Make Decisions When You Need To: Now
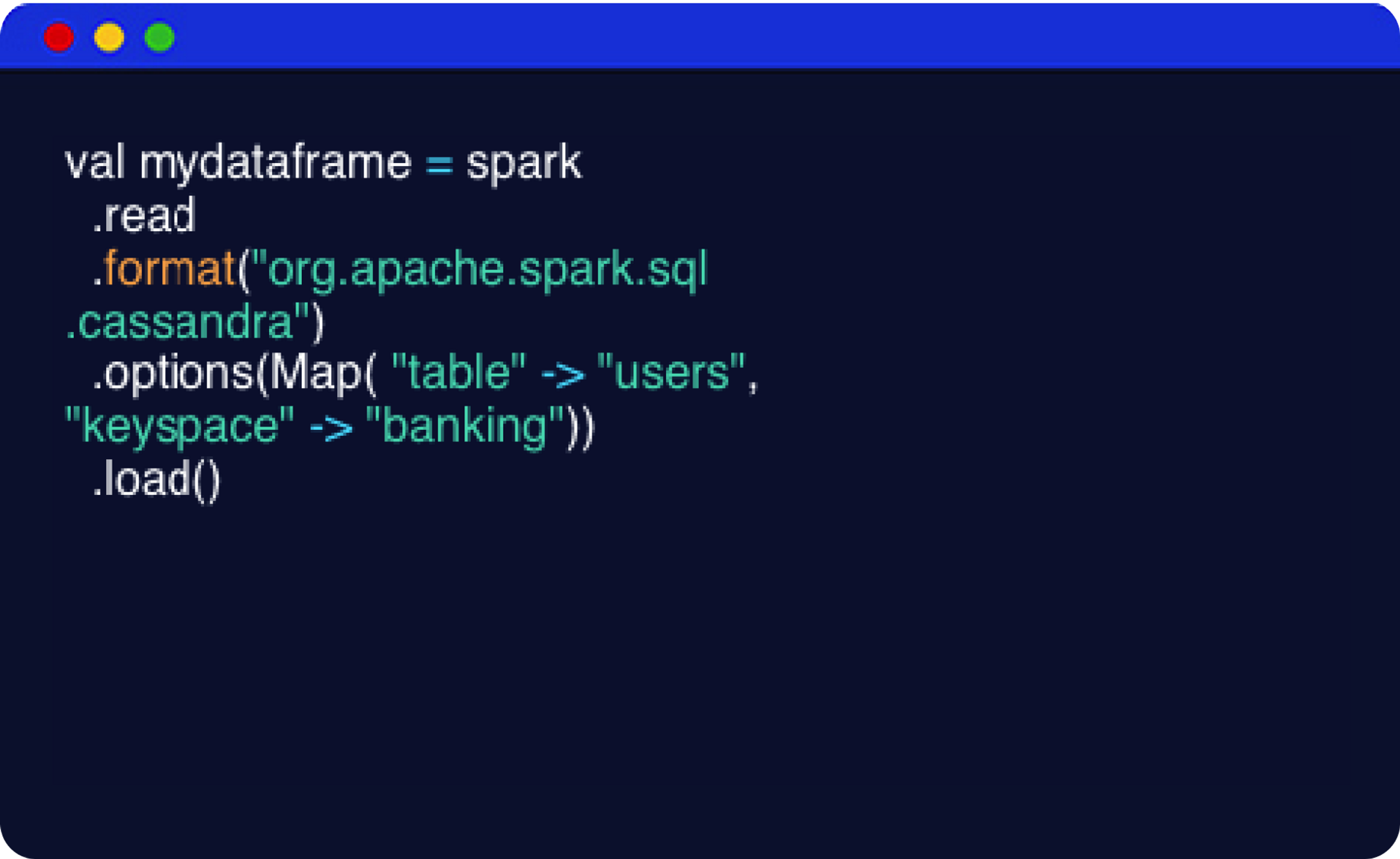
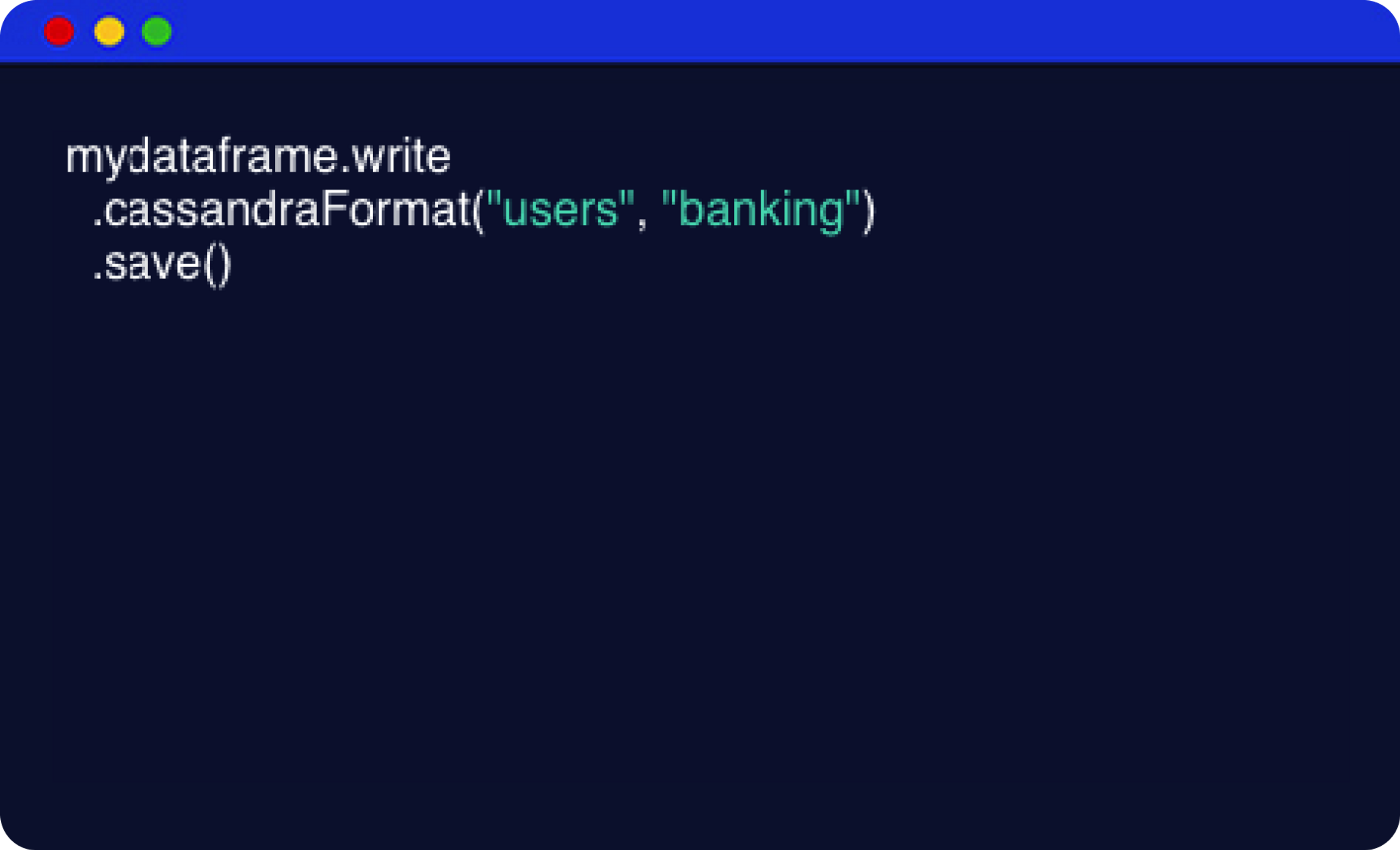
Deliver real-time analytics at scale with no single point of failure.


Create Personalized Experiences
Integrated real-time analytics, search, and graph capabilities allow you to provide context-rich experiences.

Deliver Real-Time Insights
Ingest, transform, and process data instantly, so you can derive insights to act now.

Gain A 360-Degree Customer View
Process both real-time and batch data to get a comprehensive view of your customers.