.
For generative AI to function, it needs a brain to efficiently access all the embeddings in real-time to formulate insights, perform complex data analysis, and make generative predictions of what is being asked. Think about how you process information and memories, one of the major ways we process memories is by comparing memories to other events that have happened. For example we know not to stick our hand into boiling water because we have at some point in the past been burned by boiling water, or we know not to eat a specific food because we have memories of how that type of food affected us. This is how vector databases work, they align data (memories) to be for fast mathematical comparison so that generic AI models can find the most likely result. Things like chatGPT for example need the ability to compare what logically completes a thought or sentence by quickly and efficiently comparing all the different options it has for a given query and presenting a result that is highly accurate and responsive.
The challenge is that generative AI cannot do this with traditional scalar and relational approaches, they are too slow, too rigid and too narrowly focused. Generative AI needs a database built to store the mathematical representation it’s brain is designed to process and offer extreme performance, scalability, and adaptability to make the most of all the data it has available, it needs something designed to be more like the human brain with the ability to store memory engrams and to rapidly access and correlate and process those engrams on demand.
With a vector database, we have the ability to rapidly load and store events as embeddings and use our vector database as the brain that powers our AI models, providing contextual information, long-term memory retrieval, semantically-like data correlation, and much much more.
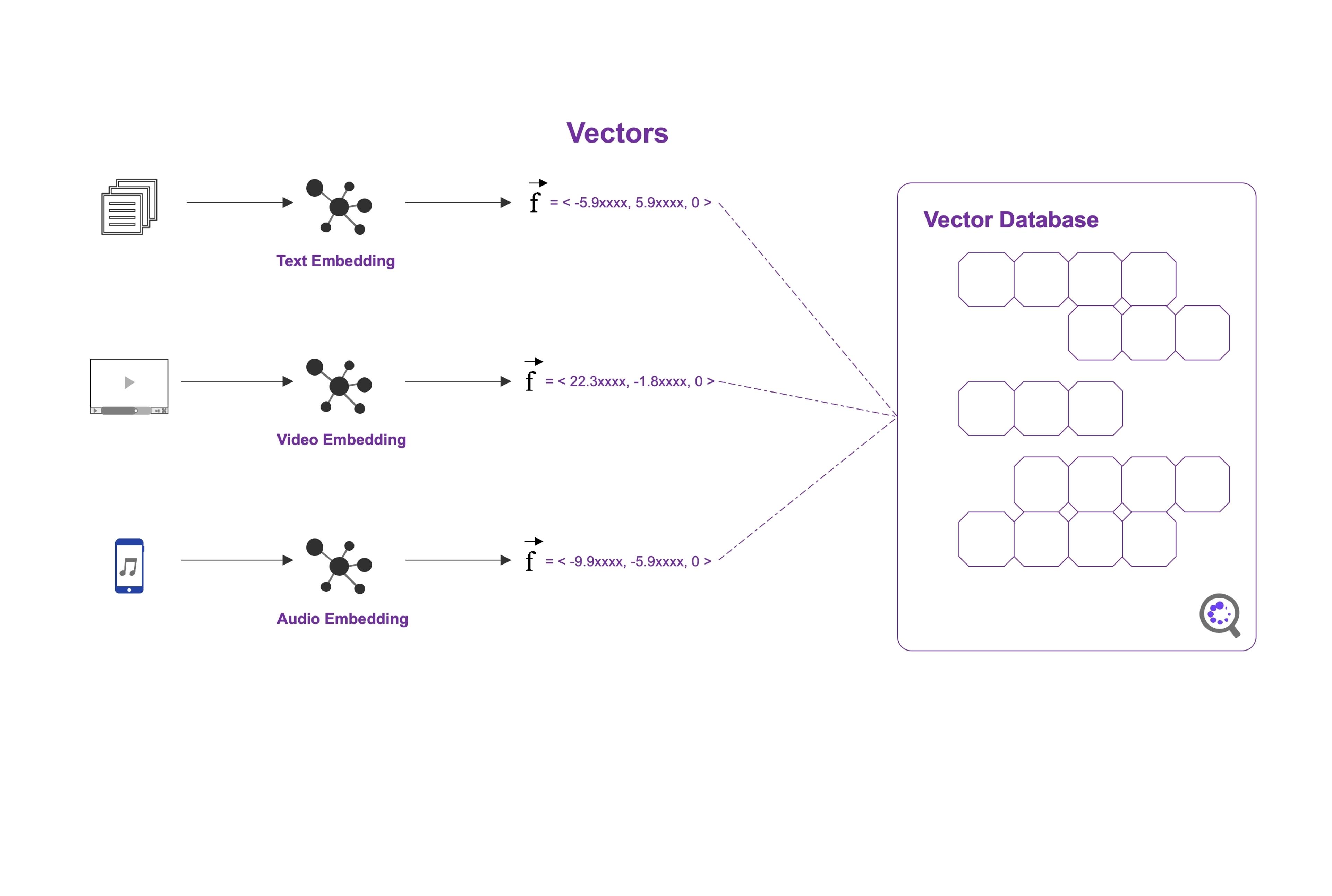
To enable efficient similarity search, vector databases employ specialized indexing structures and algorithms, such as tree-based structures (e.g., k-d trees), graph-based structures (e.g., k-nearest neighbor graphs), or hashing techniques (e.g., locality-sensitive hashing). These indexing methods help organize and partition the vectors in a way that facilitates fast retrieval of similar vectors.
In a vector database, the vectors are typically stored along with their associated metadata, such as labels, identifiers, or any other relevant information. The database is optimized for efficient storage, retrieval, and querying of vectors based on their similarity or distance to other vectors.
The most common way of thinking about this is that there are 3 steps to how a vector database works:
Looking at why vector databases are so important, one of the primary reasons is that they enhance the capabilities of generative AI models when used at the core of a retrieval augmented generation architecture. In short, retrieval augmented generation (RAG) architectures provide generative AI applications with the extended ability to not only generate new content but use the storage and retrieval systems to incorporate contextual information from pre-existing datasets. Because generative AI applications only get better with the more information they can access, the pre-existing datasets tend to be fairly large in scale and distributed across multiple different applications/locations.
This is where a vector database becomes an essential asset in implementing a RAG architecture for generative AI applications because it simplifies a number of things required by RAG:
One of the questions that gets asked a lot is do I even need a vector database, and for small workloads you probably don’t. But, if you are looking to leverage your data across applications and build generative AI applications that meet a number of different use cases, having a common repository for storage and retrieval of information for those application use cases provides a more seamless interaction with a data first approach.
One of the most common use cases for a vector database is in providing similarity or semantic search capabilities, because it provides a native ability to encode, store and retrieve information based on how it relates to the data around it. By using a vector database to store your corpus of data, applications can gain access to not just how the data relates to other data but how it is semantically similar or different from all the other data within the system. Compared to traditional approaches that use keywords or key value pairings a vector database provides the ability to compare information based on high-dimensional vectors providing 1000s of more points of comparison.
Storing your data in a vector database also provides extensibility to machine learning or deep learning applications. Probably the most common implementation of this is building chatbots that use natural language processing to provide a more natural interaction. From customer information to product documentation, leveraging a vector database to store all of the relevant information provides machine learning applications with the ability to store, organize and retrieve information from transferred learning and allows for more efficient fine-tuning of pre-trained models.
Leveraging a vector database for generative AI applications and large language models (LLMs), like other use cases, provides the foundation by providing storage and retrieval of large corpuses of data for semantic search. Beyond that however, leveraging a vector database provides for content expansion allowing for LLMs to grow beyond the original pre-trained data. In addition, a vector database provides the added abilities of providing dynamic content retrieval and the ability to incorporate multi-model approaches where applications can bring together text and image modalities for increased engagement.
Another area where vector databases have superior value is in building recommendation engines. While recommendation engines have been mainstream for a significant time, leveraging a vector database provides exponentially more paths where recommendations can be made. Previous models for recommendation engines used keyword and relational semantics, but with a vector database recommendations can be made on high-dimensional semantic relationships leveraging hierarchical nearest neighbor searching to provide the most relevant and timely information.
The use cases for vector databases are pretty vast but a lot of that is due to how a vector database is really the next evolution of how we store and retrieve data.
Unlike a traditional database that stores multiple standard data types like strings, numbers, and other scalar data types in rows and columns, a vector database introduces a new data type, a vector, and builds optimizations around this data type specifically for enabling fast storage, retrieval and nearest neighbor search semantics. In a traditional database, queries are made for rows in the database using either indexes or key-value pairs that are looking for exact matches and return the relevant rows for those queries. Traditional relational databases were optimized to provide vertical scalability around structure data while traditional NOSQL databases were built to provide horizontal scalability for unstructured data. Solutions like Apache Cassandra, have been built to provide optimizations around both structured and unstructured data and with the addition of features to store vector embeddings solutions like Datastax Astra DB are ideally suited for traditional and AI based storage models.
One of the biggest differences with a vector database is that traditional models have been designed to provide exact results but with a vector database data is stored as a series of floating point numbers and searching and matching data doesn’t have to be an exact match but can be an operation of finding the most similar results to our query. Vector databases use a number of different algorithms that all participate in Approximate Nearest Neighbor (ANN) search and allow for large volumes of related information to be retrieved quickly and efficiently. This is where a purpose-built vector database, like DataStax Astra DB provides significant advantages for generative AI applications. Traditional databases simply cannot scale to the amount of high-dimensional data that needs to be searched. AI applications need the ability to store, retrieve, and query data that is closely related in a highly distributed, highly flexible solution.
Vector databases offer several key benefits that make them highly valuable in various gen-AI applications, especially those involving complex and large-scale data analysis. Here are some of the primary advantages:
Vector databases are specifically designed to manage high-dimensional data efficiently. Traditional databases often struggle with the complexity and size of these datasets, but vector databases excel in storing, processing, and retrieving data from high-dimensional spaces without significant performance degradation.
One of the most significant advantages of vector databases is their ability to perform similarity and semantic searches. They can quickly find data points that are most similar to a given query, which is crucial for applications like recommendation engines, image recognition, and natural language processing.
Vector databases have to be highly scalable, capable of handling massive datasets without a loss in performance. This scalability is essential for businesses and applications that generate and process large volumes of data regularly.
They offer faster query responses compared to traditional databases, especially when dealing with complex queries in large datasets. This speed does not come at the cost of accuracy, as vector databases can provide highly relevant results due to their advanced algorithms. For more information on speed and accuracy please see GigaOm's Report on vector database performance comparisons.
Vector databases are particularly well-suited for AI and machine learning applications. They can store and process the data necessary for training and running machine learning models, particularly in fields like deep learning and natural language processing.
By enabling complex data modeling and analysis, vector databases allow organizations to gain deeper insights from their data. This capability is crucial for data-driven decision-making and predictive analytics.
These databases support the development of personalized user experiences by analyzing user behavior and preferences. This is particularly useful in marketing, e-commerce, and content delivery platforms where personalization can significantly enhance user engagement and satisfaction.
One of the biggest benefits vector databases bring to AI is the ability to leverage existing models across large datasets by enabling efficient access and retrieval of data for real-time operations. A vector database provides the foundation for memory recall, the same memory recall we use in our organic brain. With a vector database, artificial intelligence is broken into cognitive functions (Large Language Models), memory recall (Vector Databases), specialized memory engrams and encodings (Vector Embeddings), and neurological pathways (Data Pipelines).
Working together, these processes enable artificial intelligence to learn, grow and access information seamlessly. The vector database holds all of the memory engrams and provides the cognitive functions with the ability to recall information that triggers similar experiences. Just like our human memory when an event occurs our brain recalls other events that invoke the same feelings of joy, sadness, fear or hope.
With a vector database generative AI processes have the ability to access large sets of data, correlate that data in a highly efficient way, and use that data to make contextual decisions on what comes next, and when tapped into a nervous system, data pipelines, that allows for new memories to be store and accessed as they are being made, AI models have the power to learn and grow adaptively by tapping into workflows that provide history, analytics or real-time information.
Whether you are building a recommendation system, an image processing system, or anomaly detection, at the core of all these AI functionalities you need a highly efficient, optimized vector database, like Astra DB. Astra DB is designed and built to power the cognitive process of AI that can stream data as data pipelines from multiple sources, like Astra streaming, and uses those to grow and learn to provide faster, more efficient results.
With the rapid growth and acceleration of generative AI across all industries we need a purpose-built way to store the massive amount of data used to drive contextual decision-making. Vector databases have been purpose-built for this task and provide a specialized solution to the challenge of managing vector embeddings for AI usage. This is where the true power of a vector database derives, the ability to enable contextual data both at rest and in motion to provide the core memory recall for AI processing.
While this may sound complex, Vector Search on AstraDB takes care of all of this for you with a fully integrated solution that provides all of the pieces you need for contextual data. From the nervous system built on data pipelines to embeddings all the way to core memory storage and retrieval, access, and processing in an easy-to-use cloud platform. Try for free today.
A vector database is a database designed to store and query high-dimensional vectors, aiding in AI processes by enabling vector search capabilities.
Vector databases facilitate real-time access to vector embeddings, enabling efficient data comparison and retrieval for generative AI models. By organizing vectors in a way that facilitates fast retrieval of similar vectors, they support AI in generating insights and predictions.
They provide optimized storage and retrieval of vector embeddings, boosting AI functionalities like recommendation systems and anomaly detection. For instance, they can power recommendation engines that suggest content based on users' queries and preferences.
Unlike traditional databases, vector databases store data in a mathematical representation called vectors, enabling approximate nearest neighbor (ANN) search for similar results. This feature enhances search and matching operations, making them more suited for AI applications.
Some of the main advantages are that they enable fast storage, retrieval, and nearest neighbor search semantics, which is especially beneficial for generative AI applications. Their structure allows for a broader scope in result retrieval compared to exact match queries in traditional databases.
They use specialized structures like k-d trees, k-nearest neighbor graphs, or locality-sensitive hashing for efficient similarity search.


